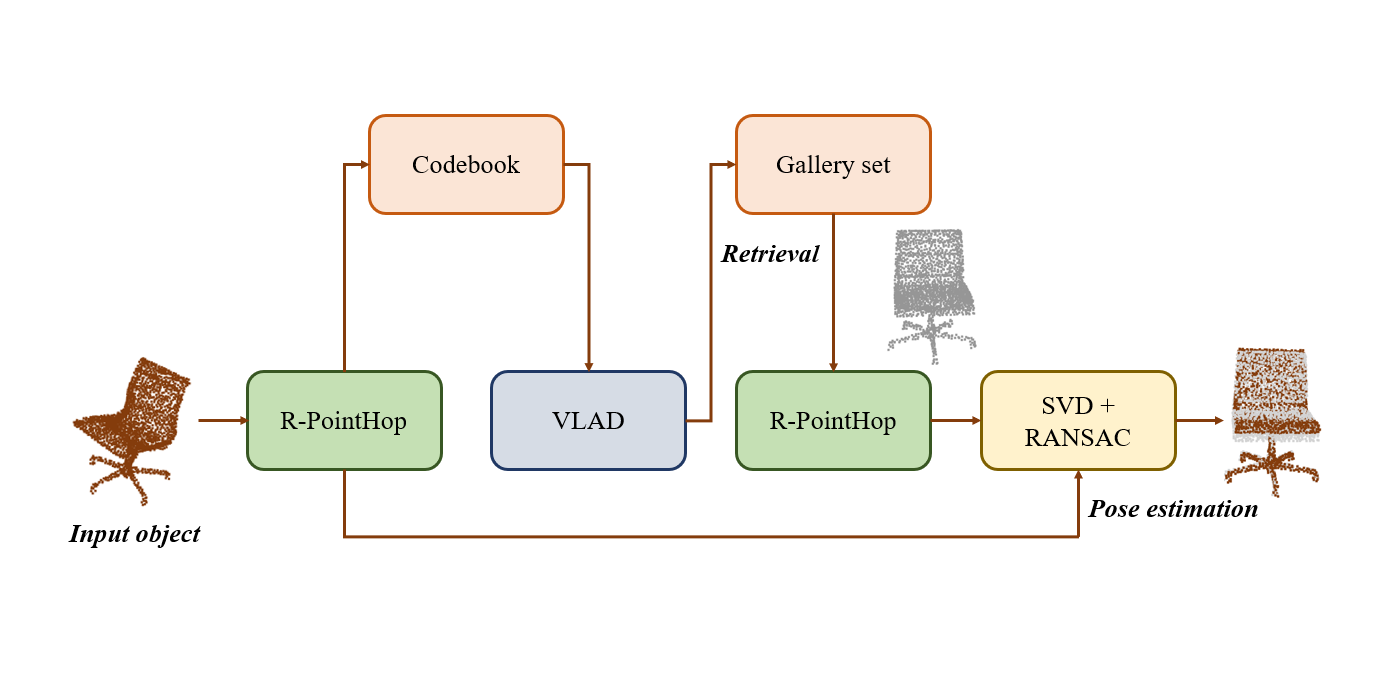
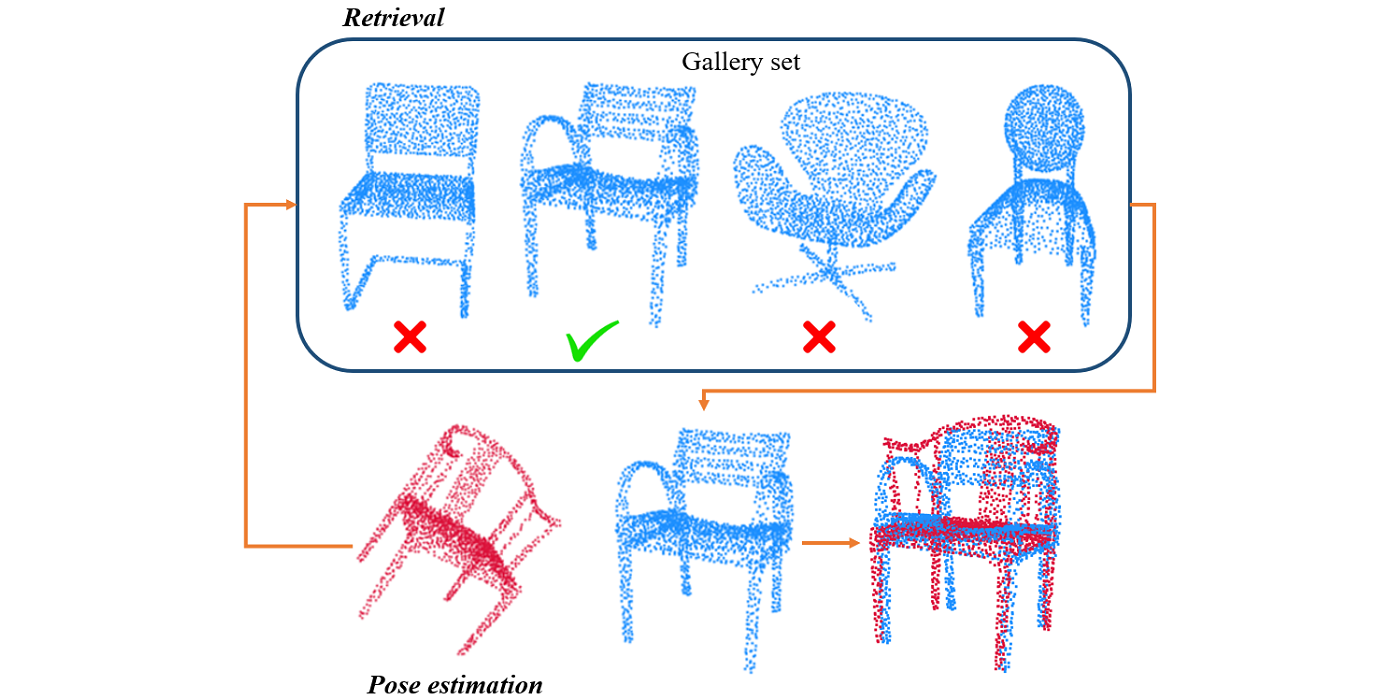
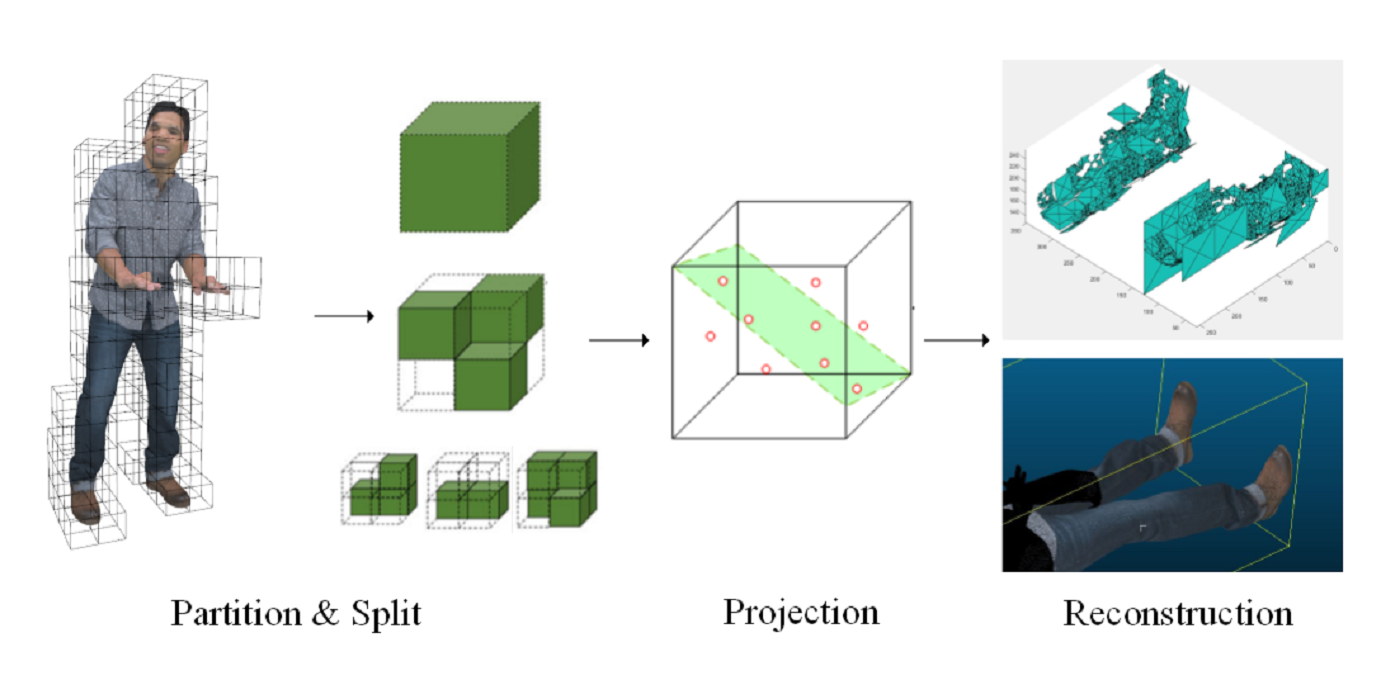
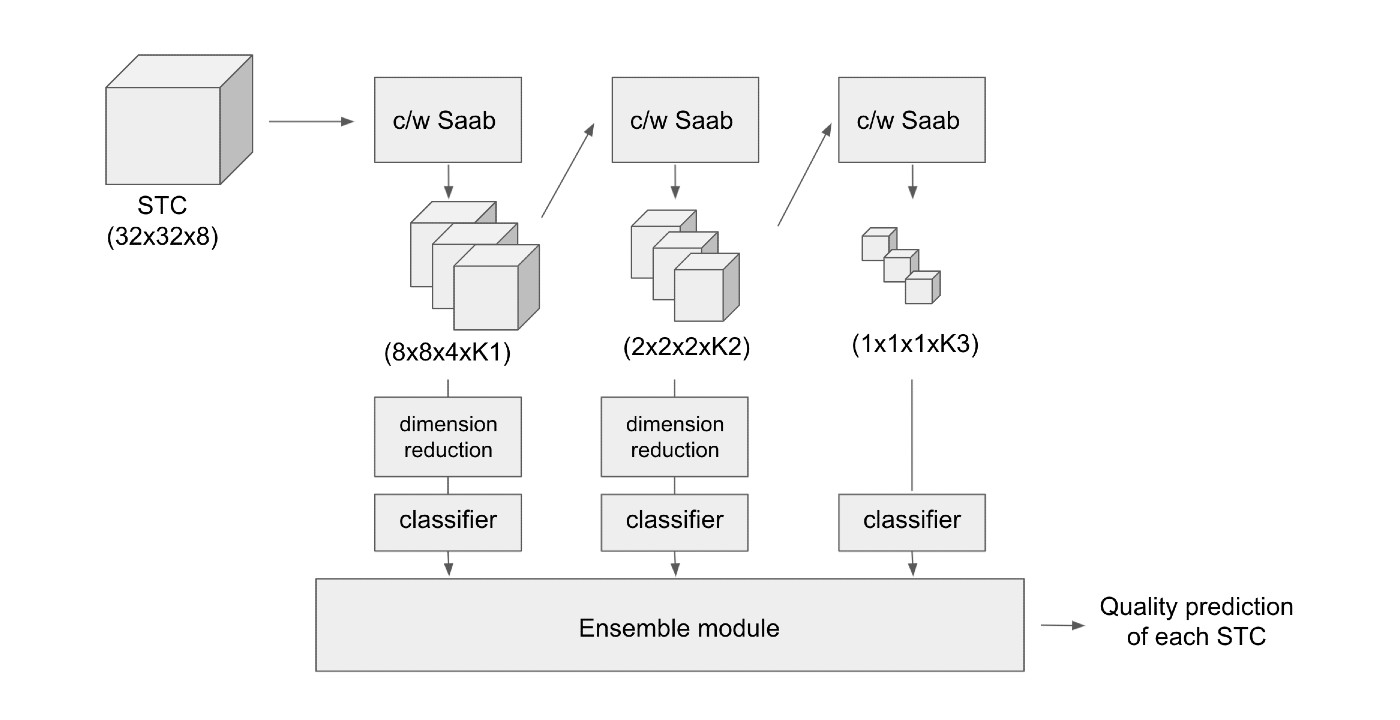
MCL Research on Green Progressive Learning
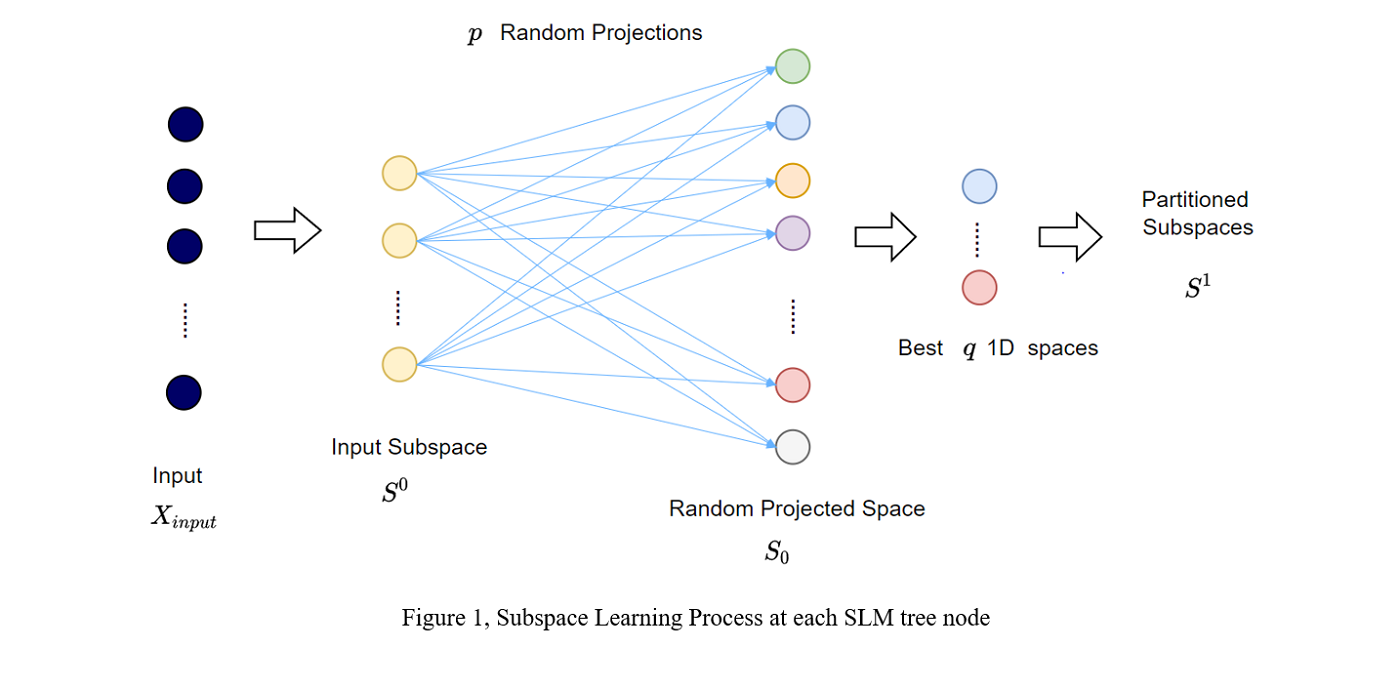
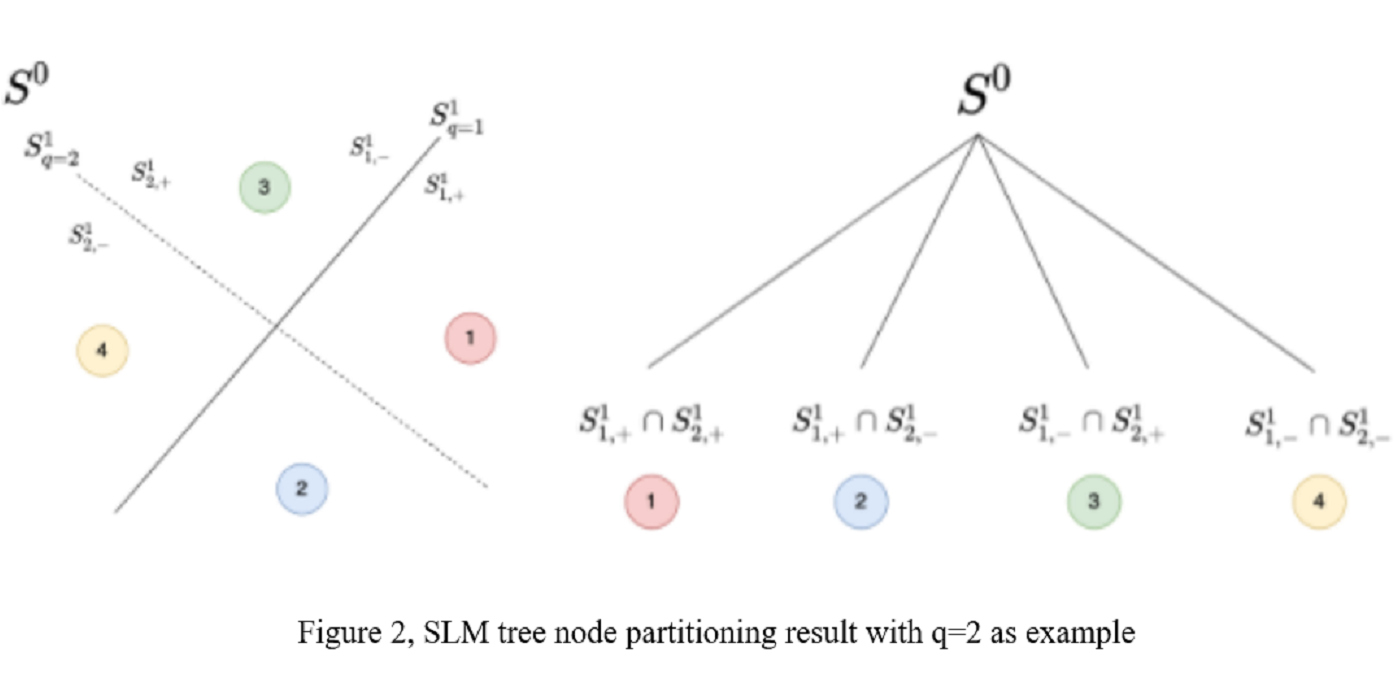
Image classification has been studied for many years as a fundamental problem in computer vision. With the development of convolutional neural networks (CNNs) and the availability of larger scale datasets, we see a rapid success in the classification using deep learning for both low- and high-resolution images. Although being effective, one major challenge associated with deep learning is that its underlying mechanism is not transparent. Being inspired by deep learning, the successive subspace learning (SSL) methodology was proposed by Kuo et.al. in a sequence of papers. Different from deep learning, SSL-based methods learn feature representations in an unsupervised feedforward manner using multi-stage principle component analysis (PCA). Joint spatial-spectral representations are obtained at different scales through multi-stage transforms.
Applying the existing SSL-based model the classification takes usage of all the data at a time for the training, which is a single-round approach. Among the samples, there are easy samples which is usually of a high ratio in the dataset, and a portion of hard samples. Easy samples can achieve quite high conditional accuracy, while hard samples need further attention as the distribution are masked by the easy sample. This motivates the design of Green Progressive Learning, which adds more rounds of training progressive to zoom in to smaller and smaller subspace of hard samples. The selection of training samples to train the progressive learning in each round is critical to the performance gain. In each learning round, the hard training samples are re-selected to represent the subspace. Experiments on MNIST and Fashion-MNIST show the potential of progressive learning, which can help boost the performance of difficult cases.
— By Yijing Yang
Reference:
Chen and C.-C. J. Kuo, “Pixelhop: A successive subspace learning (ssl) method for object recognition,” Journal [...]