
MCL Research on Camouflage Object Detection
Camouflage is an attempt to mask the object into a background image and to match its background. The term “camouflage” originates in the ancient practices of the animal kingdom, where animals would alter their body patterns, textures, and colors to blend in with their environment to evade predators. In military contexts, camouflage is a technique used to conceal soldiers or equipment within the background texture, making it difficult for the enemy to detect them. On the other hand, camouflaged object detection is a method used to uncover the enemy who has used camouflage to hide within the image texture.
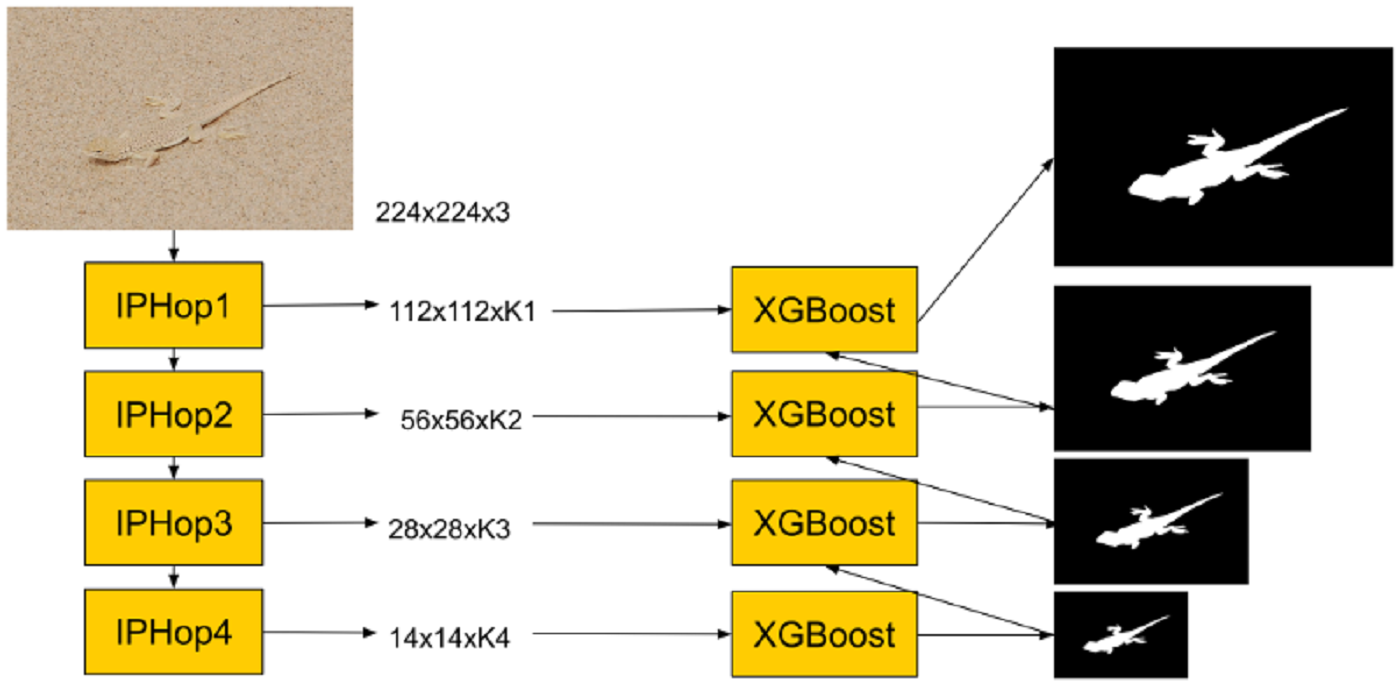
Our research objectives are to understand the problem with more insights and develop a pipeline for Camouflaged Object Detection based on the Green Learning framework. The first main technical accomplishments are multiscale color and texture decomposition; since, in this task, the texture is much more important than the color, we decouple the information of textures and colors. The second main technical accomplishment is clustering the images dataset; we cluster similar photos with the matching color histogram together and try to learn the information. It reduces the difficulty of the classifier to separate all kinds of images, and we can focus more on images with similar colors and appearance. We cluster the dataset using HSV color space, quantize the color space into 52 bins, and use K-means clustering to derive the clusters. As shown in Figure, images with similar backgrounds are grouped together. Our experiment shows that training in each subcluster could further reduce training and validation loss.
— Max Chen