Author: Harshad Kadu, Jian Li, and C.-C. Jay Kuo
Research Problem
Detecting text regions in natural images is an important task for many computer vision applications like compound video compression, optical character recognition, reading text for visually impaired subjects, robotic navigation etc. We are trying to solve this text localization problem, also known as the compound image segmentation problem. Contrary to the scanned documents, text in natural images may have different sizes, fonts, orientations, colors and foreground or background illumination. The cluttered background in natural images may also pose a serious threat to the accuracy of the text localization algorithms. So the compound image segmentation is inherently a difficult problem to solve.
Main Ideas
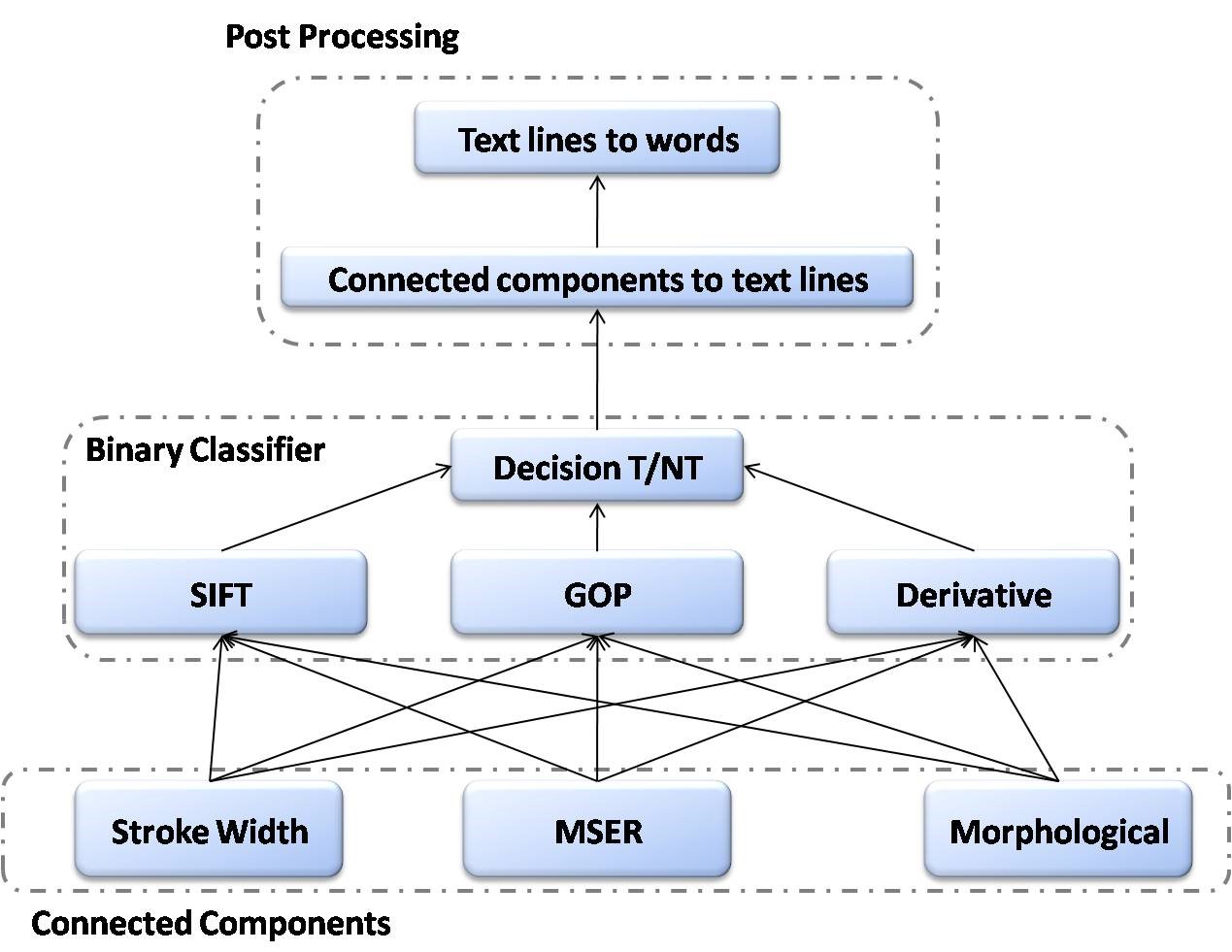
In our research, we propose a novel text localization scheme based on the fusion of diverse local operators such as, the morphological detector, maximally stable extremal regions (MSER) blob analyzer [3, 4], distance transform and stroke-width transform [2]. These operators investigate different peculiar characteristics of text to discover regions with possible textual content. An ensemble of trained SVM classifiers categorizes these regions into text or non-text using the local feature information. Finally a fragment grouping mechanism merges these text candidates together and carves out individual words. Refer to the figure below.
Innovations
Our proposed fusion technique uses a novel three-tier framework to systematically separate out the individual words in the images. The text regions have some peculiar properties which distinguish them from the non-text regions. To gain insights, we explore these properties using our novel morphological text detector. Apart from the aforementioned operator we also use some existing detectors such as, the MSER [3, 4] and stroke width transform [2] to improve the detection accuracy. We hope to get a significantly enhanced performance using this fusion framework.
Future Challenges
The future work items are listed below:
- Find a new detector solely based on the distance transform technique to improve the accuracy
- Recognize the words in the images using the integrated optical character recognition system
- Incorporate an intelligent dictionary based system to auto-complete partial detections
References
- [1] S. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong and R. Young, “ICDAR 2003 Robust Reading Competitions” In 7th International Conference on Document Analysis and Recognition 2003.
- [2] B. Epshtein, E. Ofek, Y. Wexler, “Detecting Text in Natural Scenes with Stroke Width Transform” In CVPR 2011 pp 2963-2970.
- [3] J Matas, O Chum, M Urban, and T Pajdla. Robust wide-baseline stereo from maximally stable extremal regions. 22(10):761-767, 2004.
- [4] Chen Huizhong, et al. “Robust text detection in natural images with edge-enhanced maximally stable extremal regions.” Image Processing (ICIP), 2011 18th IEEE International Conference on. IEEE, 2011.
- [5] Harshad Kadu, Maychen Kuo, and C.-C. Jay Kuo. Human motion classification and management based on mocap data analysis. In Proceedings of Joint ACM workshop on Human gesture and behavior understanding. ACM Multimedia, December 2011.
