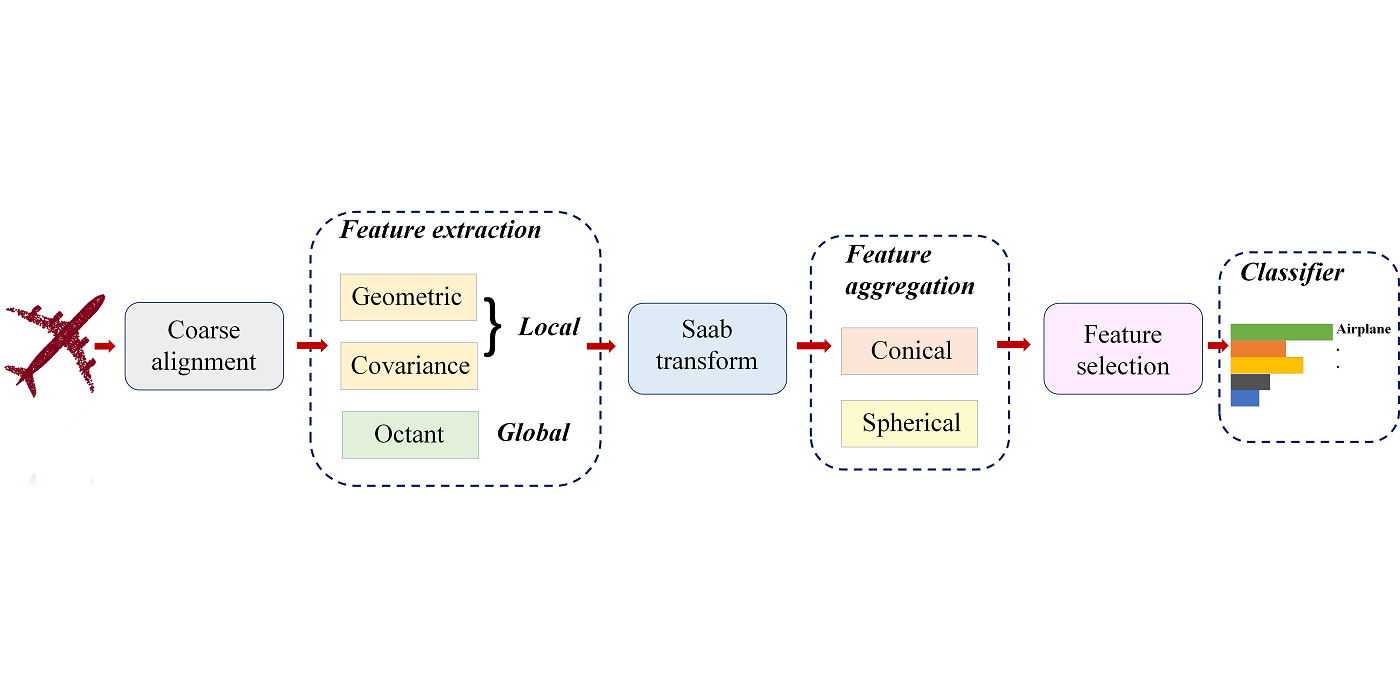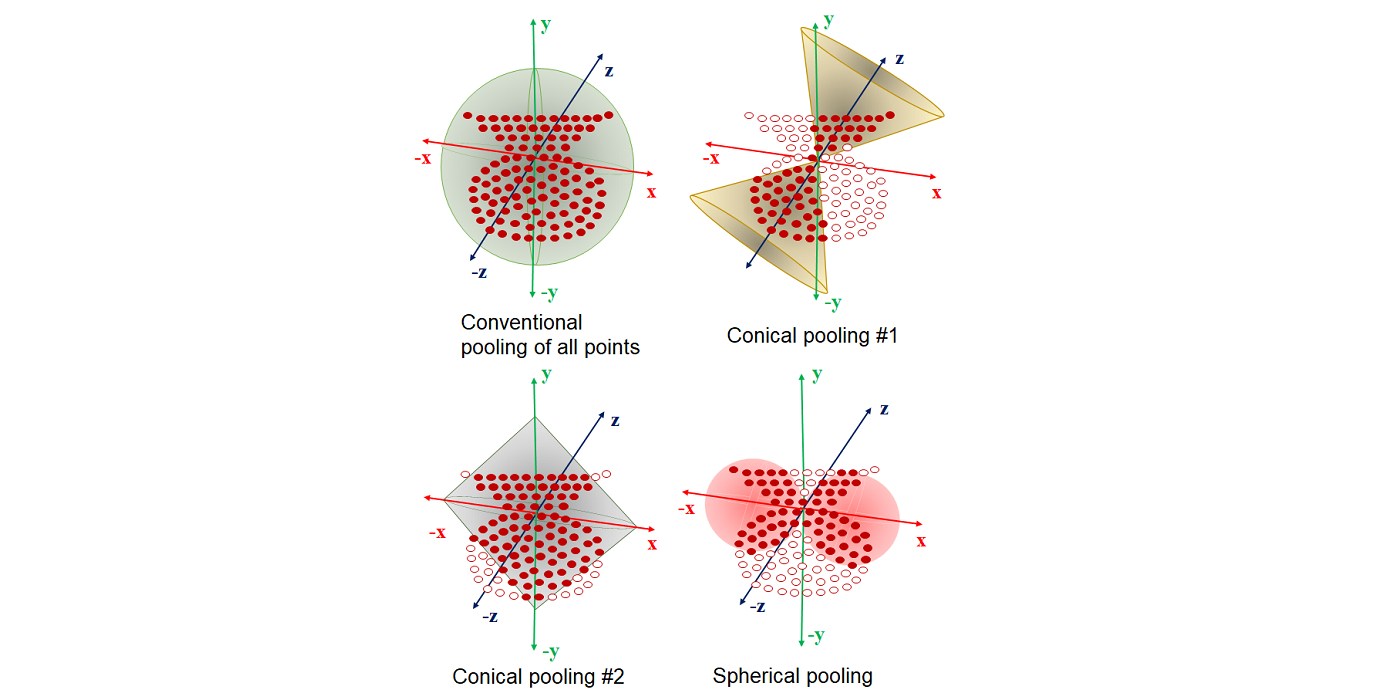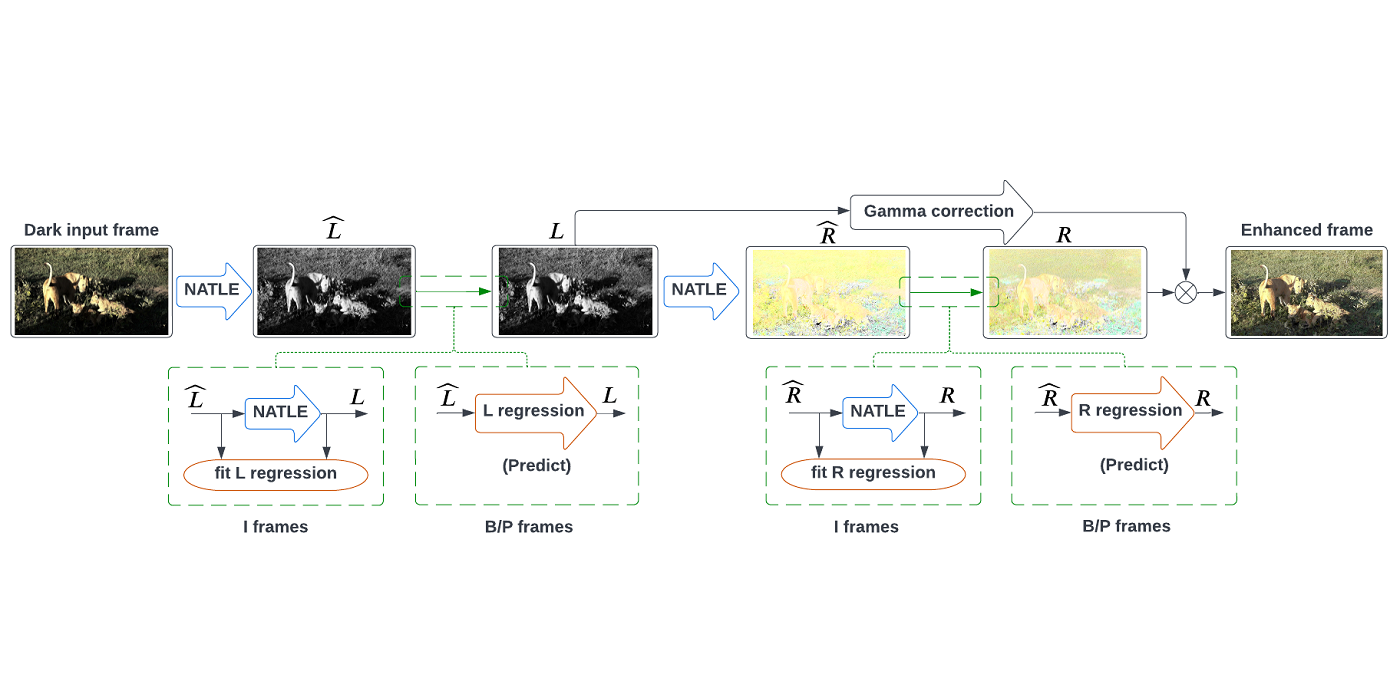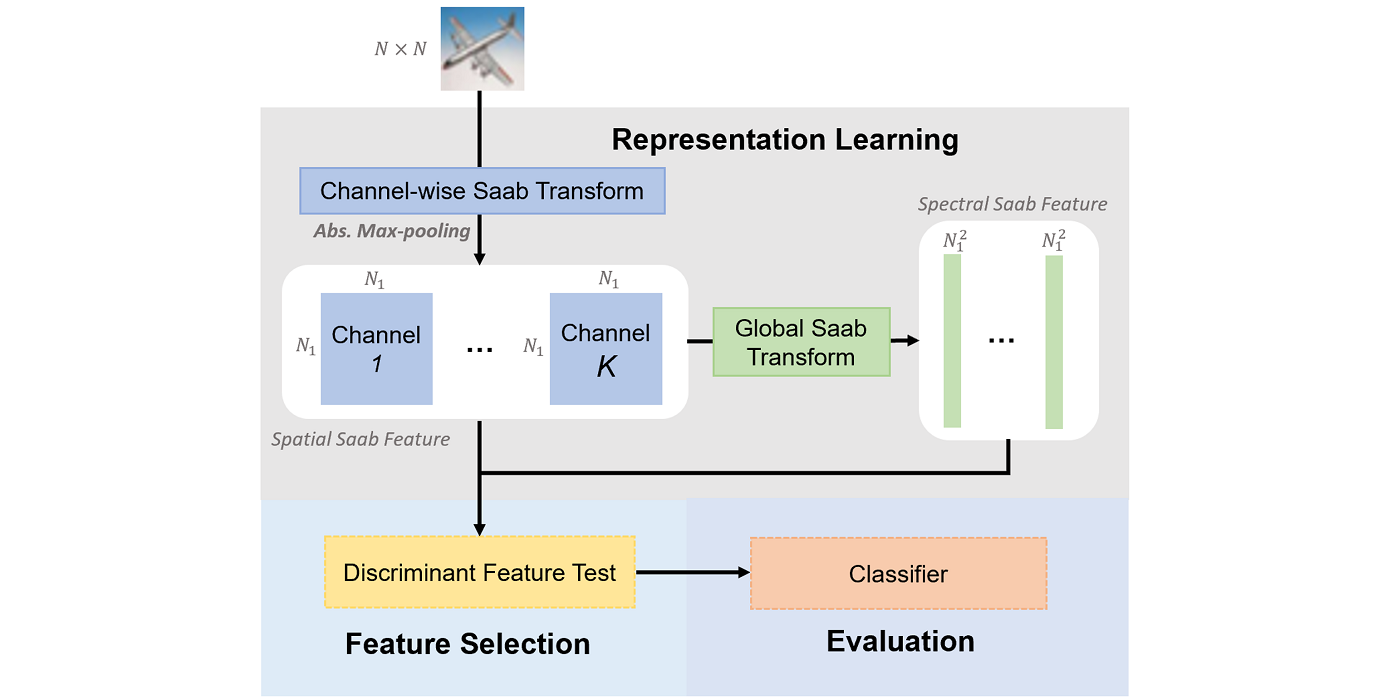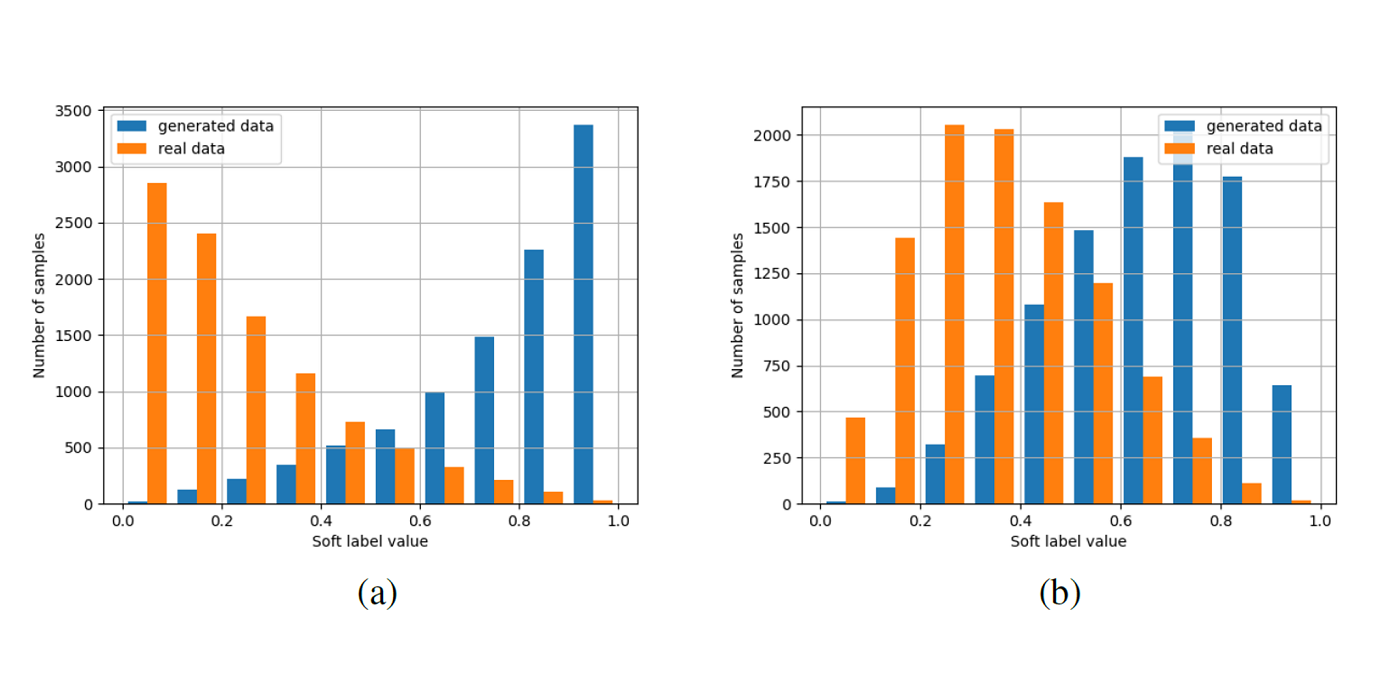
MCL Research on Knowledge Graph Entity Typing Prediction
Knowledge graph entity typing (KGET) is a task to predict the missing entity types in the knowledge graphs (KG). Previously, KG embedding (KGE) methods tried to solve the KGET task by introducing an auxiliary relation “hasType” to model the relationship between entities and their corresponding types. However, a single auxiliary relation has limited expressiveness for the diverse patterns between entities and types.
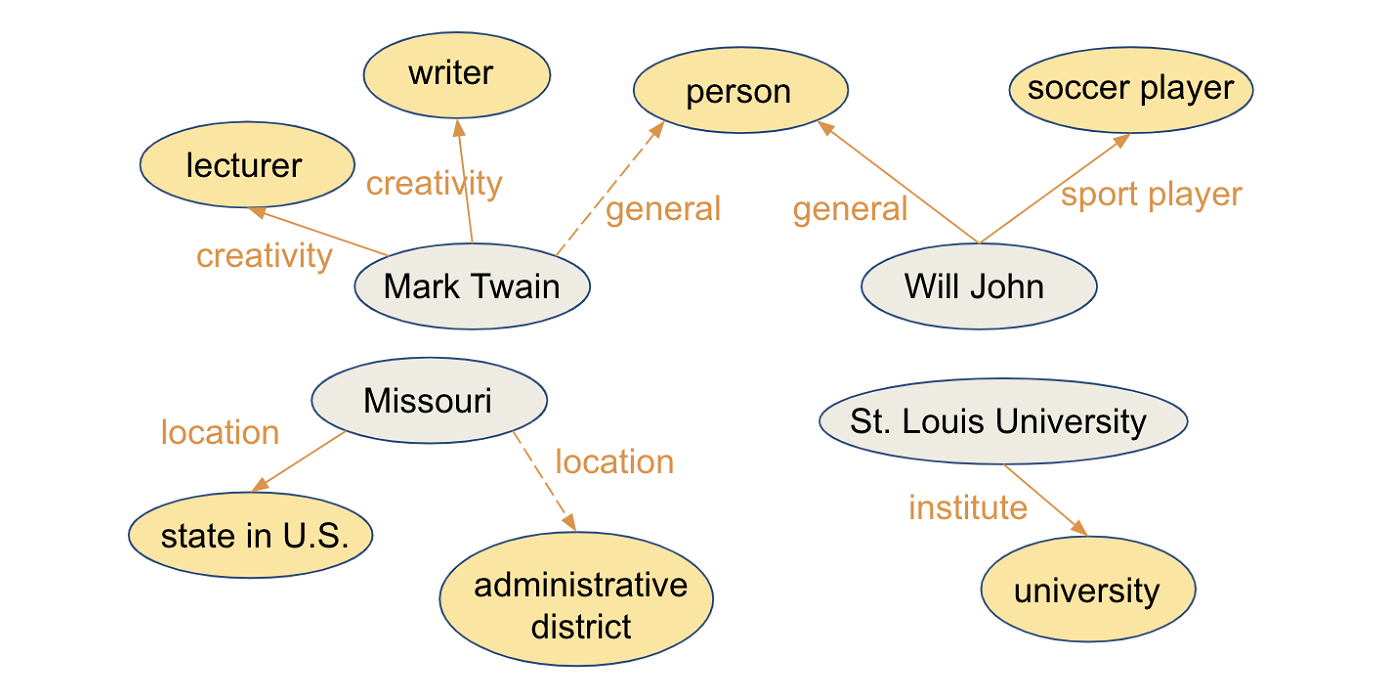
In this work, we try to assign more auxiliary relations based on the “context” of the types to improve the expressiveness of KGE methods. The context of a type is defined as a collection of attributes of the corresponding entities. As such, the neighborhood information is implicitly encoded when the auxiliary relations are introduced. Similar types might share the same auxiliary relation to model their relationship with entities. Fig. 1 shows an example of using multiple auxiliary relations to model the typing relationship for different entity types. From the figure, it’s intuitive to use different auxiliary relations to model typing relationships for “administrative district” and “person” since these two types are largely different from each other. In addition, for “writer” and “soccer player”, different auxiliary relations should also be considered since they shouldn’t be embedded closely to each other in the embedding space. However, some types, such as “writer and “lecturer”, co-occur with each other often so they can adopt the same auxiliary relation to model the relationships with entities.
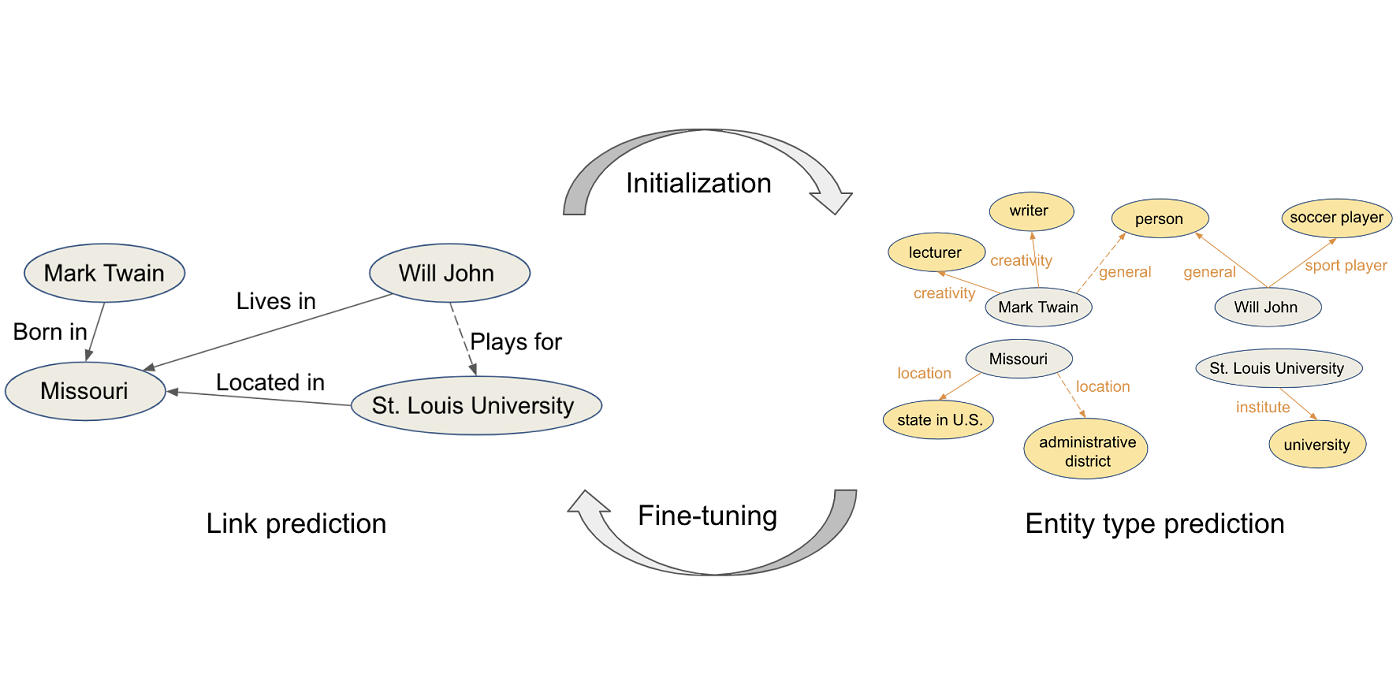
In addition, we propose an iterative training scheme, named KGE-iter, to train KGE models for the KGET task. Fig. 2 is an illustration of the proposed iterative training scheme. The entity embeddings are first initialized by training with only factual triples. Then, typing information is used to fine-tune the entity embeddings. Two training stages [...]