MCL Research on Point Cloud Object Retrieval and Pose Estimation
Object pose estimation is an important problem in 3D scene understanding. Given a 3D point cloud object, it tries to estimate the 6-DOF pose comprising of rotation and translation with respect to a chosen coordinate system. The pose information can then be used for downstream tasks such as object grasping, obstacle avoidance, path planning, etc. which are commonly encountered in Robotics. In a complete scene understanding system, pose estimation usually comes after a 3D detection algorithm has localized and classified the object.
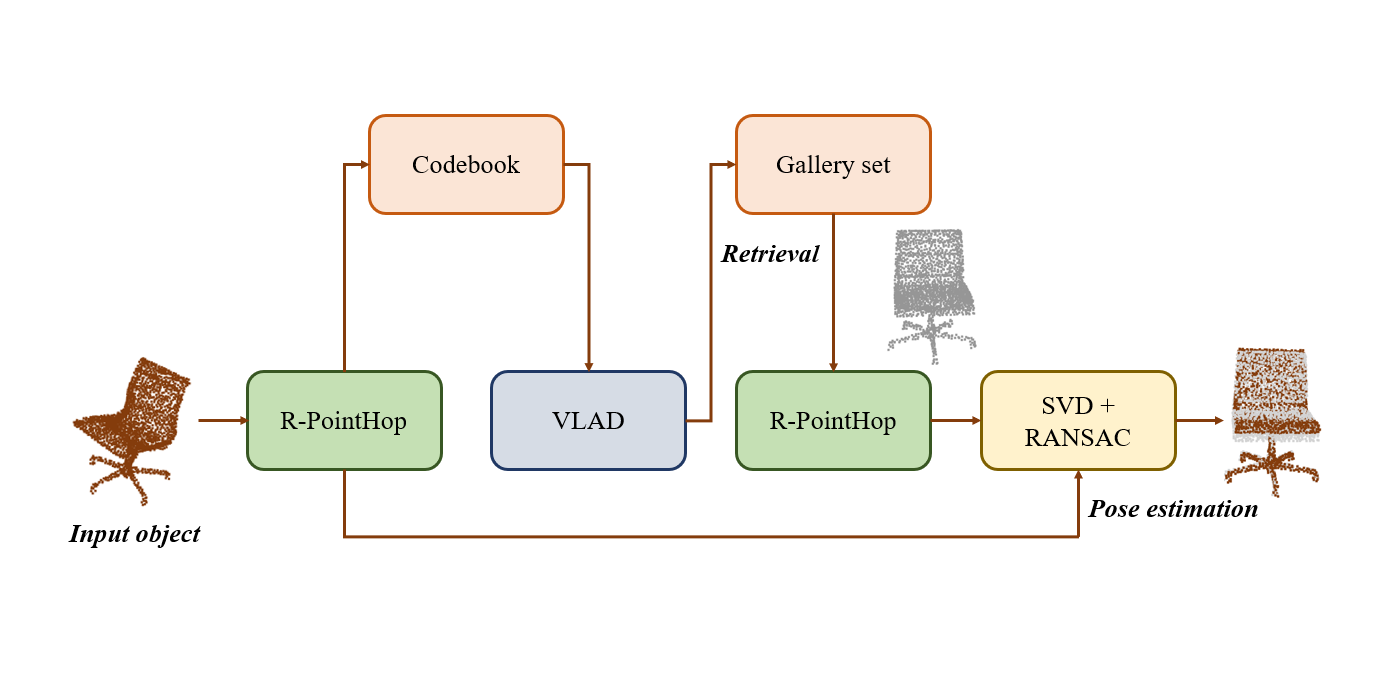
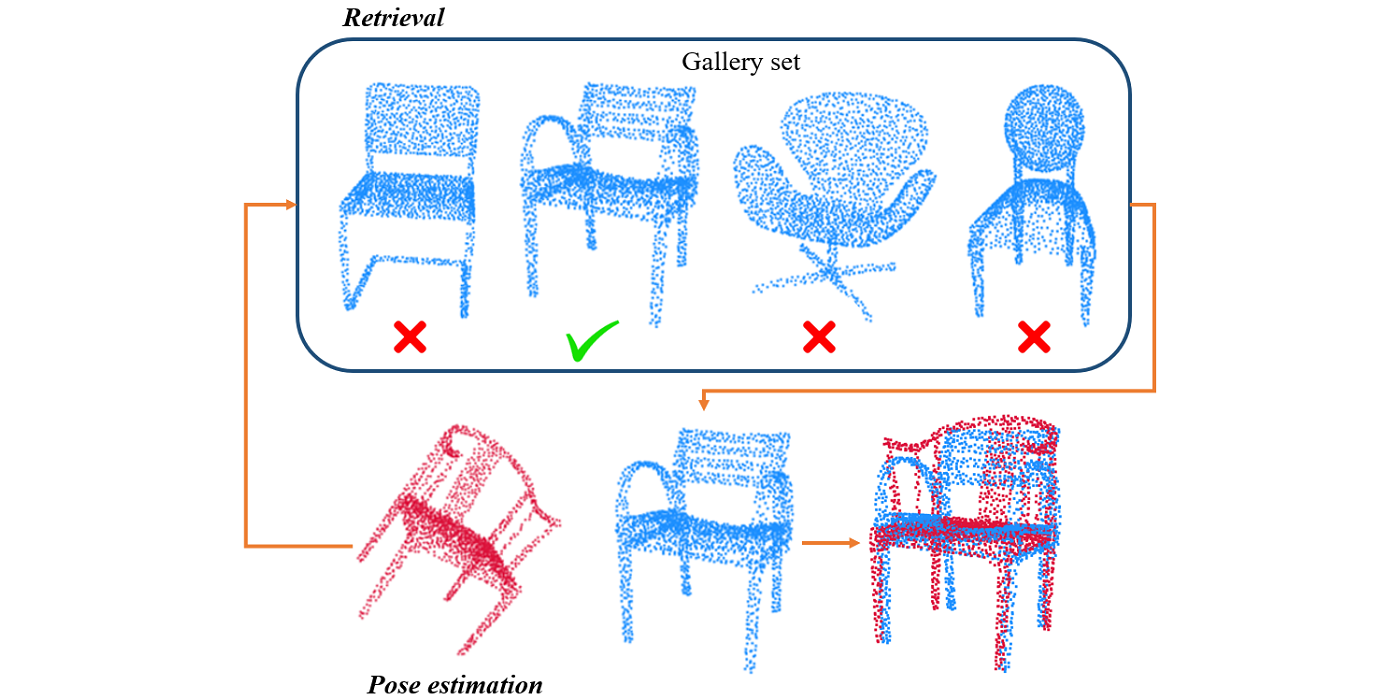
The pose estimation problem is similar to the problem of point cloud object registration which has been previously studied at MCL. In particular, the R-PointHop [1] method was proposed which successfully registers a source point cloud with a template. In the most recent work, we present a method termed PCRP that modifies R-PointHop for object pose estimation when a similar template object is unavailable. PCRP assumes a gallery set of pre-aligned point cloud objects and reuses the R-PointHop features to retrieve a similar object from the gallery. To do so, the pointwise features obtained using R-PointHop are aggregated into a global feature vector for nearest neighbor retrieval using the Vector of Locally Aggregated Descriptors (VLAD) [2]. Then, the input object’s pose is estimated by registering it with the retrieved object.
Though point cloud retrieval is extensively studied in contexts like shape retrieval or place recognition, retrieval in presence of different object poses is less talked of. In this work we show how the similar object can be retrieved even in presence of different object poses. This is achieved due to the rotation invariant features learned by R-PointHop. Another improvement over R-PointHop is the replacement of conventional eight octant partitioning based point attributes with more [...]