MCL Research on Supervision-Scalable Object Recognition
Supervised learning is the main stream in pattern recognition, computer vision and natural language processing nowadays due to the great success of deep learning. On one hand, the performance of a learning system should improve as the number of training samples increases. On the other hand, some learning systems may benefit more than others from a large number of training samples. For example, deep neural networks (DNNs) often work better than classical learning systems that contain feature extraction and classification two stages. How the quantity of labeled samples affects the performance of learning systems is an important question in the data-driven era.
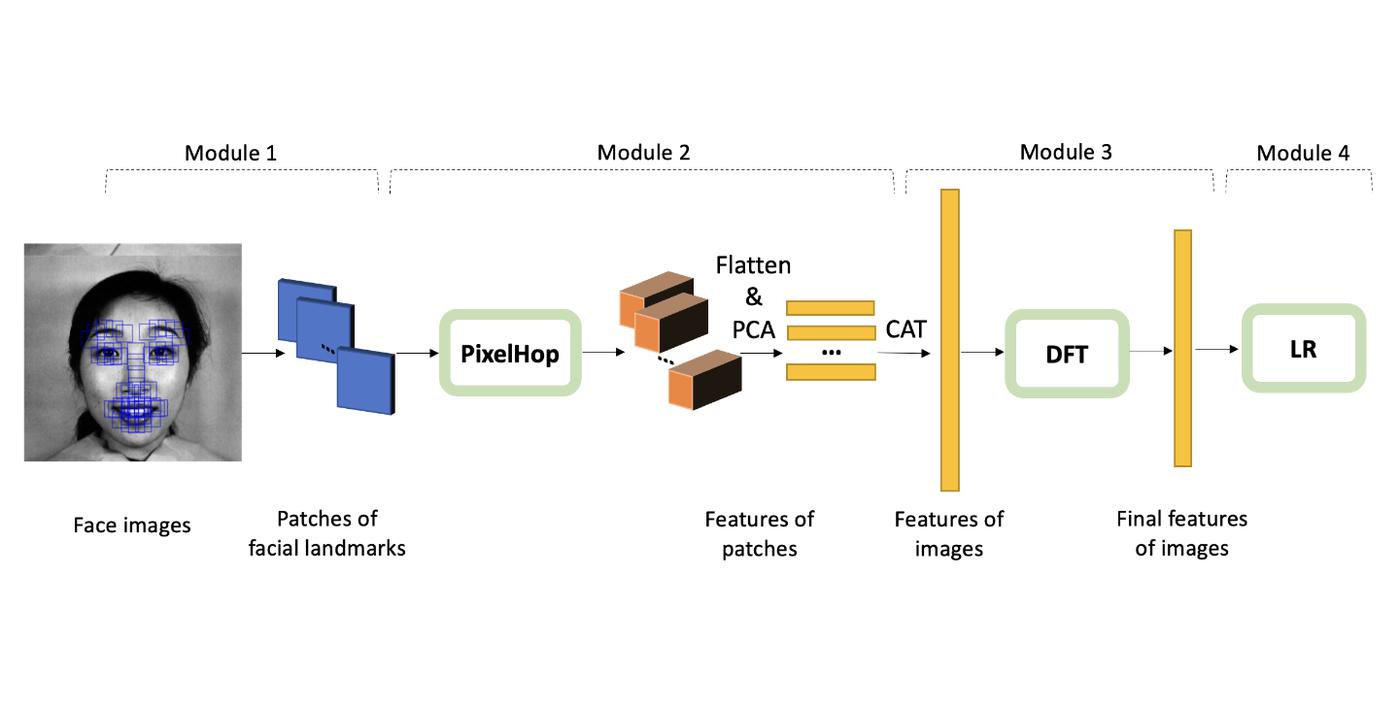
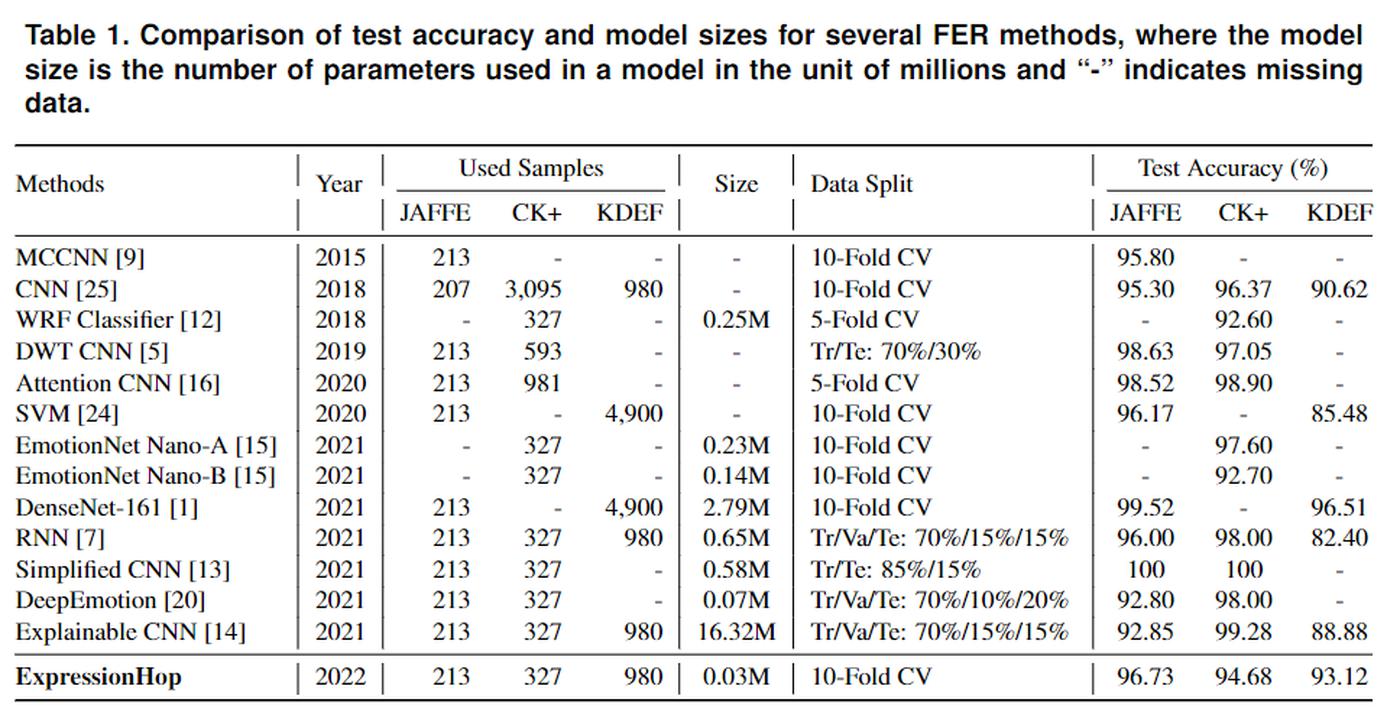
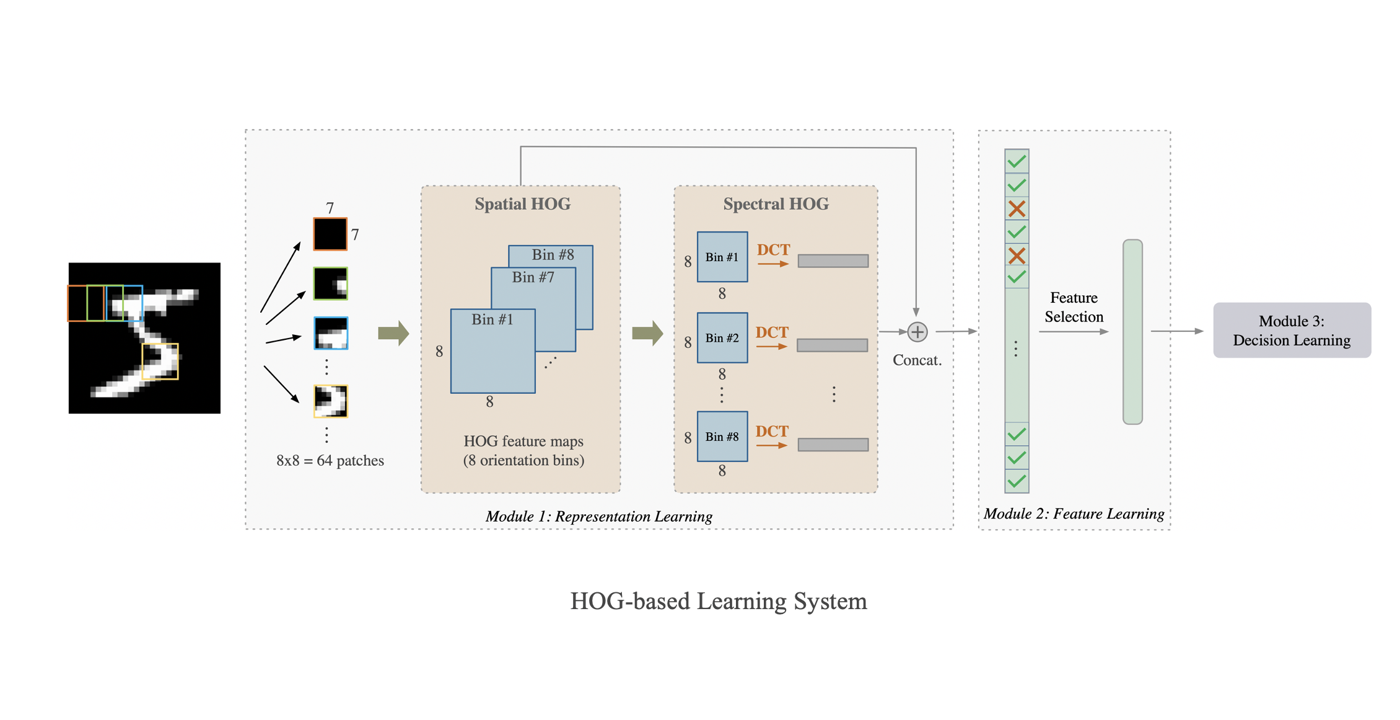
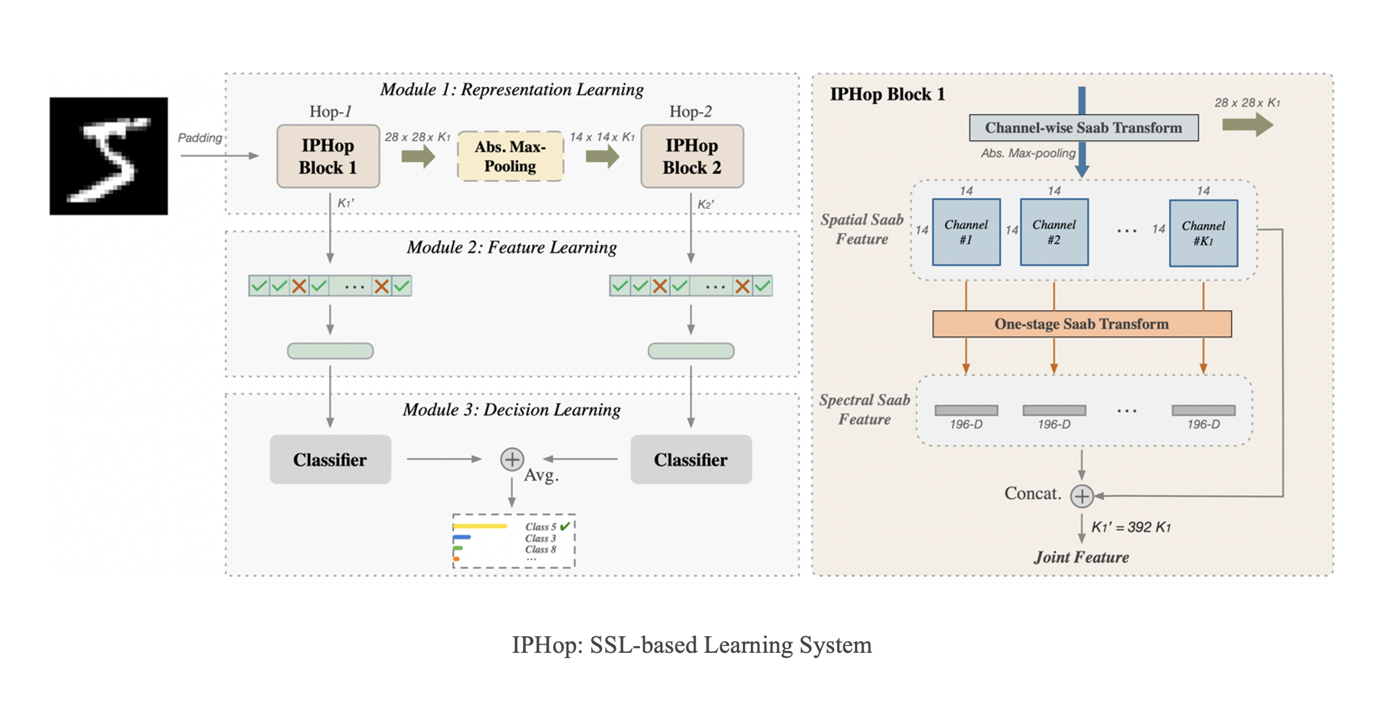
In fact, humans can learn effectively in a weakly supervised setting. In contrast, deep learning networks often need more labeled data to achieve good performance. What makes weak supervision and strong supervision different? There is little study on the design of supervision-scalable leaning systems. Is it possible to design a supervision-scalable learning system? Recently, MCL researchers attempt to shed light on these questions by choosing the object recognition problem as an illustrative example [1]. The design of two learning systems are presented that demonstrate an excellent scalable performance with respect to various supervision degrees. The first one adopts the classical histogram of oriented gradients (HOG) features, while the second one named improved PixelHop (IPHop) uses successive-subspace-learning (SSL) features [2]. The scalable learning system consists of three modules: representation learning, feature learning, and decision learning. In the second and the third modules, different designs are proposed to be adaptive to different supervision levels. Specifically, variance thresholding based feature selection and kNN classifier are used when the training size is small, while when the training size becomes larger, Discriminant Feature Test (DFT) [...]