Author: Xiang Fu, Sanjay Purushotham, Daru Xu, and C.-C. Jay Kuo
Research Problem
Rapid development of video sharing over the Internet creates a large number of videos every day. It is an essential task to organize or classify tons of Internet images or videos automatically online, which will be mostly helpful to the search of useful videos in the future, especially in the applications of video surveillance, image/video retrieval, etc.
One classic method to categorize videos for human is based on which makes content-based video analysis a hot topic. An object is undoubtedly the most significant component to represent the video content. Object recognition and classification plays a significant role for intelligent information processing.
The traditional tasks of object recognition and classification include two parts. One is to identify a particular object in an image from an unknown viewpoint given a few views of that object for training, which is called “multi-view specific object recognition”. Later on, researchers attempt to get the internal relation of object classes from one specific view, which develops to another task called “single-view object classification”. In this case, the object class diversity in appearance, shape, or color should be taken into consideration. These variations increase the difficulty in classification. Over the last decade, many researchers have solved the last two tasks using a concept called intra-class similarity. To further reduce the semantic gap between machine and human, the problem of “multi-view object classification” needs to be well studied.
As shown in Fig.1, there are three elements to define a view: angle, scale (distance), and height, which form the view sphere. Although the viewpoint as well as intra-class variations exist as illustrated in Fig.2, some common features can still be found for one object class by a certain technique. The question is how to get the discriminant common features for each object class and how to represent these features effectively.
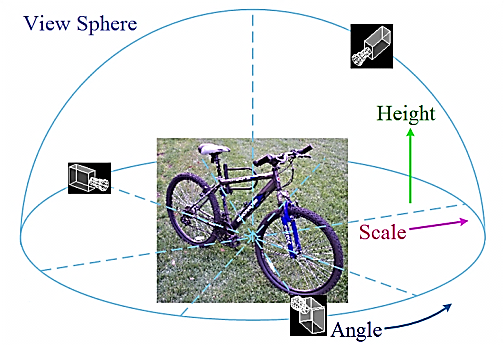
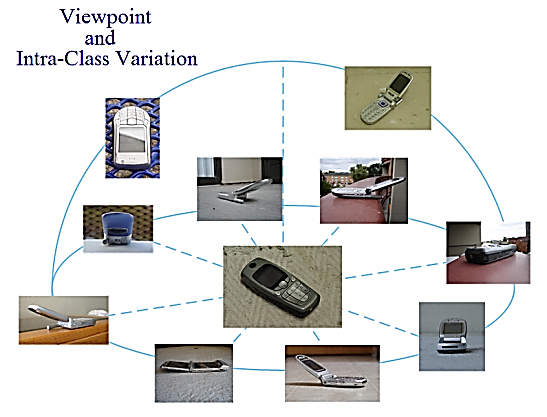
It is difficult to build a model to represent each object class for all views. In other words, it is impossible to represent all features from different views in one model since they do not appear concurrently. On the other hand, it is expensive to make too many models for one object class even if differences always exist from different views. In addition, some object classes are so distinctive from others, which makes the complete BoW model representation wasteful in terms of storage and computation.
Main Ideas
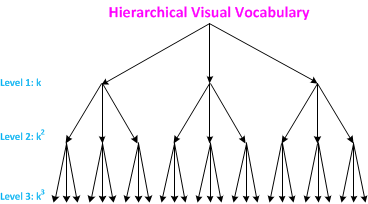
To address these issues, we propose a novel hierarchical BoW (HBoW) model that provides a concise representation of each object class with multi-views. There are totally L levels in this model, shown in Fig. 3. The number of words at the next level is k (k >= 2) times of that at the current level. The parameter k is called the branching factor. Initially, there are k words at level 1 and there are kl words at level l. The centroid of each clustered subgroup represents the corresponding word at that level. For each subgroup, all children feature descriptors are clustered into k groups at the second level and there are totally k2 words at level 2. Afterwards, the same process is recursively applied until the maximum level L is reached.
The advantage of our hierarchical Bag-of-Words model is that when the higher level BoW representation does not match with that of the query instance, further comparison can be saved. We can also incorporate similar views to reduce the storage space. View reduction can be used to remove view redundancy in an object class. The cosine similarity measure takes the value from 0 to 1. We partition the values into three intervals with two thresholds, i.e., Tdown and Tup. When the similarity value is from 0 to Tdown (not similar), we keep both views in the model. When the similarity value is from Tdown to Tup (marginally similar), we merge these two views. Finally, when the similarity value is from Tup to 1 (quite similar), we discard one of the two views.
The main contributions of this project include the following three points:
- We propose a hierarchical BoW model to effectively represent each object class using different levels. This model produces a compact yet powerful representation for each object class with a flexible number of levels depending on its shape and geometric appearance complexity. It largely reduces the model redundancy of the traditional visual BoW model.
- We develop a local-comparison method to build up the model to decrease the computational cost from O(kn) to O(kn), where k>2 is a constant.
- We describe a rule to reduce the view redundancy of each object class according to its view similarity. It efficiently represents an object class with fewer views.
Innovations
Many researchers attempted to solve the “multi-view object classification” problem in the last decade. Generally speaking, there are three main approaches as detailed below.
The first one is to use as many view samples as possible to model an object class for the whole view sphere. This method can yield precise models for each object class as long as the number of views is sufficient, but it is limited to a few discrete viewpoints in the training process practically. The systems cannot deal with new viewpoints that have not been trained before. Thomas [4] built a bucket model to support the general conditions of viewpoints distributed over the view sphere, and established links between adjacent views of the same object class with this concept.
The second one is to establish a 3D representation using connections from a 2D training set. This approach has little confidence on images with high angle variation, not to speak of unseen object even in the same class. Among them, Su [5] proposed a part-based probabilistic model to learn affine constraints between object parts. Savarese [6] formed the 3D object class model by connecting the canonical parts in the 3D space.
The third one is feature resorting on existing 3D models. It suffers from rendering artifacts and causes large differences between real images and synthetic models. In [7], patches were collected from multiple 2D training images and labeled on an existing 3D CAD model. They utilized the model views (multi-view specific object) as bridges to connect the supplemental views (multi-view same class object) to the model and constructed a codebook by combining all the mapped features with 3D locations. Liebelt [8] established a link between 3D geometry and local 2D image appearance using synthetic CAD models.
Li [9] produced two kinds of models for objects in the Semantic Robot Vision Challenge in 2007. For objects with little intra-class variation such as branded items and books, the model could be simplified by learning. A template matching could be applied to separate them from others. For general objects with high intra-class variation such as chair, bag, or computer, we need more training to create a more general model. To reach a wider range of applications, we focus on generic object classification in this work.
Here, instead of building complicated 3D appearance model or connections on spatial restriction, we modify the fundamental local feature representation in an efficient way. In particular, we consider the characteristics of an object class and determine the object model cost according to its overall structural complexity. Furthermore, we integrate the shared features among different views depending on the object appearance similarity, which will reduce the view redundancy on the model representation.
Demo and Simulation Results
The experiments in this section are conducted based on the 3D Object Categories of the Caltech dataset [6], which consists of ten common object categories, including bike, car, cell phone, head, iron, monitor, mouse, shoe, stapler, and toaster as shown in Fig. 4. For each object category, there are ten object instances with 72 viewpoints, 8 angles, 3 heights, and 3 scales (distances). The total number of images is around 7000. There are only 48 viewpoints for the car object. All images are of the bmp format with size around 400*300. All objects are located in the center of each image.

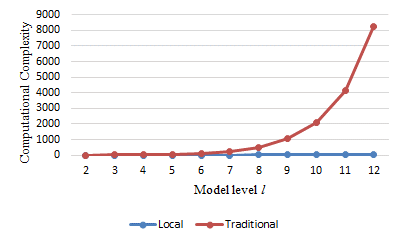
We compare the computational complexity of visual word matching using the traditional-comparison method and the local-comparison method that have the same number of visual words in Fig. 5. It is clear that the local-comparison method has a much lower complexity. This is especially obvious when the hierarchical BoW model has a higher level number.
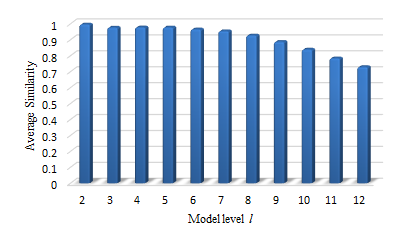
Furthermore, we use cosine similarity to see the model difference between these two methods for the same feature points. As shown in Fig. 6, the average similarity between these two methods decreases as the level, l, of the hierarchical BoW increases. When L = 12, the average cosine similarity is still above 0.7. This indicates that the local-comparison method still has a good approximation capability with low complexity even with a high level.
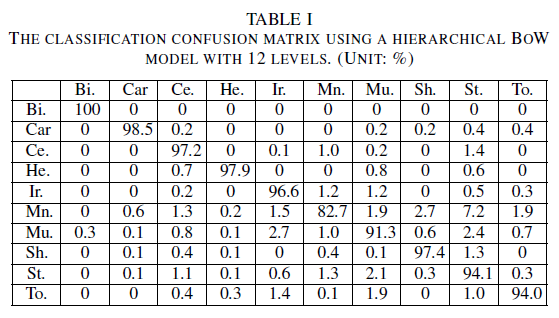
The average accuracy for the whole dataset is 94.82%. In Table I, for a hierarchical BoW model with a level number lower than 8, the average accuracy is lower than 60% (e.g., 58.92% for the 7-level model). However, the level number depends on the object type. To achieve comparable classification performance, some need more levels while others need less. Thus, we may adopt different level numbers for different models according to their appearance.
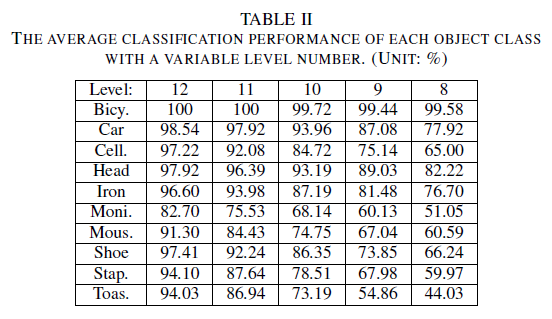
In Table II, we list the average classification accuracy for each object class using a variable level number, where the level number ranges from 8 to 12. As shown in Table II, the performance improvement between two adjacent levels varies from around 1% to over 10%. To save the storage cost while maintaining good classification performance, we adopt the 8-level model for bicycle, the 10-level model for car and head, the 11-level model for cell, iron, and shoe, and the 12-level model for monitor, mouse, stapler, and toaster. Although the classification performance degrades from 94.82% to 92.72%, the saving of the storage cost is more than 39.38%.
We show the similarity matrix between different views, scales, heights and angles in Fig. 7. The value in the matrix ranges from 0 to 1, which is calculated using the cosine similarity. Clearly, all diagonal elements are ones. We use a gray-level map to represent the cosine similarity from 0 (black) to 1 (white). The similarity matrix of the bicycle object is shown in Fig. 9 (a), where view angles 1 and 5 correspond to the front and the back of the bicycle respectively, and other angles are side views. Due to the 180-degree symmetry, view angles 1 and 5 are similar to each other. View angles 2, 3, 4, 6, 7, 8 are similar to each other. The similarity matrix for the car object is shown in Fig. 7 (b), where view angles 3 and 7 offer the side (the left and the right) view of the car. These symmetric properties allow view reduction.

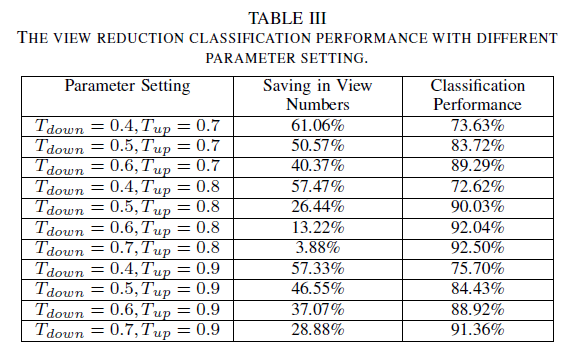
The classification accuracy and its corresponding saving in view numbers are shown in Table III. We partition the cosine similarity measure into three intervals with two thresholds, i.e. Tdown and Tup. From Table III, when Tdown is 0.5 and Tup is 0.7, more than half of the views are saved while the classification performance reduces around 10% only. Therefore, view reduction is an effective method to reduce the model complexity.
Future Challenges
There are several directions on muli-view object representation and classification for future works.
- Add more multi-view object classes for the dataset.
- Additional intra-variance for each object class.
- Put segmentation module ahead to reduce the negative influences from background.
- Design adaptive parameters for hierarchical Bag-of-Words models and view reduction.
References
- [1] H. Chiu, “Models for Multi-View Object Class Detection,” PhD Thesis in Massachusetts Institute of Technology, June 2009.
- [2] H. Jegou, M. Douze, and C. Schmid, “Improving Bag-of-Features for Large Scale Image Search,” in IJCV, vol. 87, pp. 191-212, May 2010.
- [3] S. Zhang, Q. Huang, G. Hua, S. Jiang, W. Gao, and Q. Tian, “Building Contextual Visual Vocabulary for Large-Scale Image Applications,” in ACM Multimedia, Oct. 25-29, 2010.
- [4] A. Thomas, V. Ferrari, B. Leibe, T. Tuytelaars, B. Schiele, and L. V. Gool, “Towards Multi-View Object Class Detection,” in CVPR, June 2006.
- [5] H. Su, M. Sun, L. Fei-Fei, and S. Savarese, “Learning a Dense Multi-View Representation for Detection, Viewpoint Classification and Synthesis of Object Categories,” in ICCV, Sep. 29-Oct. 2, 2009.
- [6] S. Savarese and L. Fei-Fei, “3D Generic Object Categorization, Localization and Pose Estimation,” in ICCV, Oct. 14-20, 2007.
- [7] P. Yan, S. M. Khan, and M. Shah, “3D Model Based Object Class Detection in An Arbitrary View,” in ICCV, Oct. 14-20, 2007.
- [8] J. Liebelt and C. Schmid, “Multi-View Object Class Detection with a 3D Geometric Model,” in CVPR, June 13-18, 2010.
- [9] L. Li, J. C. Niebles, and L. Fei-Fei, “OPTIMOL: a framework for Online Picture collecTion via Incremental Model Learning,” in the Association for the Advancement of Artificial Intelligence (AAAI) 2007 Robot Competition and Exhibition, July 22-26, 2007.



