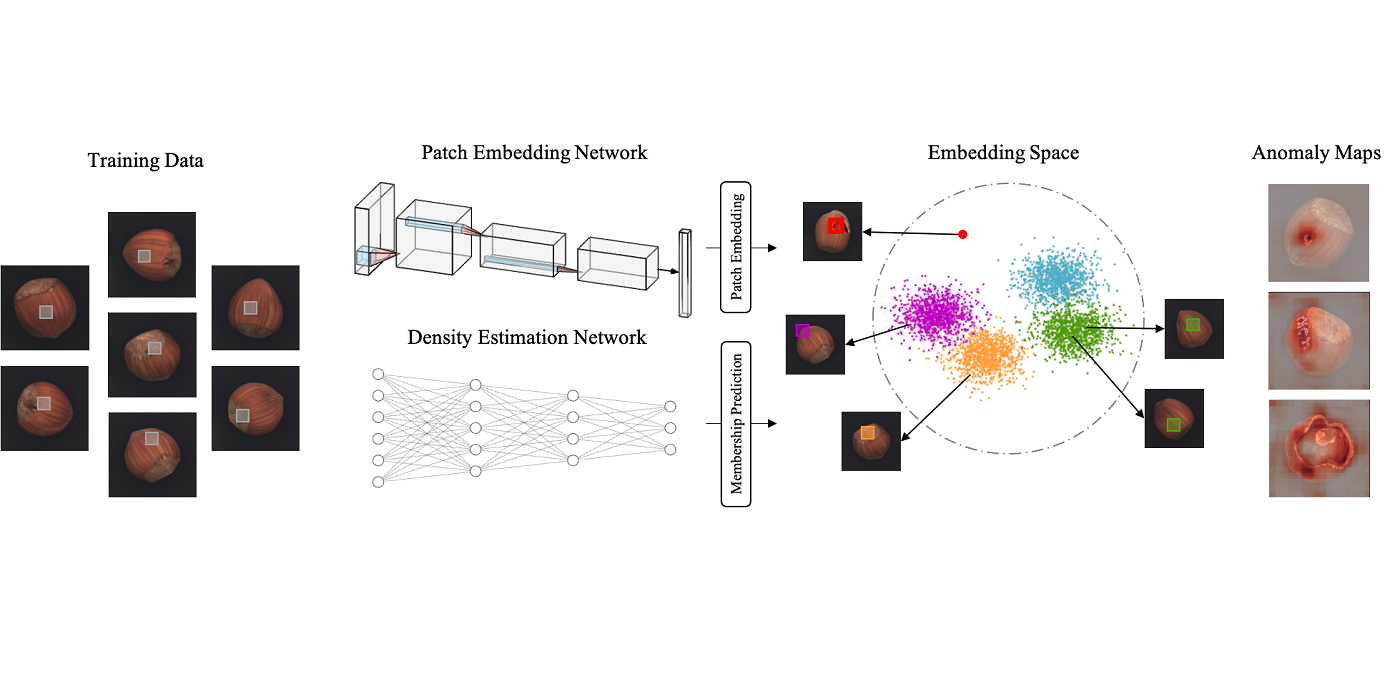
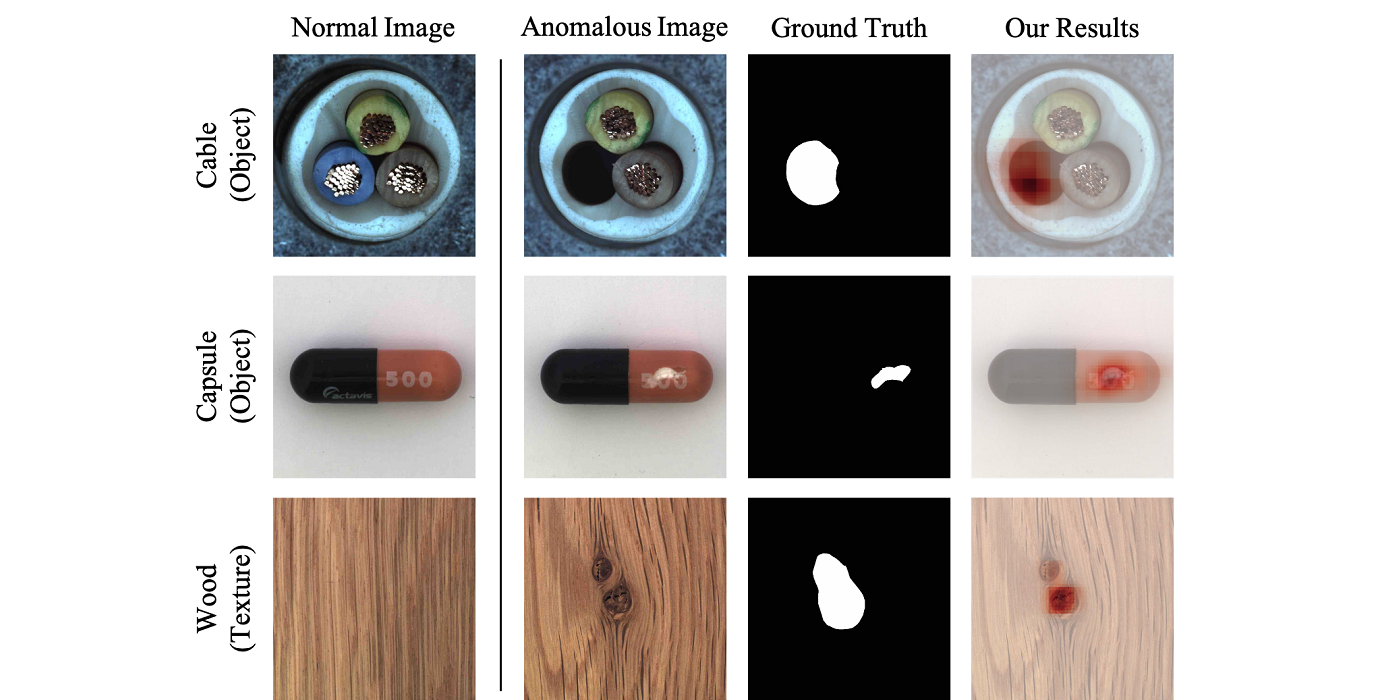
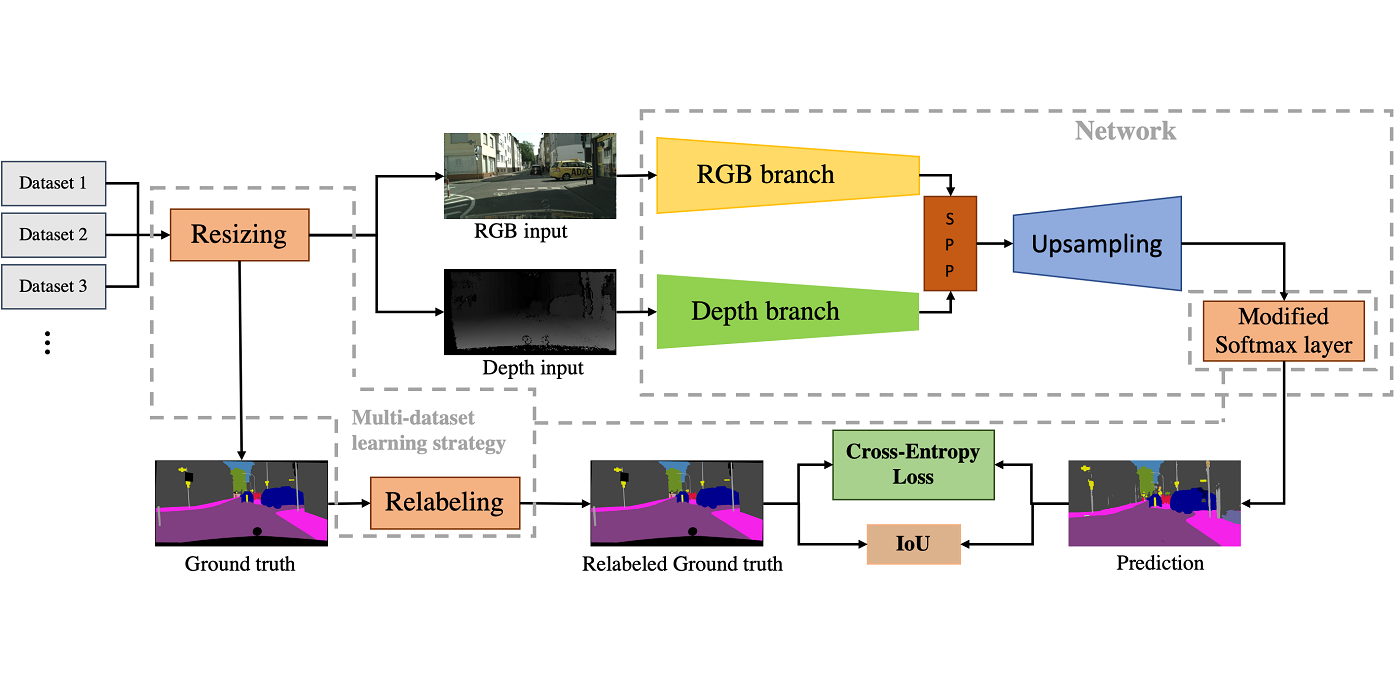
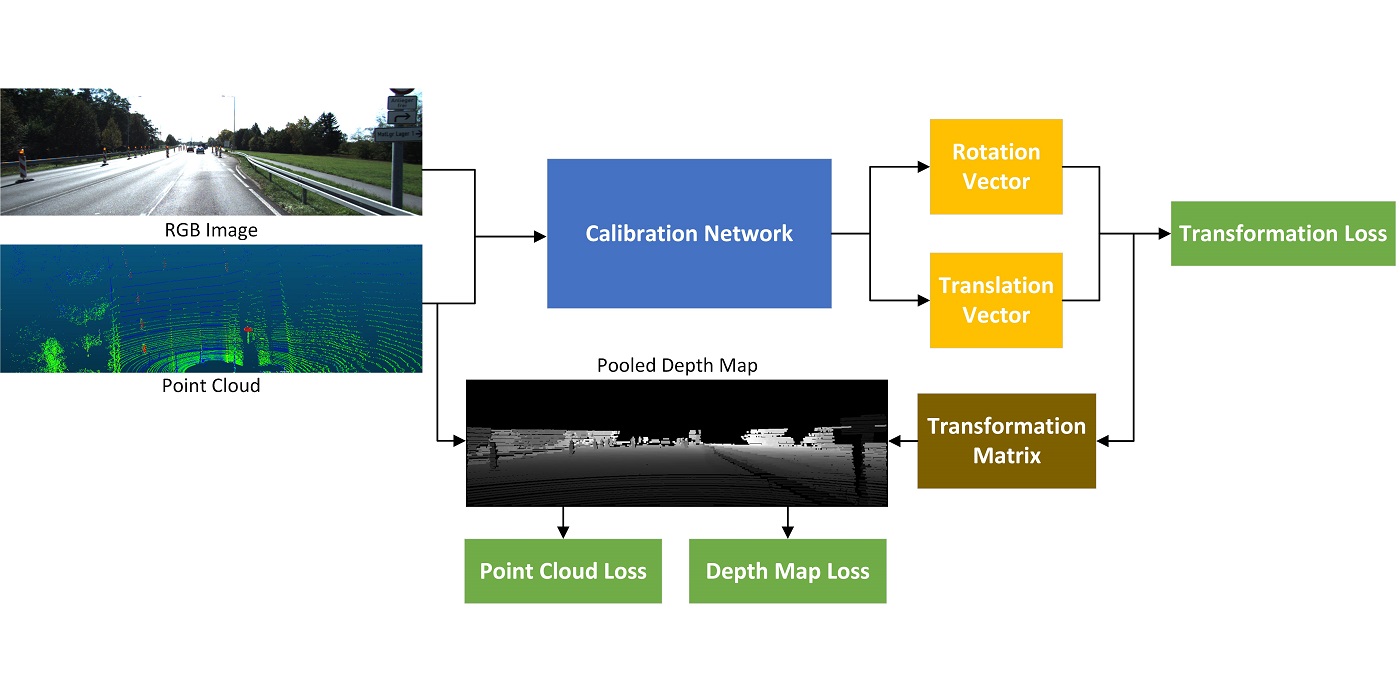
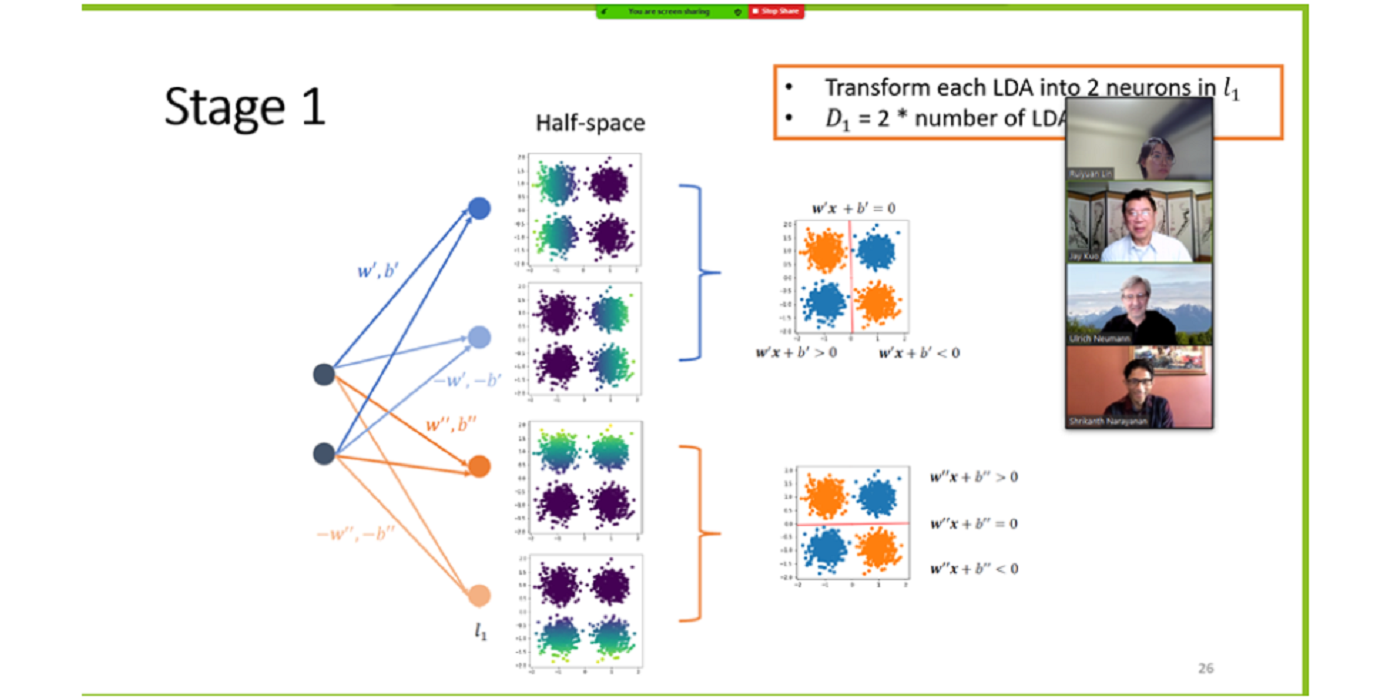
MCL Research on Data-Driven Image Compression
Block-based image coding is adopted by the JPEG standard, which has been widely used in the last three decades. The block-based discrete Cosine transform (DCT) and quantization matrices in YCbCr three color channels play key roles in JPEG. In this work, we propose a new image coding method, called DCST. It adopts data-driven colour transform and spatial transforms based on statistical properties of image pixels and machine learning. To match the data-driven forward transform, we propose a quantization table based on the human visual system (HVS). Furthermore, to efficiently compensate for the quantization error, a machine learning-based inverse transform is used. The performance of our new design is verified using the Kodak image dataset. The optimal inverse transformation can achieve 0.11-0.30dB over the standard JPEG over a wide range of quality factors. The whole pipeline outperforms JPEG with a gain of 0.5738 in the BD-PSNR (or a decrease of 9.5713 in the BD-rate) from 0.2 to 3bpp.
the colour input: previous standard use YCbCr as input which is ideal if viewed from statics while not optimal for every single image. In our case, we trained a PCA for every single image to perform color transformation which gives better de-correlate performance;
(2D)^2 PCA [1] transformation and corresponding quantization matrix designed based on the PCA kernel and HVS [2];
Machine learning inverse transform: which uses linear regression to compute the optimal inverse transform kernel for both color conversion and spatial to spectrum transform. This idea helps to estimate the quantization error and results from a better inverse result. Comparing with the previous method which compensates this error using probability mode during the post-processing stage. The ML-inverse transformation would take less time during the decoding [...]