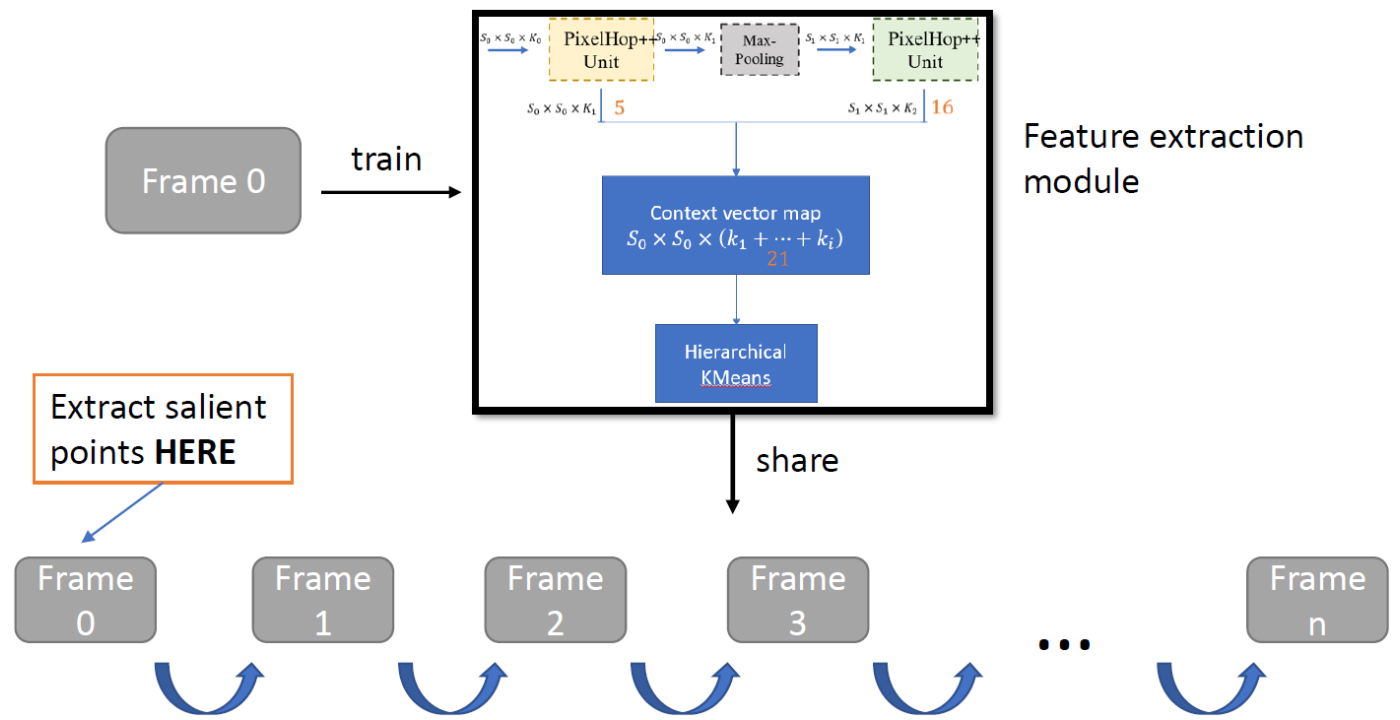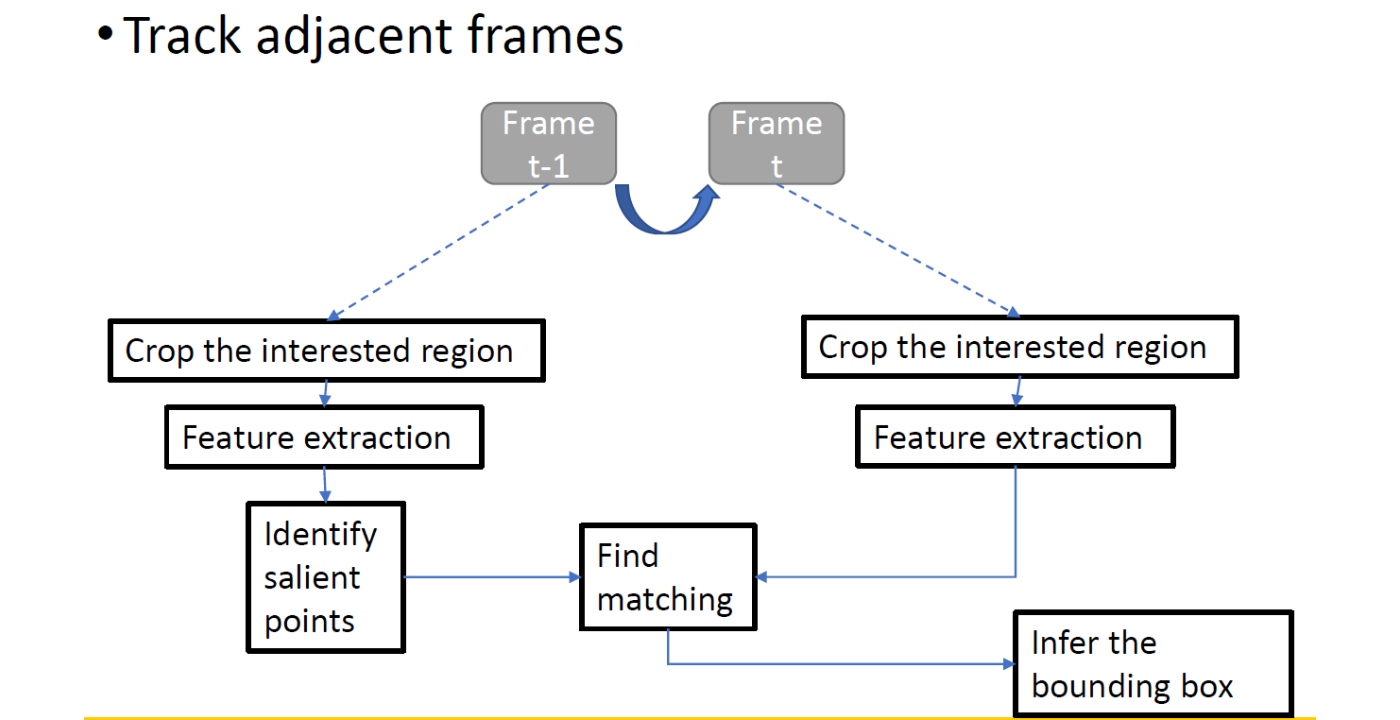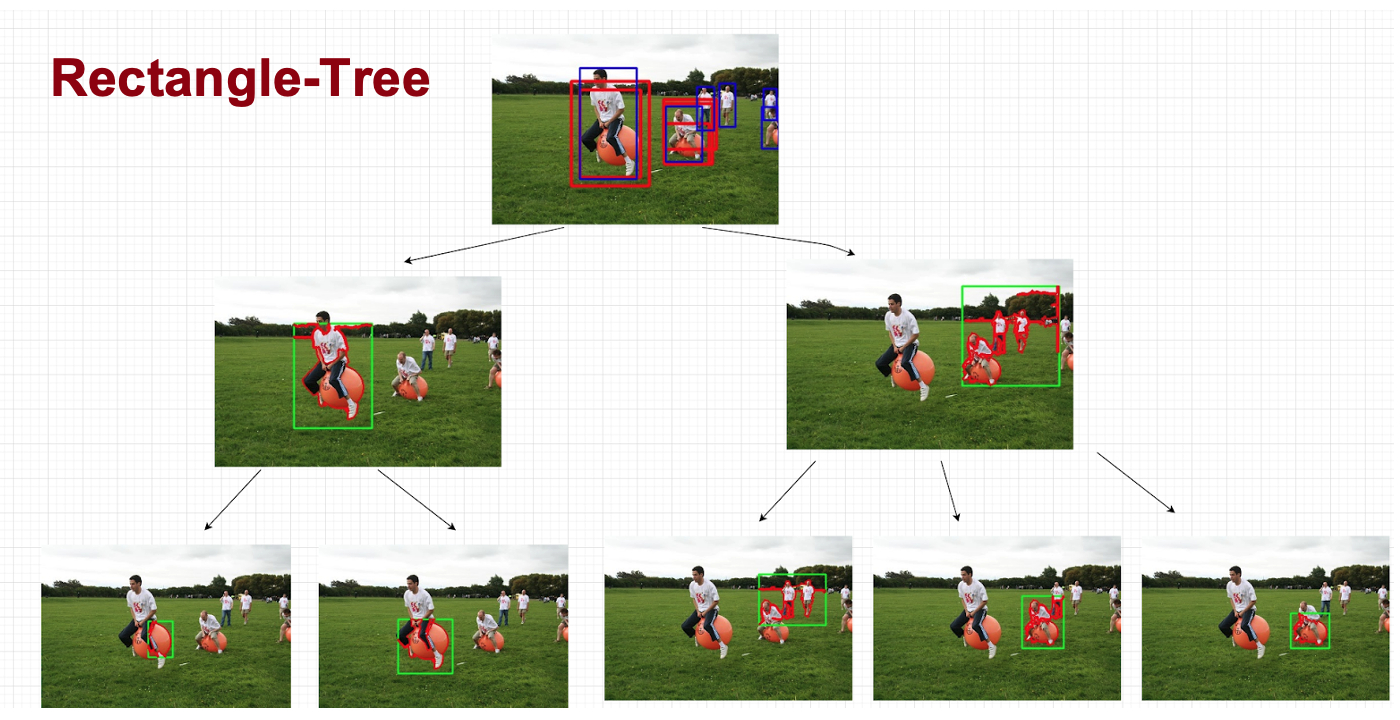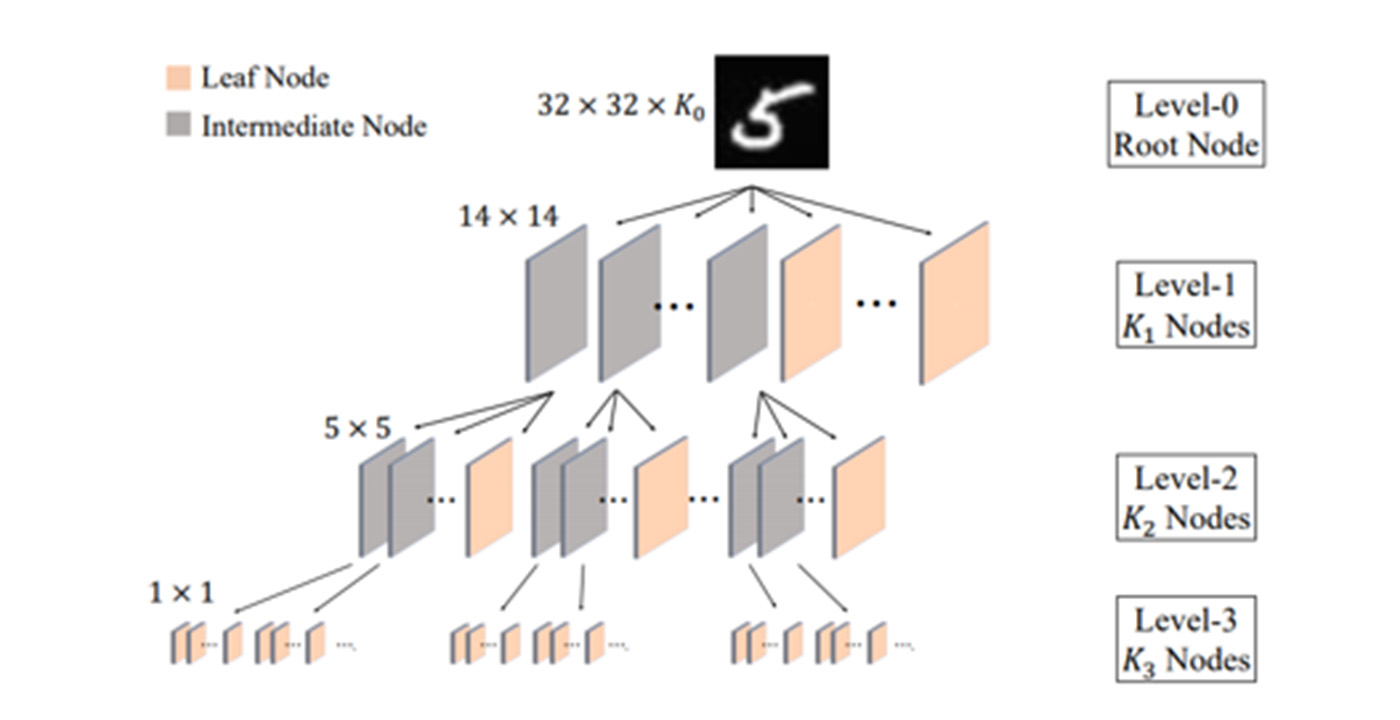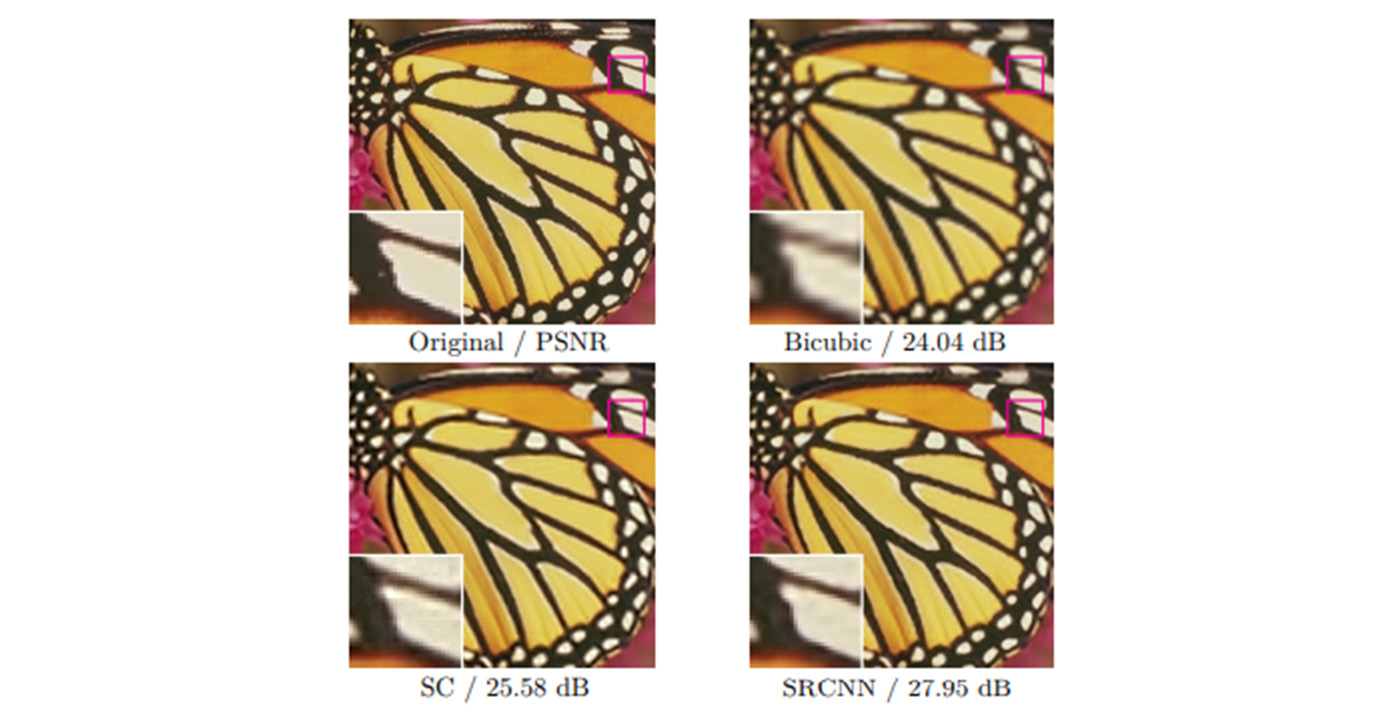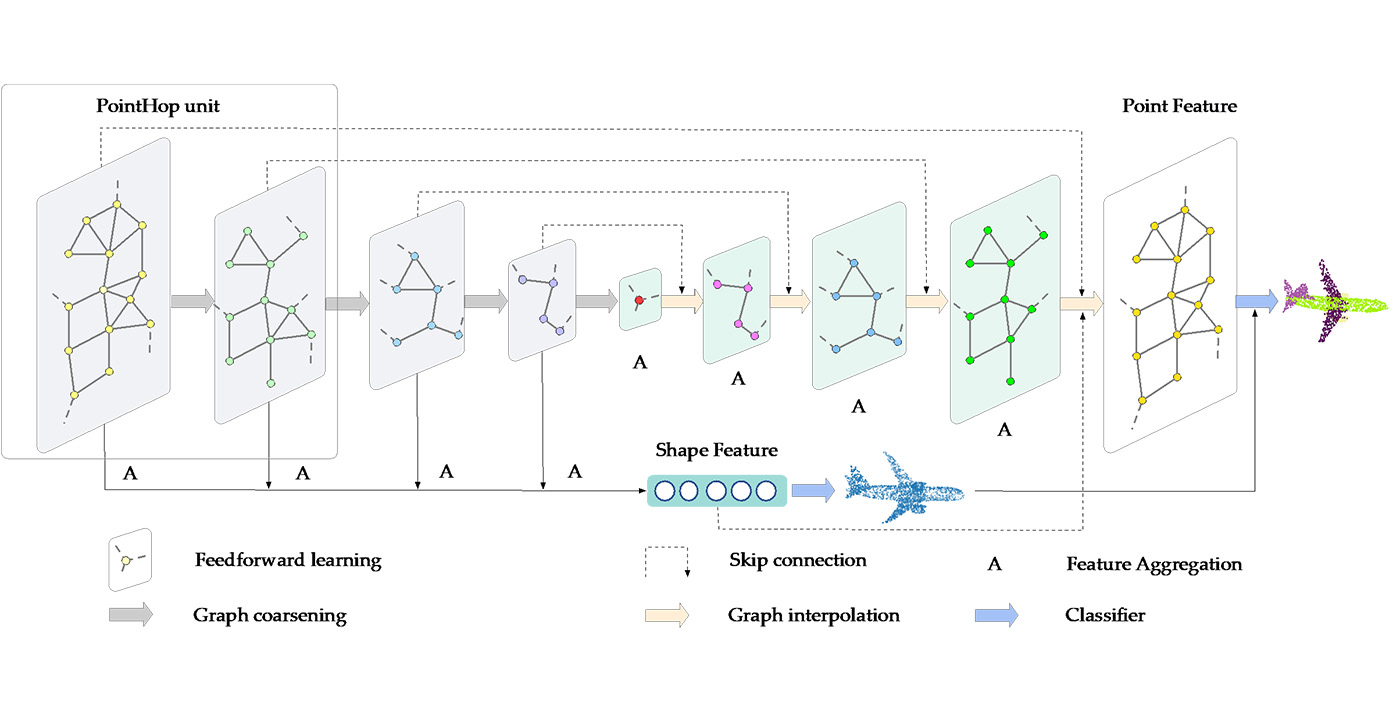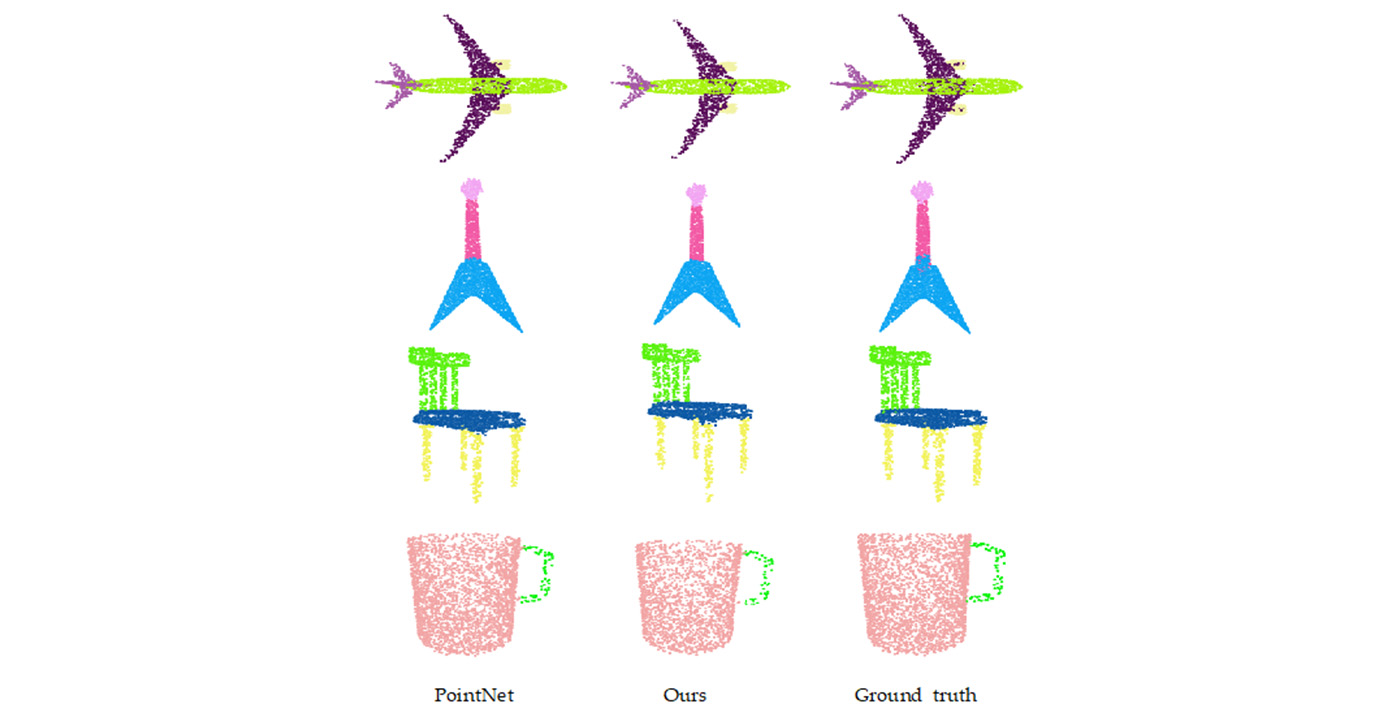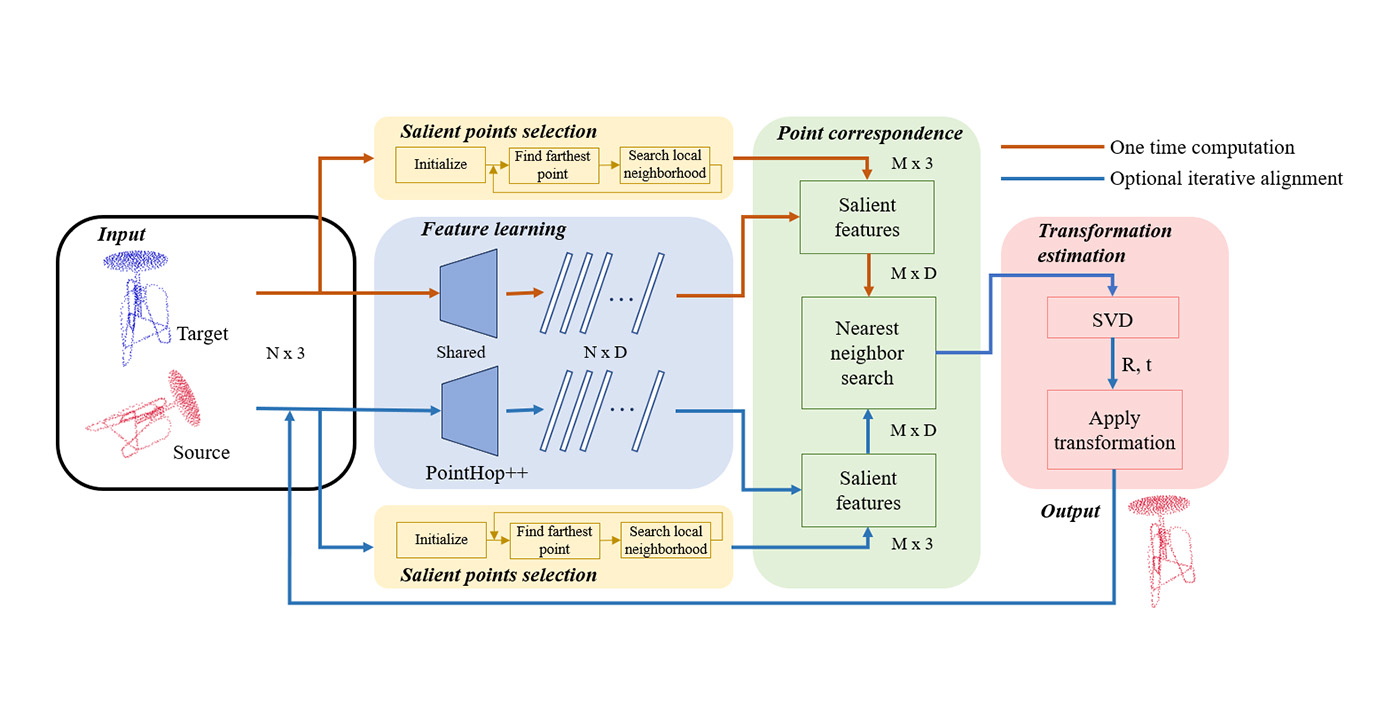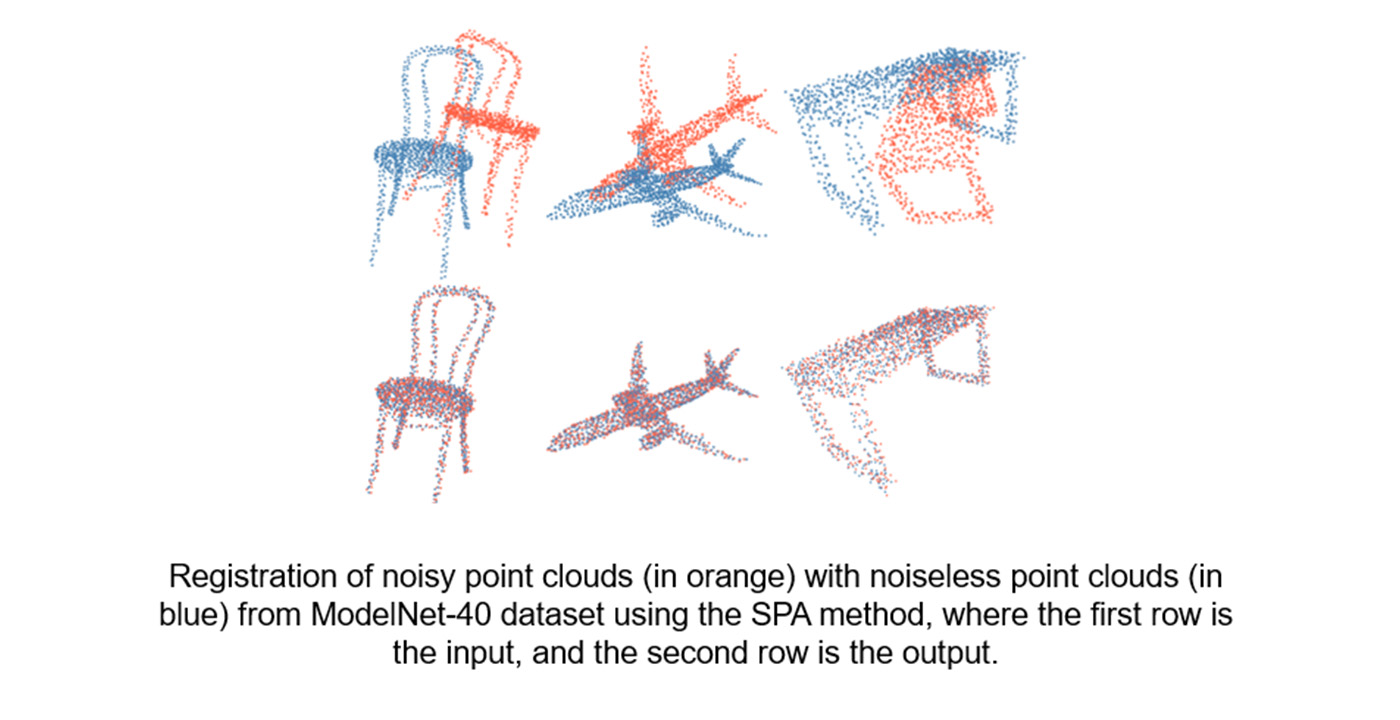
MCL Research on Natural Image Synthesis
Automatic new image synthesis based on a collection of sample images from the same class finds broad applications in computer graphics and computer vision. Examples include automatic synthesis of human faces, hand-written digits, etc. On an abstract level, a generative model learns to resemble the probability distribution of data samples and generate new samples based on the learned model. Research on generative models has attracted rich attention in the machine learning community for decades.
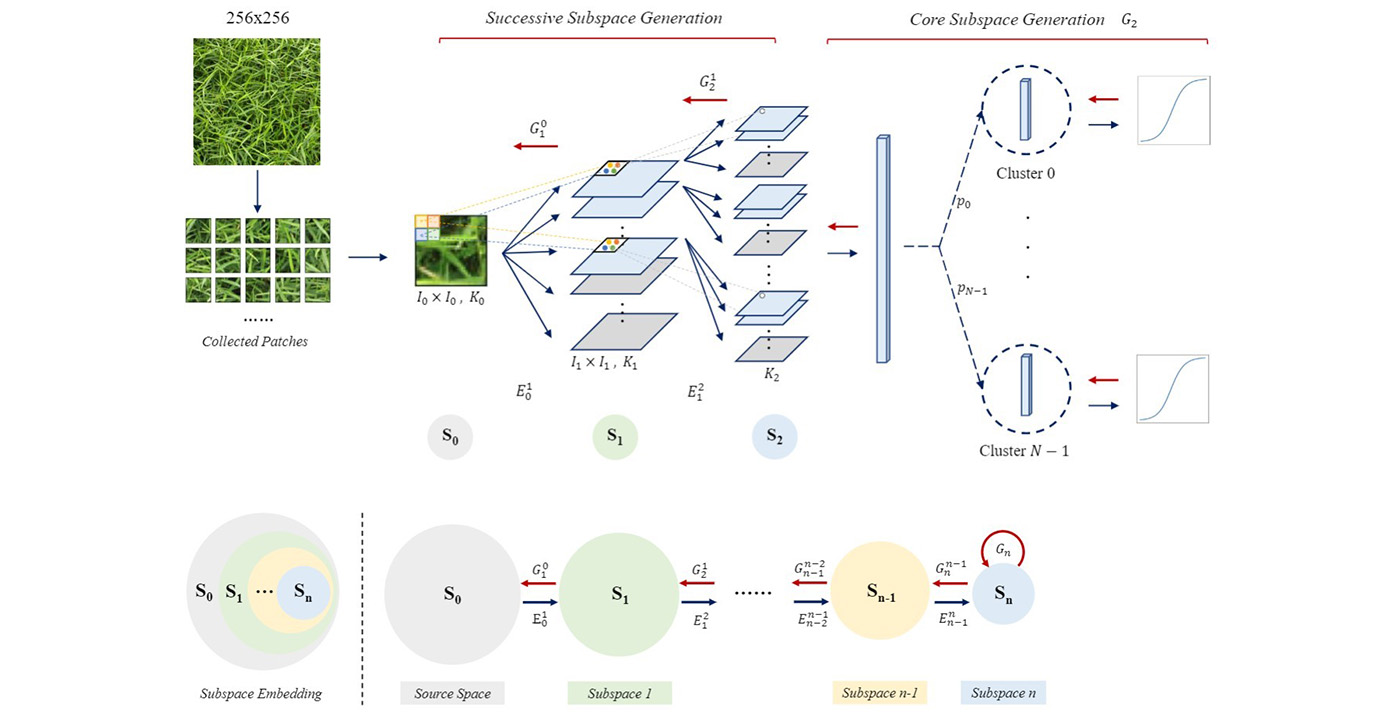
Image synthesis is challenging for two main reasons. First, it demands a sufficiently large number of images to define meaningful statistics for a target class. Second, to generate new images of similar characteristics, one should find one or more effective representations of samples and process them with a proper mechanism. There is a resurge of interests in generative models due to the performance breakthrough achieved by deep learning (DL) technologies in the last 6-7 years. There are however concerns with DL-based generative models. Built upon multi-layer end-to-end optimization, the DL technology is essentially a nonconvex optimization problem. Because of the mathematical complexity associated with nonconvex optimization, DL-based solutions are a black box. Besides, the training of DL-based generative models demands a large amount of computational resource. We propose an explainable and effective generative model to address these concerns, named Successive Subspace Generative (SSG) model.
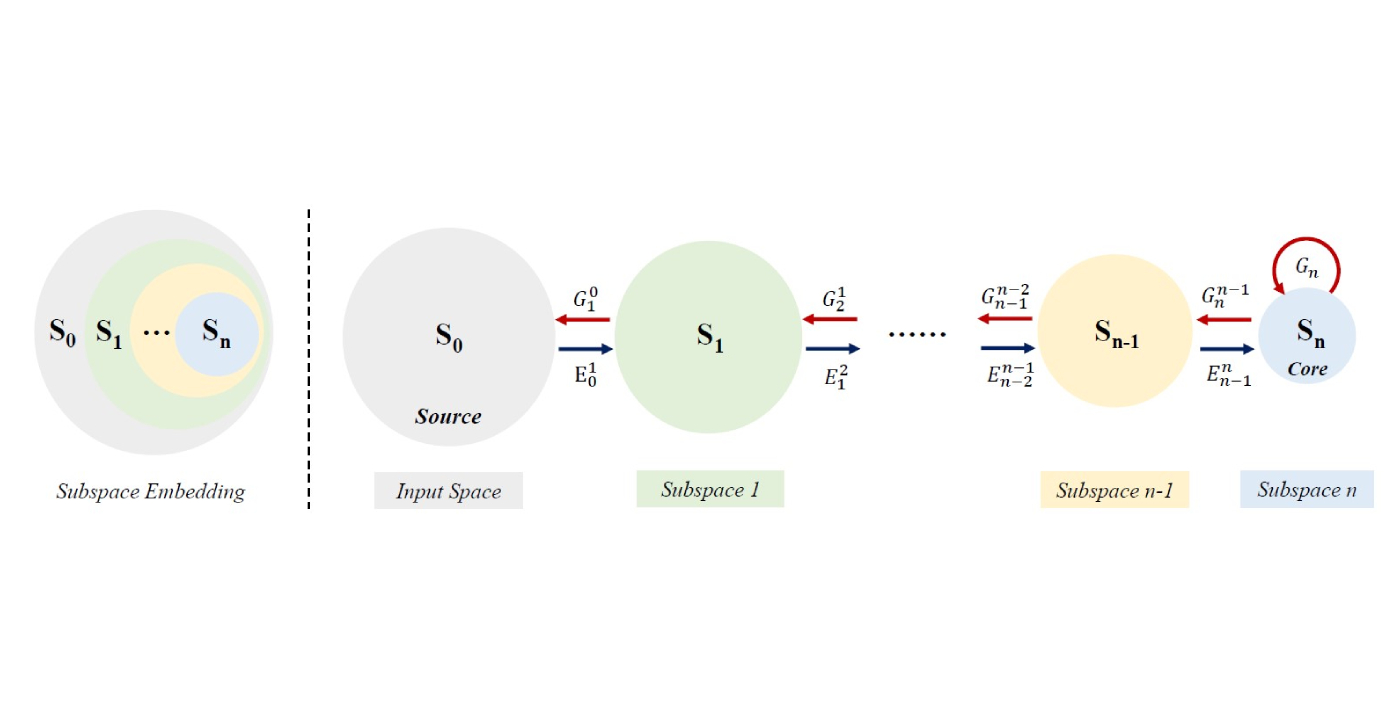
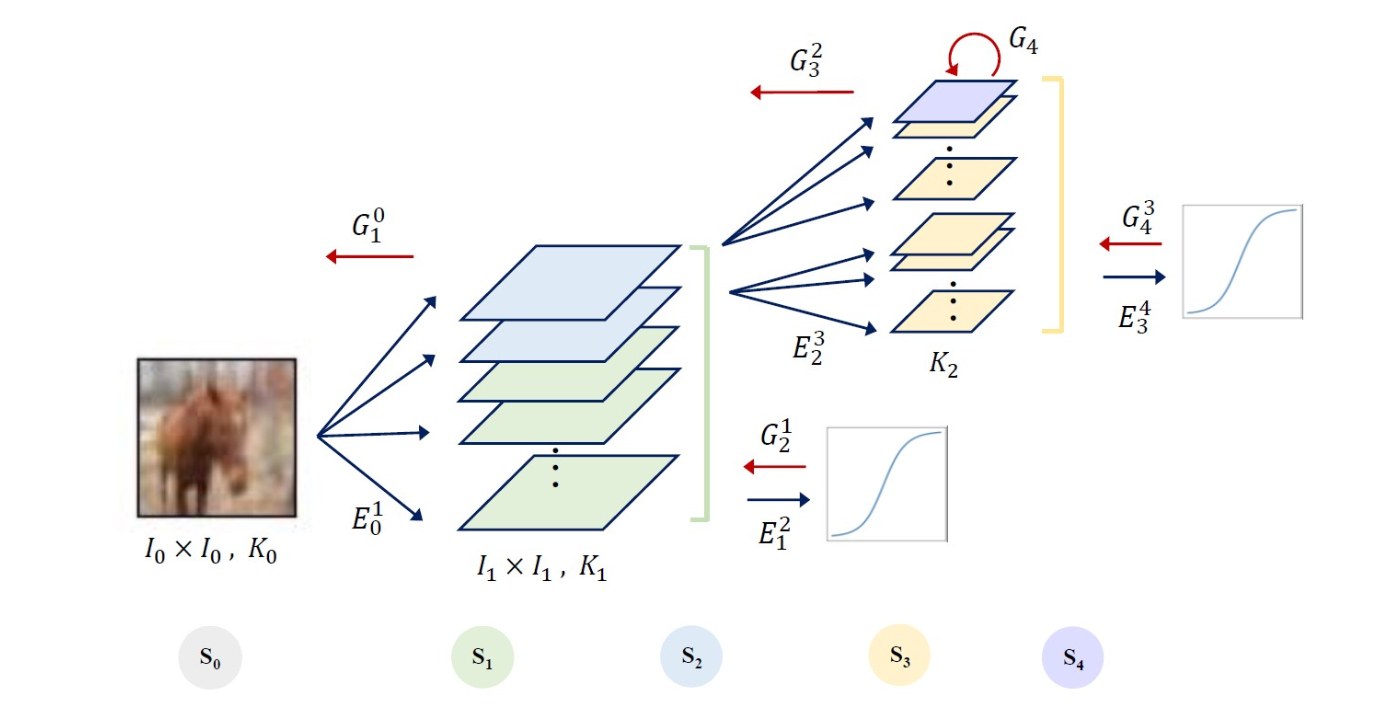
Subspaces of descending dimensions are successively constructed in a feedforward manner, which is called the embedding process. Through embedding, the sample distribution of the source and subsequent subspaces can be captured by embedding parameters and the sample distribution in the core. For generation, samples are first generated according to the learned distribution in the core. Then, they go from the core to the source by traversing the same [...]