MCL Director, Professor C.-C. Jay Kuo, visited Nanjing, Hefei and Zhuzhou in the week of October 7-13.
Professor Kuo’s visit to Nanjing University on October 8 (Tuesday) was invited and hosted by Professor Zhi-Hua Zhou, Dean of School of Artificial Intelligence and Head of Department of Computer Science and Technology, Nanjing University. Professor Kuo delivered a seminar on “From Feedforward-Designed Convolutional Neural Networks (FF-CNNs) to Successive Subspace Learning (SSL)” as part of the CSAI Distinguished Lecture Series of Nanjing University. A photo of Professor Kuo and Professor Zhou is provided.
Professor Kuo’s visit to University of Science and Technology of China on October 9 (Wednesday) was invited and co-hosted by Professor Feng Wu, Professor Houqiang Li and Professor Qibin Sun. Professor Kuo delivered a seminar on his recent work on Success Subspace Learning (SSL) to faculty and students.
At the last stop of his trip, Professor Kuo attended the Chinese Conference on Biometric Recognition (CCBR) from October 12 and 13 in Zhuzhou, Hunan, China. He was a keynote speaker of this conference and delivered a lecture on “Towards Effective and Explainable Biometrics”. The abstract of his keynote is given below.
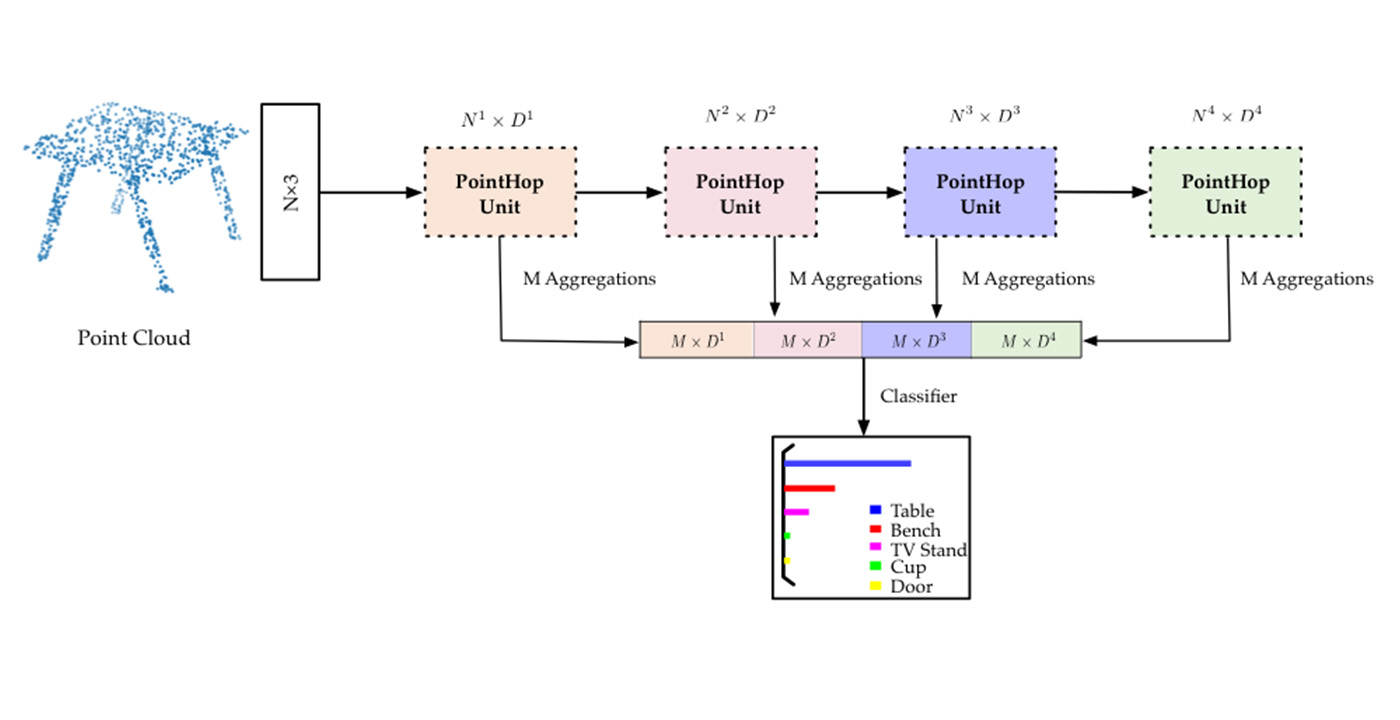
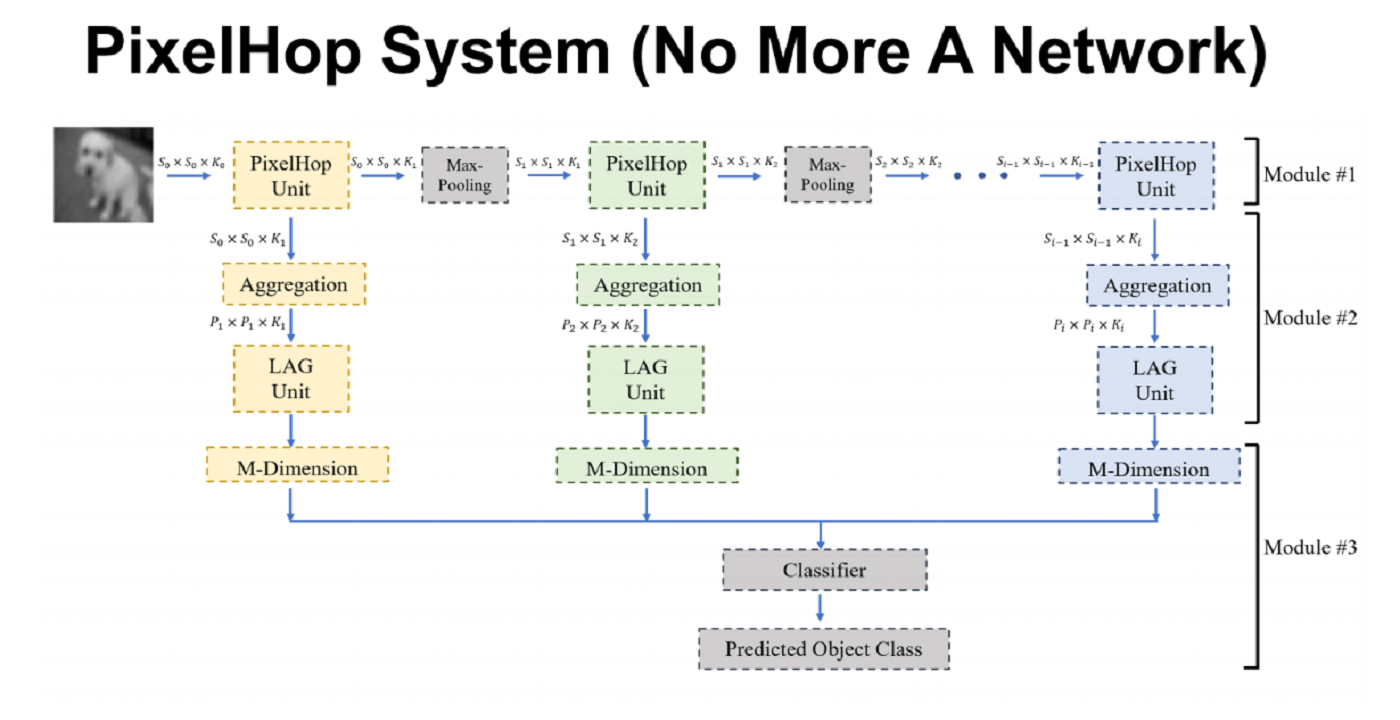
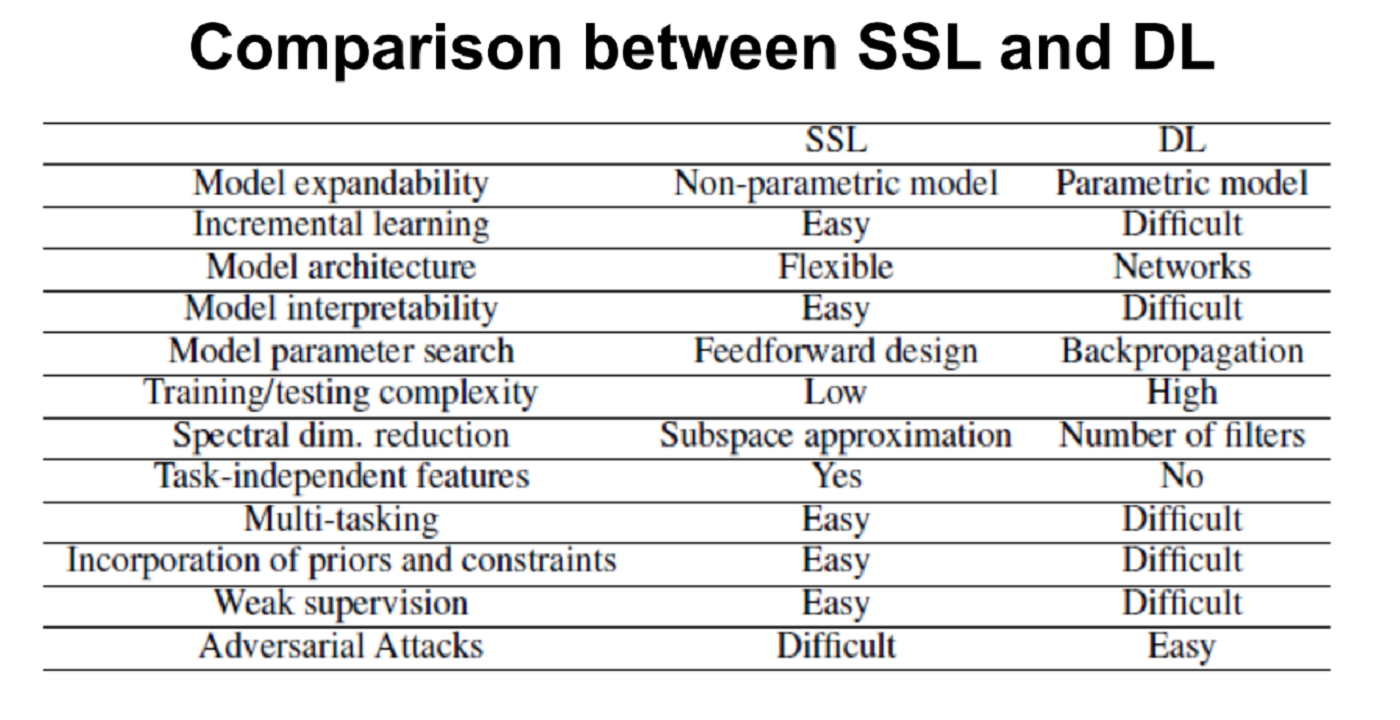
“Deep learning provides state-of-the-art biometrics solutions when training and testing data share similar distributions and the number of training samples is sufficiently larger. The deep-learning-based solutions are mathematically intractable due to the non-convex optimization nature. Furthermore, their robustness is a main concern. To search for effective and explainable biometrics solutions is challenging yet essential. In this talk, I will present a path towards this direction and provide preliminary results using face recognition as an example. Instead of treating computational neurons as hidden units whose parameters are determined by end-to-end optimization, we interpret computational neurons as dimension reduction units, [...]