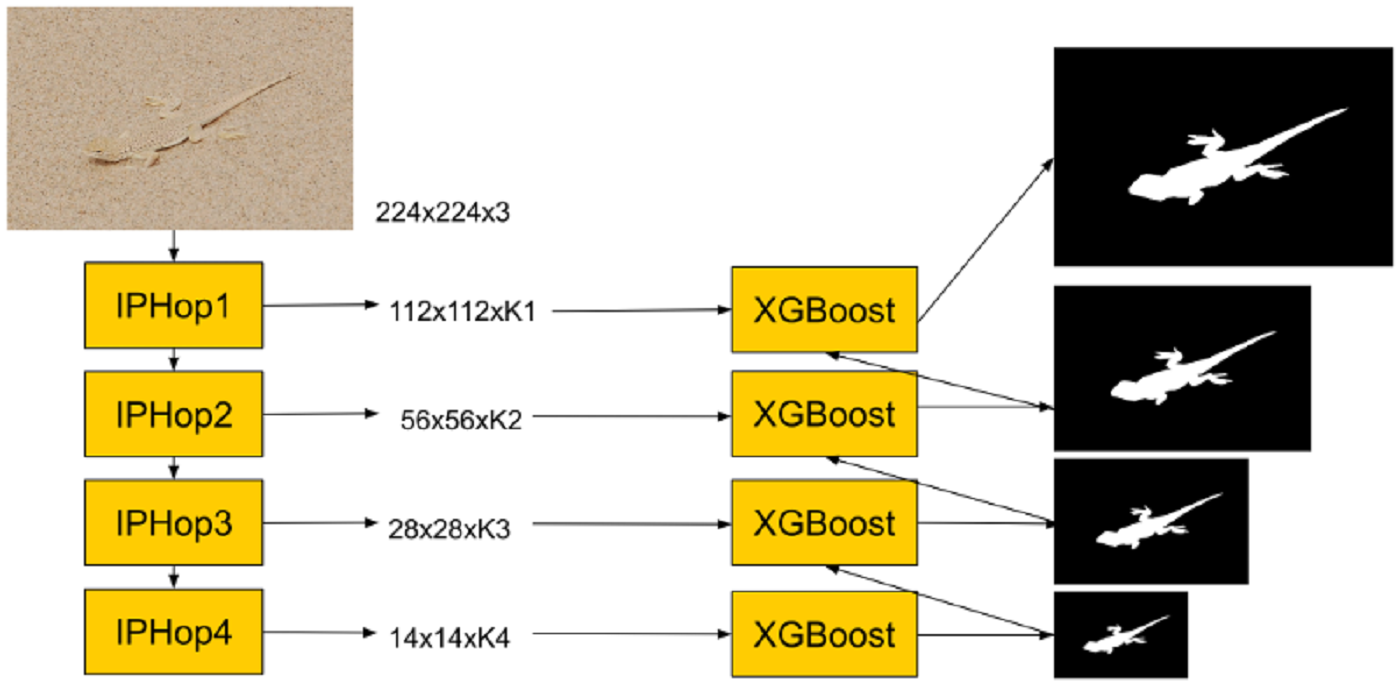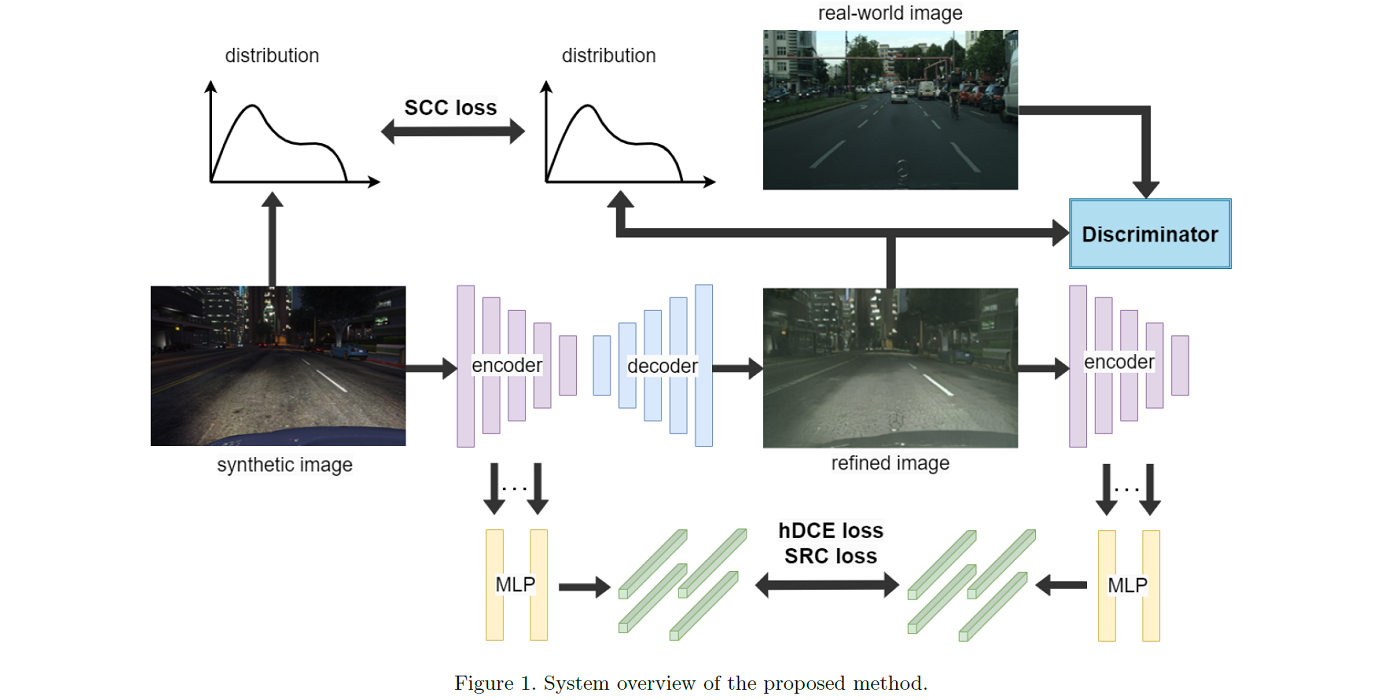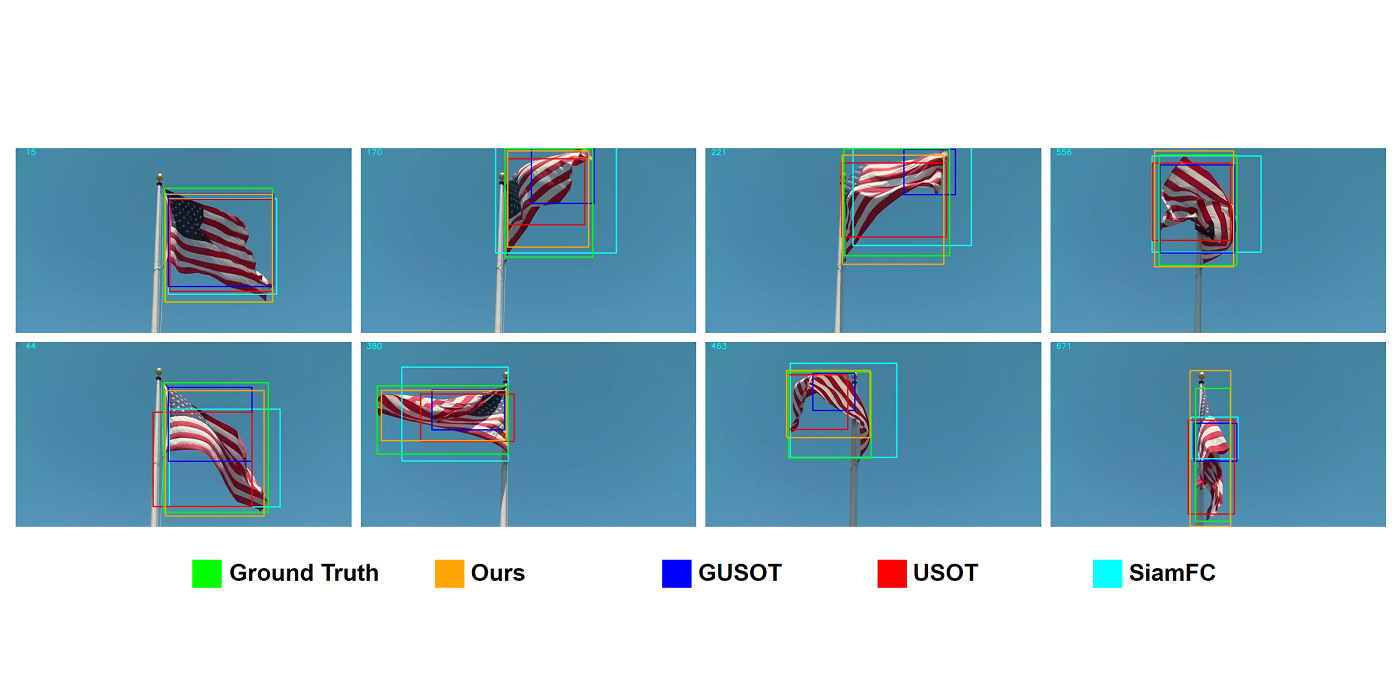
MCL member Vasileios Magoulianitis presented in the ICASSP 2023 conference
Vasileios had a trip to Greece to attend ICASSP 2023 and present two posters of MCL. Let’s hear what he would like to share about his experience:
ICASSP this year was held on the island of Rhodes in Greece which is popular touristic summer destination. The venue hosted a quite large number of presentations this year -most of them as posters-, interesting keynote speeches and other IEEE community side events, such as the celebration of Signal Processing Society (SPS) 75th anniversary.
I presented two works of our lab in form of posters, the one on rotation invariant 3D Point cloud classification, proposed by Pranav Kadam et al. and the new classification method from our lab, named SLM (Classification via Subspace Learning Machine), proposed by Hongyu Fu. Most of the individuals that stopped by the posters, commented on the fact that our works stood out from the rest deep learning approaches, as they have more intuition and transparency, as well as offering a lightweight solution, which was especially appealing to some industry representatives.
Peripheral to the ICASSP venue, other non-technical activities took place, such as traditional cooking or Greek dancing lessons, and some festival nights with live music bands.
— Vasileios Magoulianitis