Congratulations to Aolin Feng for passing his defense! Aolin’s thesis is titled “Green Image Coding: Principle, Implementation, and Performance Evaluation.” Here is a brief summary of his thesis:
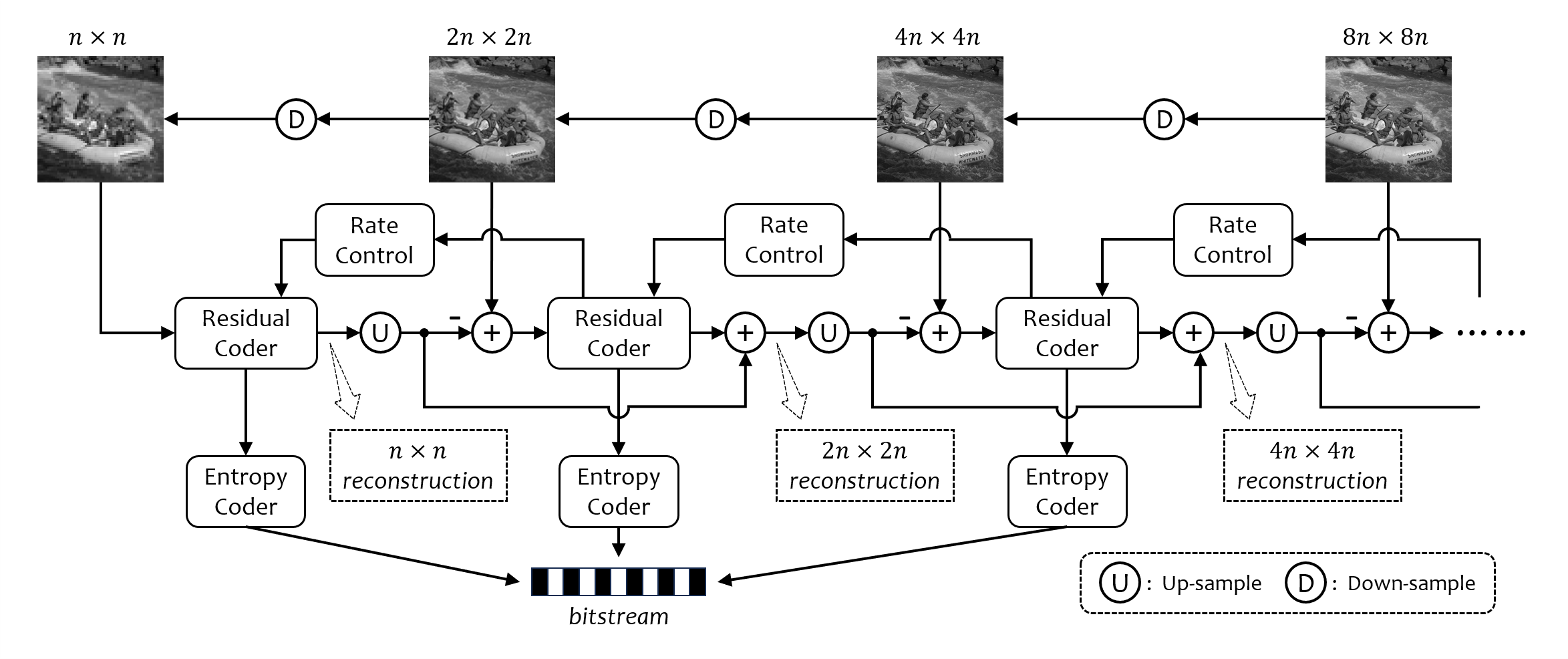
This research introduces Green Image Coding (GIC), a novel framework for lightweight, modular, and scalable image compression founded on two pillars: multi-grid representation and vector quantization (VQ). Multi-grid representation decomposes images into hierarchical layers to reduce intra-layer content diversity, while VQ-based techniques encode each layer.
For the multi-grid representation pillar, we propose a multi-grid rate control theory that reduces high-dimensional optimization to sequential parameter decisions. Driven by this theory, a slope-matching-based rate control strategy is designed to improve scalability and rate-distortion (RD) balance. For the VQ pillar, we develop a suite of advanced techniques for efficient, scalable encoding: an RD-oriented codebook construction method built on tree-structured VQ (TSVQ) for multi-rate coding; a cascade VQ strategy to prevent early convergence in high-dimensional VQ; and a quadtree (QT) structure that combines multi-dimensional VQs, optimized via an iterative method to overcome statistical issues during rate-distortion-optimization (RDO).
Architecturally, the thesis evaluates single-grid versus multi-grid paradigms and analyzes independent parallel VQ versus residual-based cascade VQ regarding train-test match and content adaptivity. To mitigate compression artifacts, we propose a multi-tiered enhancement pipeline that decouples block-level structural learning (using residual VQ) from pixel-level refinements (using CNN-based post-processing).
Experimental results demonstrate that GIC achieves competitive coding efficiency with low theoretical complexity. Its modular, interpretable design offers strong potential for future improvement, functioning effectively as an extension module for existing codecs or as a foundation for future video coding research.