Merry Christmas!
May your Christmas sparkle with moments of love, laughter and goodwill. And may the year ahead be full of contentment and joy. Wish all our fellows a Merry Christmas!
May your Christmas sparkle with moments of love, laughter and goodwill. And may the year ahead be full of contentment and joy. Wish all our fellows a Merry Christmas!
Trained deep learning models do not generalize well if the testing data has a different distribution from the training data set. For instance, in medical image segmentation, the MRI and CT scan of the same object look very different. If we simply train a model on the MRI scans, it is very likely that the model will not work on the CT scans. However, it is very expensive and time-consuming to manually label different data sets. Therefore, we wish to transfer the knowledge from a labeled training set to an unlabeled testing data with a different distribution. Domain adaptation can help us achieve this purpose.
Domain adaptation can be categorized into three types based on the availability of target domain data: supervised, semi-supervised, unsupervised [1]. In supervised domain adaptation, a limited amount of labeled target domain data is available. In the semi-supervised setting, unlabeled target domain data as well as a small amount of labeled target domain data is available. In the unsupervised setting, only unlabeled target domain data is available. Unsupervised domain adaptation is an ill-posed problem since we do not have labels for the target domain data. Proper assumptions on the target domain data are important for performing unsupervised domain adaptation. In our research, we focus on the unsupervised domain adaptation. Unsupervised domain adaptation can be applied to many computer vision problems, including classification, segmentation, and detection. Currently, we focus our experiment on classification.
–By Ruiyuan Lin
Reference:
[1] M. Wang and W. Deng, “Deep visual domain adaptation: A survey,” Neurocomputing, 2018.
Image Credits:
Anon, (2018). Available at: http://ai.bu.edu/visda-2018/assets/images/domain-adaptation.png [Accessed 16 Dec. 2018].
X. Peng, B. Usman, N. Kaushik, J. Hoffman, D. Wang, and K. Saenko, “Visda: The visual domain adaptation challenge,” 2017.
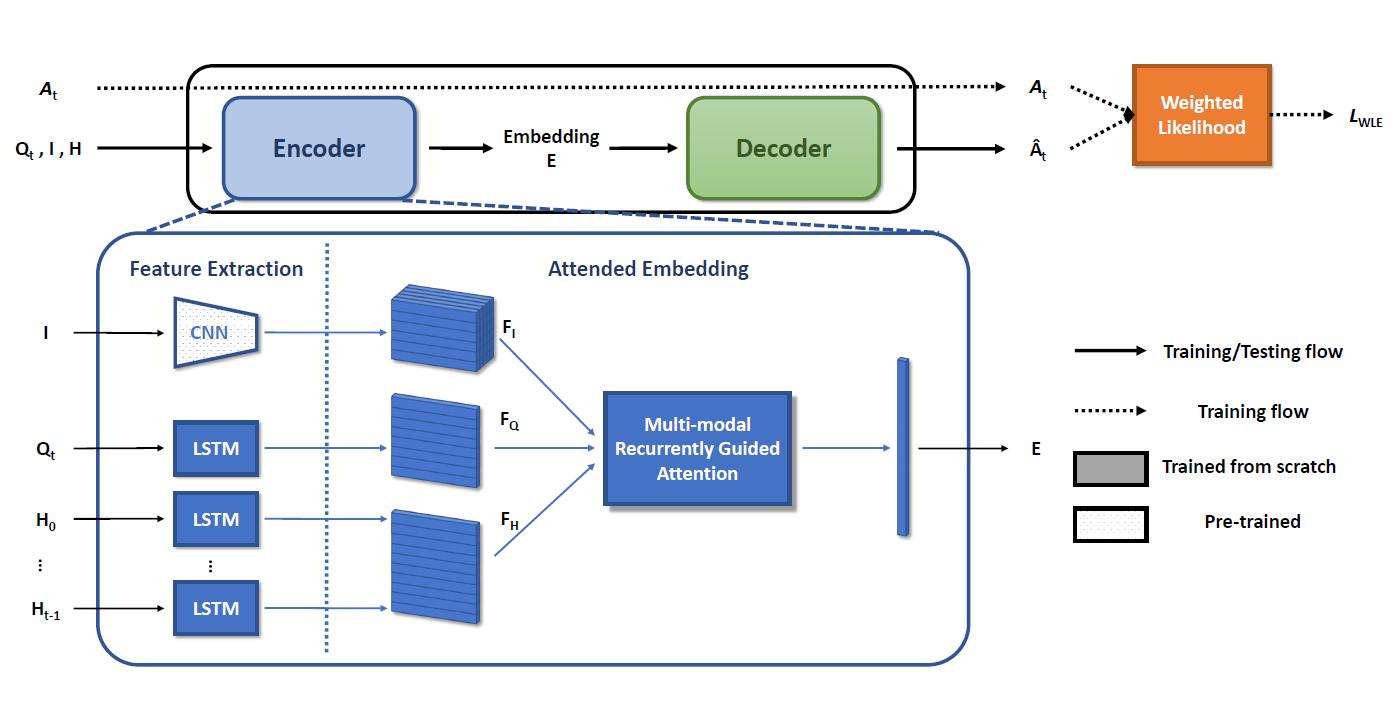
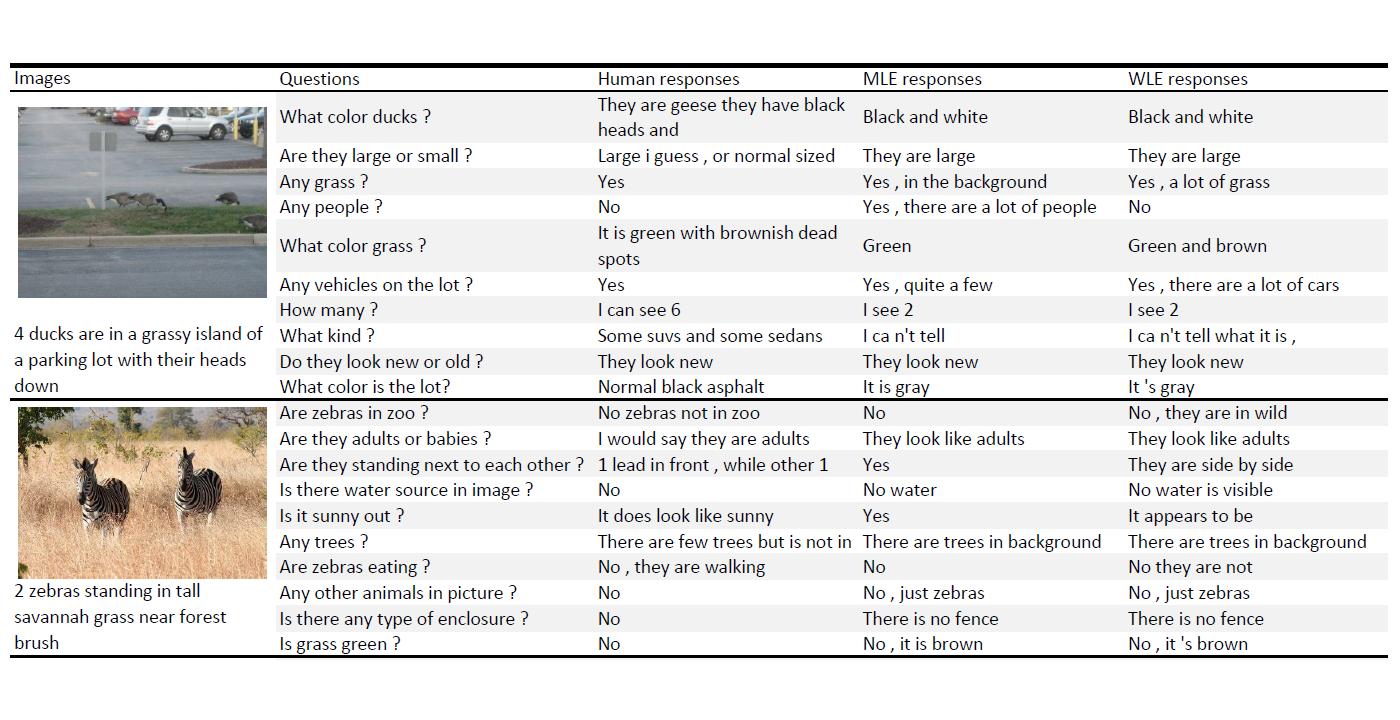
The task of Visual Dialogue involves a conversation between an agent system and a human end-user regarding visual information presented. The conversation consists of multiple rounds of questions and answers. The key challenge for the agent system is to answer the questions of human users with meaningful information while keeping the conversation flow contiguous and natural. The current visual dialogue systems can be divided into two tracks, generative models and discriminative models. The discriminative models cannot directly generate a response but choose a response out of a pool of candidate responses. Although the discriminative models have achieved surprising results, they are usually not applicable in real scenarios where no candidate response pool is available. On the other hand, the generative models can directly generate a response based on the input information. However, most generative models based on maximum likelihood estimation (MLE) approach suffer from the tendency of generating generic responses.
We present a novel approach that incorporates a multi-modal recurrently guided attention mechanism with a simple yet effective training scheme to generate high quality responses in the Visual Dialogue interaction model. Our attention mechanism combines attentions globally from multiple modalities (e.g., image, text questions and dialogue history), and refines them locally and simultaneously for each modality. Generators using typical MLE-based methods only learn from good answers, and consequently tend to generate safe or generic responses. The new training scheme with weighted likelihood estimation (WLE) penalizes generic responses for unpaired questions in the training and enables the generator to learn from poor answers as well.
On benchmark dataset, our proposed Visual Dialogue system demonstrates state-of-the-art performance with improvement of 5.81% and 5.28 on recall@10 and mean rank, respectively.
–By Heming Zhang
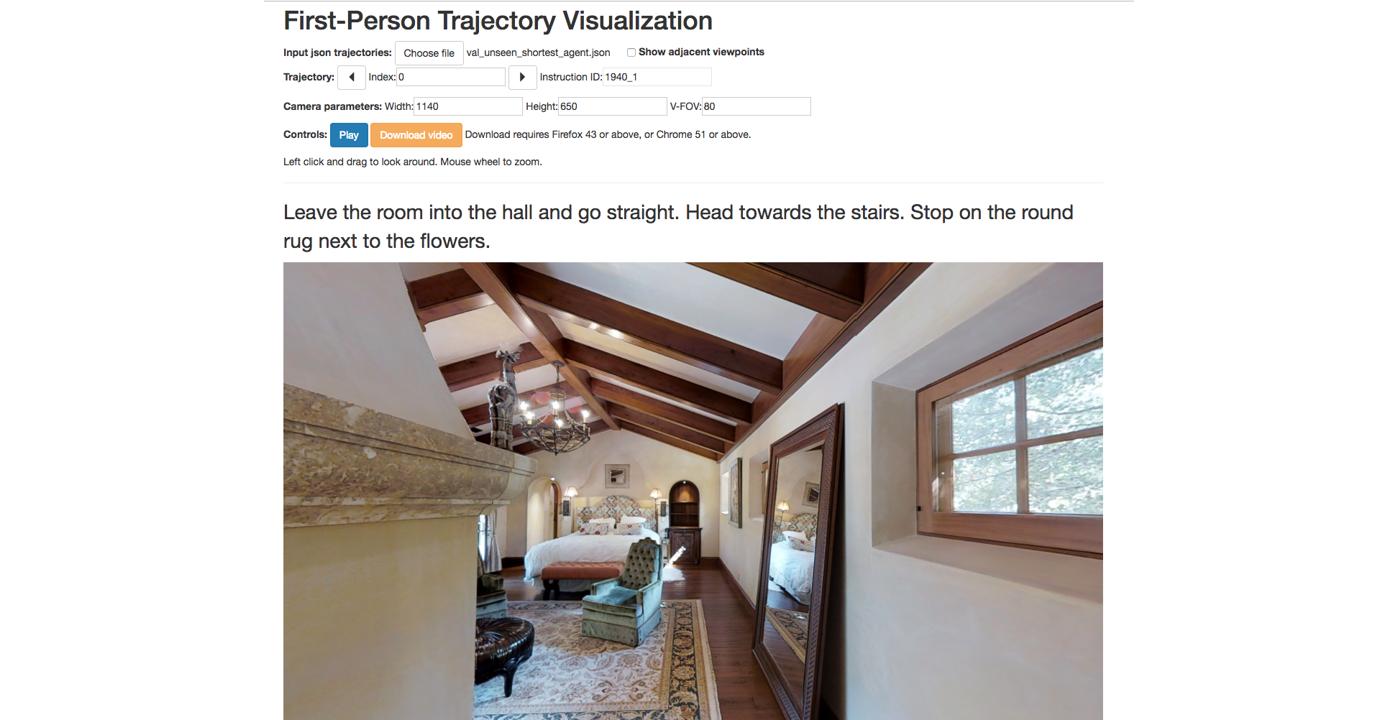
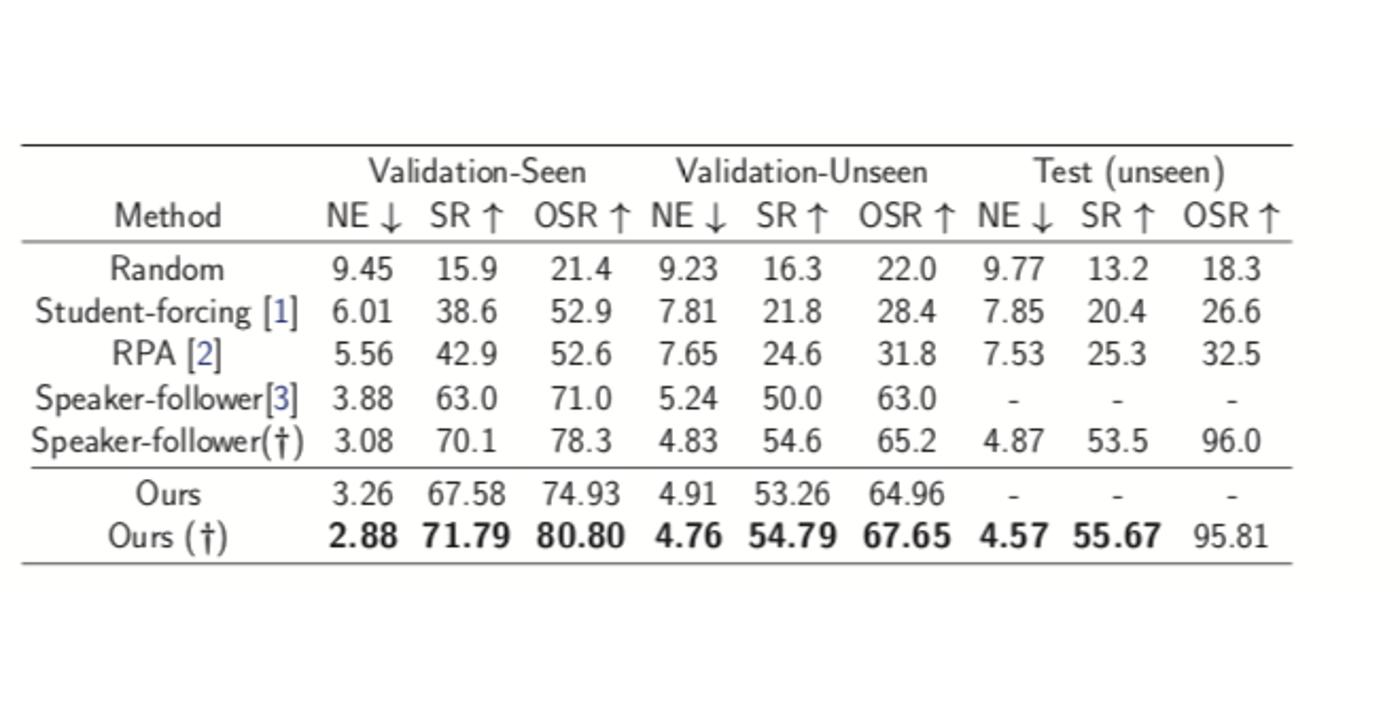
Imagine a robot navigating across rooms following human instructions: “Turn left and take a right at the table. Take a left at the painting and then take your first right. Wait next to the exercise equipment”, the agent is expected to first execute the action “turn left” and then locates “the table” before “taking a right”. However, in practice, the agent might well turn right in the middle of the trajectory before a table is observed, in which case the follow-up navigation would definitely fail. Human on the other hand, has the ability to relate visual input with language semantics. In this example, human would locate visual landmarks such as table, painting, exercise equipment before making a decision (turn right, turn left and stop). We endow our agent with similar reasoning ability by equipping our agent with a synthesizer module that implicitly aligns language semantics with visual observations. The poster is available online: https://davidsonic.github.io/summary/Poster_3d_indoor.pdf and the demonstration video is available at https://sites.google.com/view/submission-2019.
–By Jiali Duan
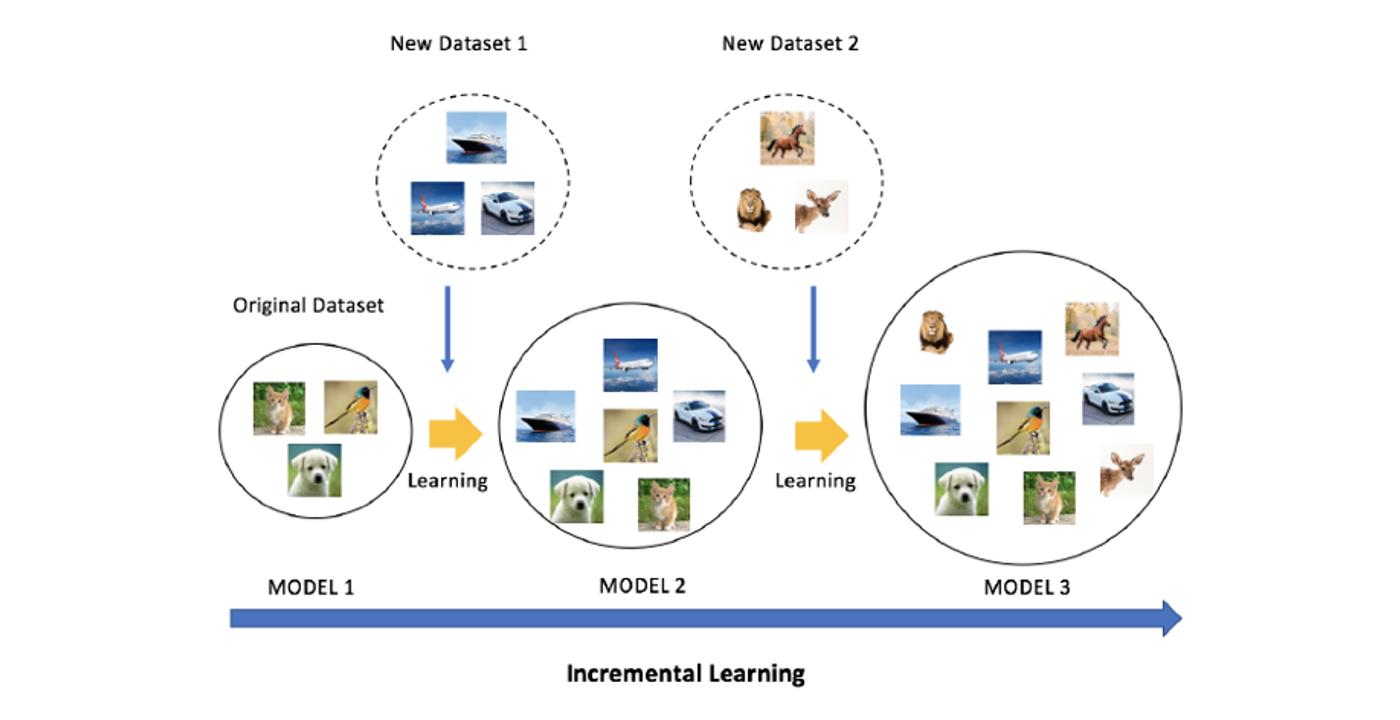
Humans can accumulate and maintain the knowledge learned from previous tasks and use it seamlessly in learning new tasks and solving new problems — learning new concepts over time is a core characteristic of human learning. Therefore, it is desirable to have a computer vision system that can learn incrementally about new classes when training data for them becomes available, as this is a necessary step towards the ultimate goal of building real intelligent machines that learn like humans.
Despite the recent success of deep learning in computer vision for a broad range of tasks, classical training paradigm of deep models is ill-equipped for incremental learning (IL). Most deep neural networks can only be trained in batch mode in which the complete dataset is given and all classes are known prior to training. However, the real world is dynamic and new categories of interest can emerge over time. Re-training a model from scratch whenever a new class is encountered is prohibitively expensive due to the huge data storage requirements and computational cost. Directly fine-tuning the existing model on only the data of new classes using stochastic gradient descent (SGD) optimization is not a better approach either, as this might lead to the notorious catastrophic forgetting effect, which refers to the severe performance degradation on old tasks.
Existing IL approaches attempting to overcome catastrophic forgetting tend to produce a model that is biased towards either the old classes or new classes, unless with the help of exemplars of the old data. To address this issue, we propose a class-incremental learning paradigm called Deep Model Consolidation (DMC), which works well even when the original training data is not available. The idea is to train a model on the [...]
On November 22, 2018, MCL members participated in the annual Thanksgiving Luncheon at Kirin Buffet. There was a wide variety of dishes and the food was very delicious. All the members enjoyed the buffet quite well, and had a wonderful time chatting with each other.
The Thanksgiving Luncheon has been a tradition of MCL for about 20 years. The whole group is like a warm and happy family gathering together. It’s also a good chance for us to have a rest after a busy semester. Thank Professor Kuo for holding this event and thank Yuhang for organizing it. Happy Thanksgiving to everyone!
Tianhorng Chang, an MCL alumnus, entered the PhD/EE program at USC in Spring 1989, passed his screening exam on December 4, 1989, and became the third PhD student of Dr. Kuo in Spring 1990. Tianhorng took his qualifying exam on May 7, 1992. He was originally scheduled to take his defense in 1993. However, he could not do it but passed away in 1994 because of cancer.
Tianhorng Chang completed 46 units at USC and transferred in another 30 units from his previous MSEE program at the University of Florida. His graduate GPA at USC was 3.93. His seminal paper titled with “Texture Analysis and Classification with Tree-Structured Wavelet Transform” published by IEEE Trans. on Image Processing (1993) received 2000 citations. Due to Tianhorng’s near-complete curriculum and impactful research, USC granted Tianhorng’s posthumous PhD degree in 2018 August.
Tianhorng received his BSEE degree from the National Tsinghua University, Taiwan, in 1983. A ceremony to award the posthumous PhD degree to Tianhorng’s family was held in the National Tsinghua University on November 18, 2018. Many of his undergraduate classmates and MCL alumni in Taiwan attended the award ceremony. During the ceremony, Professor Kuo and several participants shared their memory on Tianhorng. A video clip featuring short speeches given by Professor Richard Leahy (the current Chair of USC/EE), Professor Sandeep Gupta (the former Chair of USC/EE) and Ms. Diane Demetras was also played. Tianhorng’s younger brother received the posthumous PhD degree on behalf of his family. The whole ceremony took about 1 hour.
Professor Kuo said, “Hope this award ceremony brings some comfort to Tianhorng’s family and Tianhorng’s story will encourage a younger generation to pursuit advanced research as long as they have strong passion.”
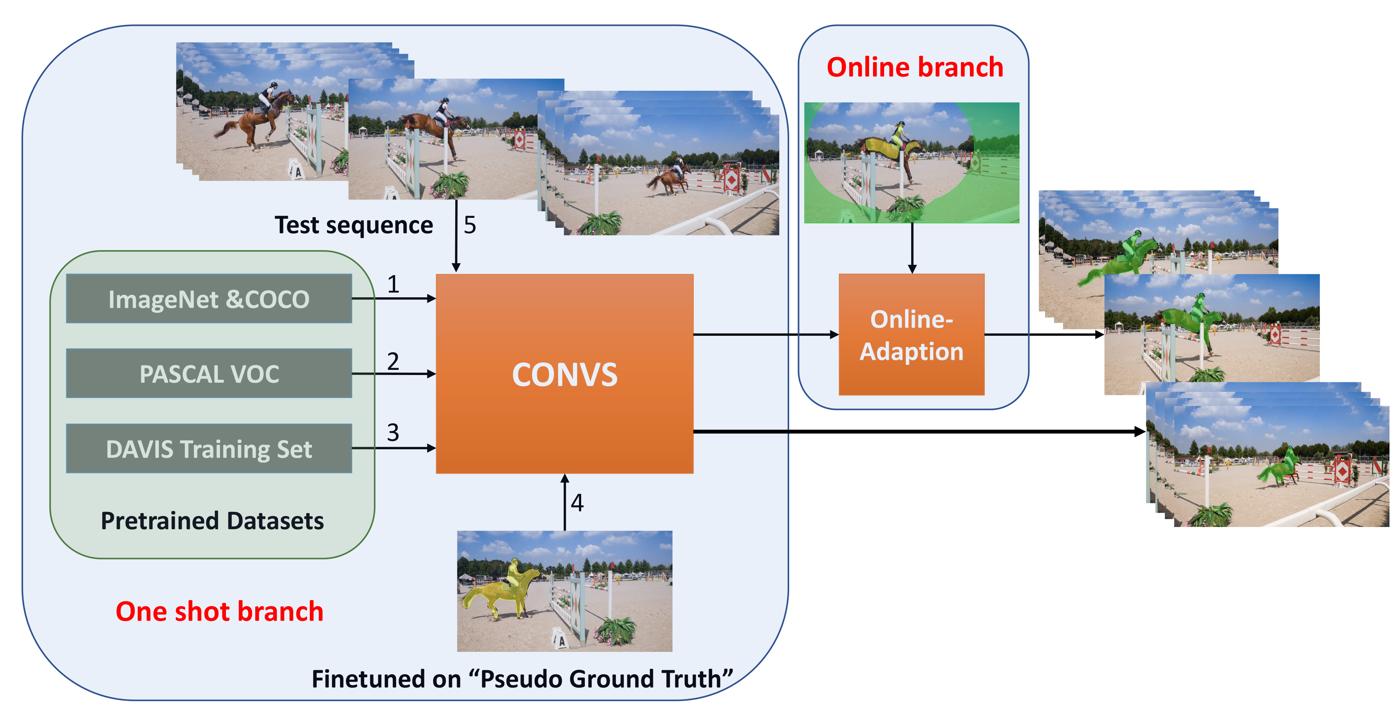
One major technique debt in video object segmentation is to label the object masks for training instances. As a result, we propose to prepare inexpensive, yet high quality pseudo ground truth corrected with motion cue for video object segmentation training. Our method conducts semantic segmentation using instance segmentation networks and, then, selects the segmented object of interest as the pseudo ground truth based on the motion information. Afterwards, the pseudo ground truth is exploited to finetune the pretrained objectness network to facilitate object segmentation in the remaining frames of the video. We show that the pseudo ground truth could effectively improve the segmentation performance. This straightforward unsupervised video object segmentation method is more efficient than existing methods. Experimental results on DAVIS and FBMS show that the proposed method outperforms state-of-the-art unsupervised segmentation methods on various benchmark datasets. And the category-agnostic pseudo ground truth has great potential to extend to multiple arbitrary object tracking.
Our goal is to segment the primary video object without manual annotations. The proposed method does not use the temporal information of the whole video clip at once but one frame at a time. Errors from each consequent frame do not propagate along time. As a result, the proposed method has higher tolerance against occlusion and fast motion. We evaluate the proposed method extensively on the DAVIS dataset the FBMS dataset. Our method gives state-of-the-art performance in both datasets with the mean intersection-over-union (IoU) of 79.3% on DAVIS, and 77.9% on FBMS.
This paper will appear in Asian Conference on Computer Vision (ACCV) 2018.
–By Ye Wang
Image inpainting is the task to reconstruct the missing region in an image with plausible contents based on its surrounding context, which is a common topic of low-level computer vision. Making use of this technique, people could restore damaged images or remove unwanted objects from images or videos. In this task, our goal is to not only fill in the plausible contexts with realistic details but also make the inpainted area coherent with the contexts as well as the boundaries.
In spite of recent progress of deep generative models, generating high-resolution images remains a difficult task. This is mainly because modeling the distribution of pixels is difficult and the trained models easily introduce blurry components and artifacts when the dimensionality becomes high. Following [1] which proposes to synthesize an image based on joint optimization of image context and texture constraints, we divide the task into inference and translation as two separate steps and model each step with a deep neural network [2]. We also use simple heuristics to guide the propagation of local textures from the boundary to the hole. Meanwhile, we introduce a novel block-wise procedural training scheme to stabilize the training and propose a new strategy called adversarial annealing to reduce the artifacts [3].
On the other hand, we observe that existing methods based on generative models don’t exploit the segmentation information to constrain the object shapes, which usually lead to blurry results on the boundary. To tackle this problem, we propose to introduce the semantic segmentation information, which disentangles the inter-class difference and intra-class variation for image inpainting [4]. This leads to much clearer recovered boundary between semantically different regions and better texture within semantically consistent segments. Experiments on multiple public datasets show [...]
MCL Director, Professor Kuo, was invited to give four distinguished lectures at three universities in Singapore in the week of October 22-26, 2018.
Dr. Kuo’s trip to Singapore was supported by the College of Engineering of the Nanyang Technological University (NTU) under the program of “Distinguished Speaker in FY2018”. The NTU is an autonomous research university in Singapore. It is known for its eco-friendly and smart technology garden campus — one of the most beautiful school campuses in the world. The University has over 33000 students, organized into eight colleges and schools.
Dr. Kuo delivered two Distinguished Lectures at the NTU. The title of his first lecture was “A Data-Driven Approach to Image-Splicing Localization” and that of his second lecture was “Interpretable Convolutional Neural Networks via Feedforward Design”. The first lecture was built upon recent research work of Ronald Salloum, who is a senior PhD student at MCL. The second lecture was based on Dr. Kuo’s recent research with four MCL members (Min Zhang, Siyang Li, Jiali Duan and Yueru Chen) as collaborators. Both lectures were well received.
Dr. Kuo also visited the National University of Singapore (NUS) and the Singapore University of Technology and Design (SUTD) during his short stay in Singapore. His visit to SUTD was hosted by Professor Ngai-Man Cheung who is an SIPI alumnus (see the accompanying photo with the news.)