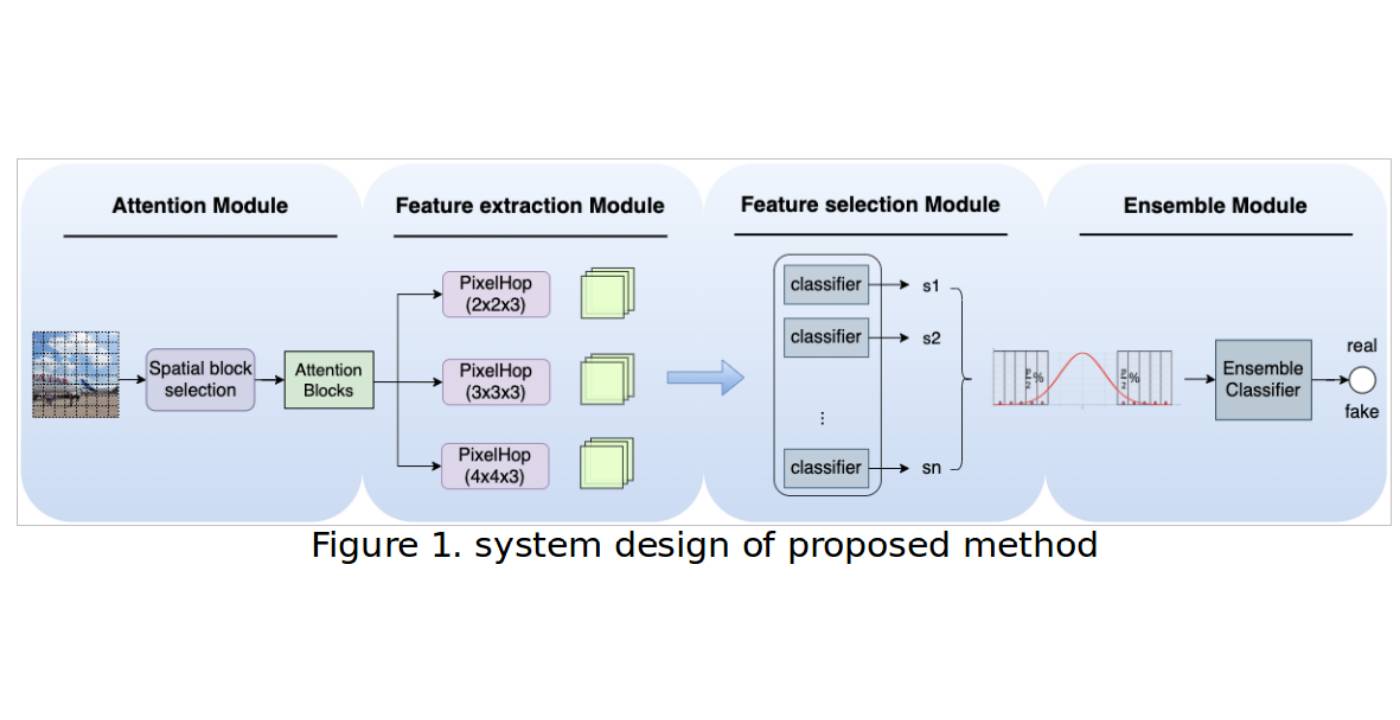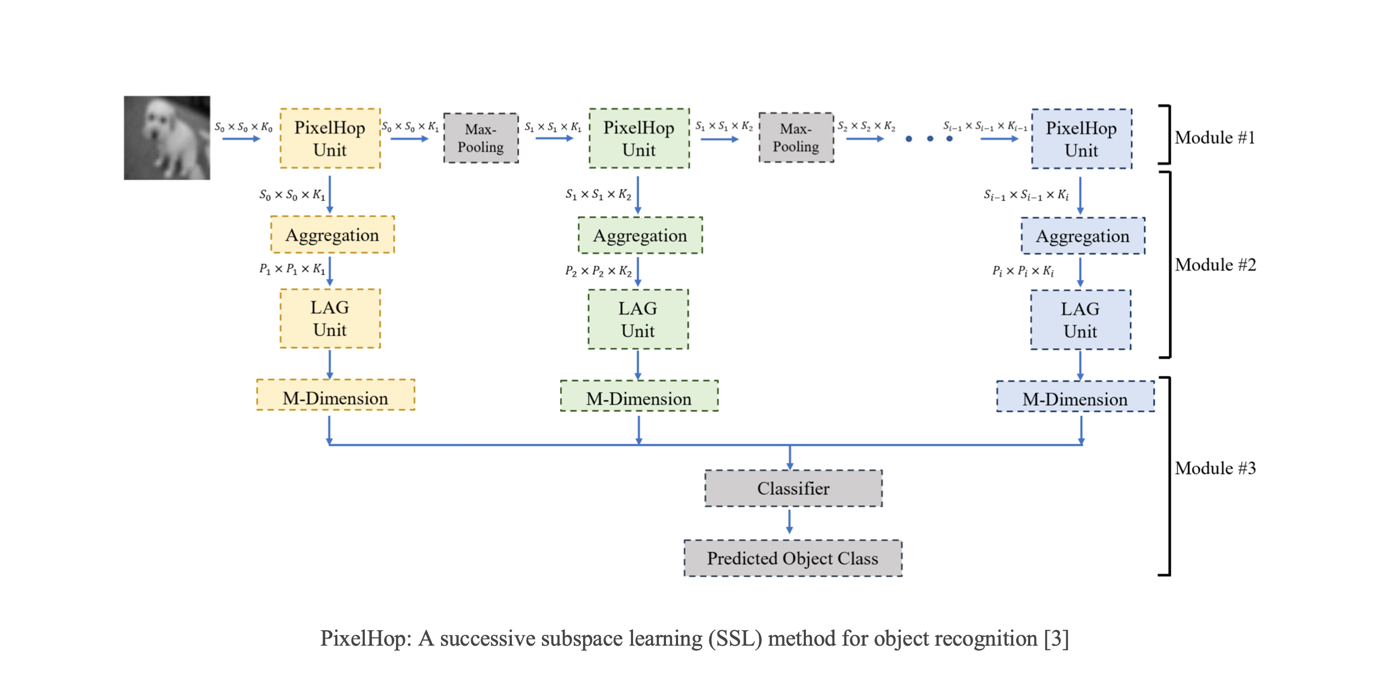
MCL Research on Negative Sampling for Knowledge Graph Learning
A knowledge graph is a collection of factual triples (h, r, t) consisting of two entities and one relation. Most knowledge graphs suffer from the incompleteness that there are many missing relations between entities. To predict missing links, each relation is modeled by a binary classifier to predict whether the links between two entities exist or not. Negative sampling is a task to draw negative samples efficiently and effectively from the unobserved triples to train the classifiers. The quality and quantity of the negative samples will highly affect the performance on link prediction.
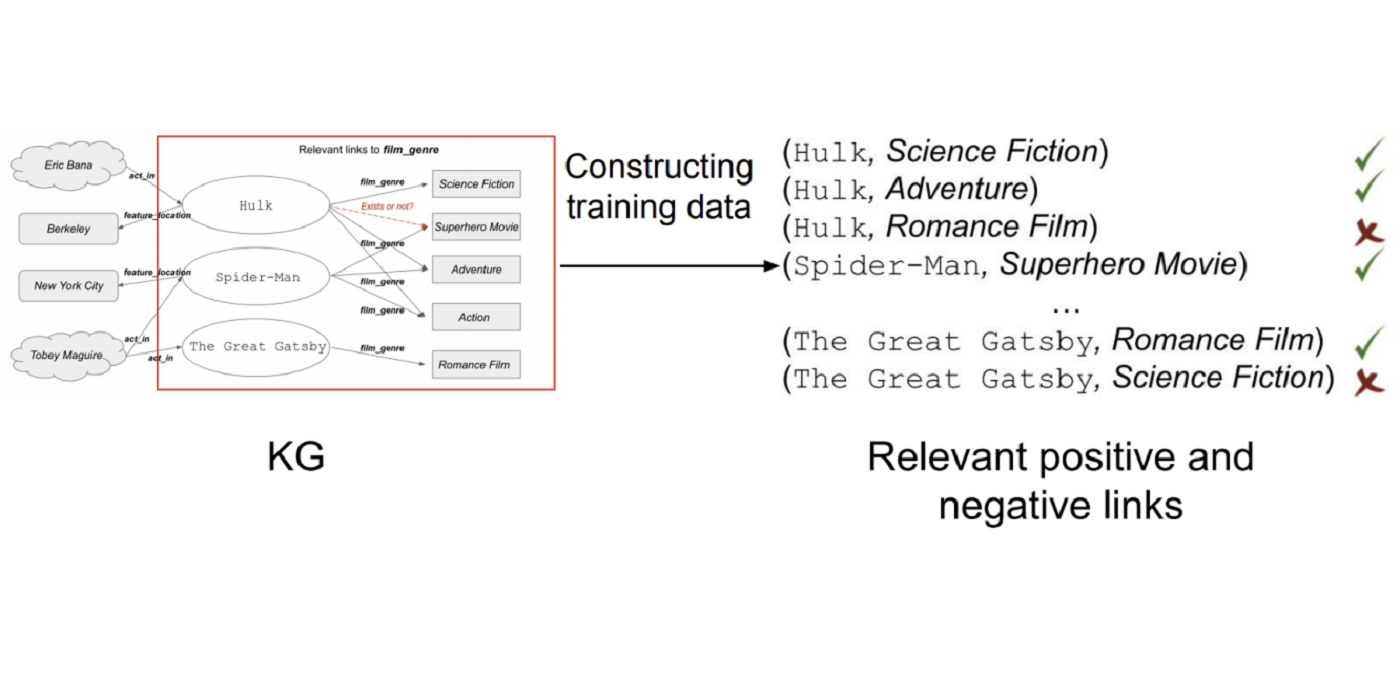
Naive negative sampling [1] suggests generating negative samples by corrupting one of the entities in the observed triples, e.g. (h’, r, t) or (h, r, t’). Despite the simplicity of naive negative samples, the generated negative samples carry little semantics. For example, given a positive triple (Hulk, movie_genre, Science Fiction), a negative sample (Hulk, movie_genre, New York City) might be generated by naive negative sampling, which will never be a valid triple in the real-world scenario. Instead, we are looking for negative examples, such as (Hulk, movie_genre, Romance), that provide more information to the classifiers. Based on the observation, we only draw the corrupted entities within the set of observed entities that have been linked by the given relation, also known as the ‘range’ for the relation. However, a drawback is that the chance of drawing false negatives is high. Therefore, we further filter the drawn corrupted entities based on the entity-entity co-occurrence. For example, it’s not likely for us to generate a negative sample (Hulk, movie_genre, Adventure) because we know from the dataset that movie genres ‘Science Fiction’ and ‘Adventure’ are highly co-occurred. The first figure shows how the positive [...]