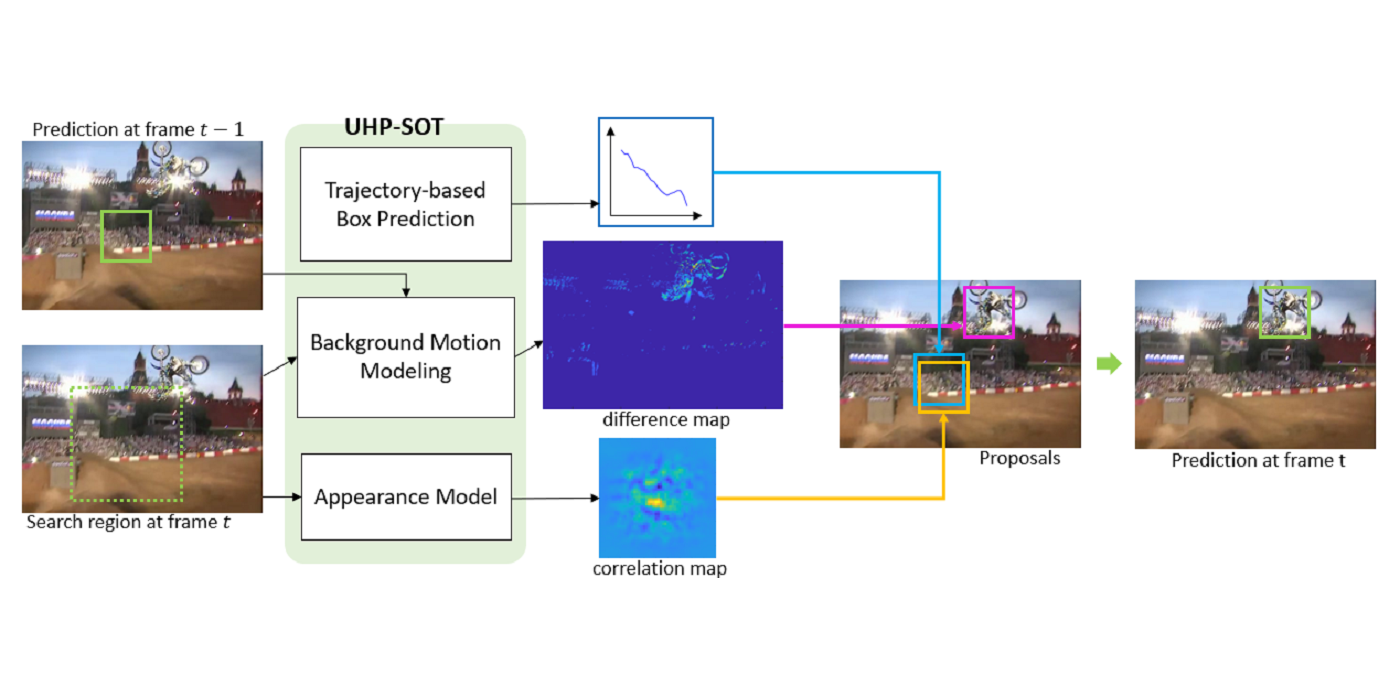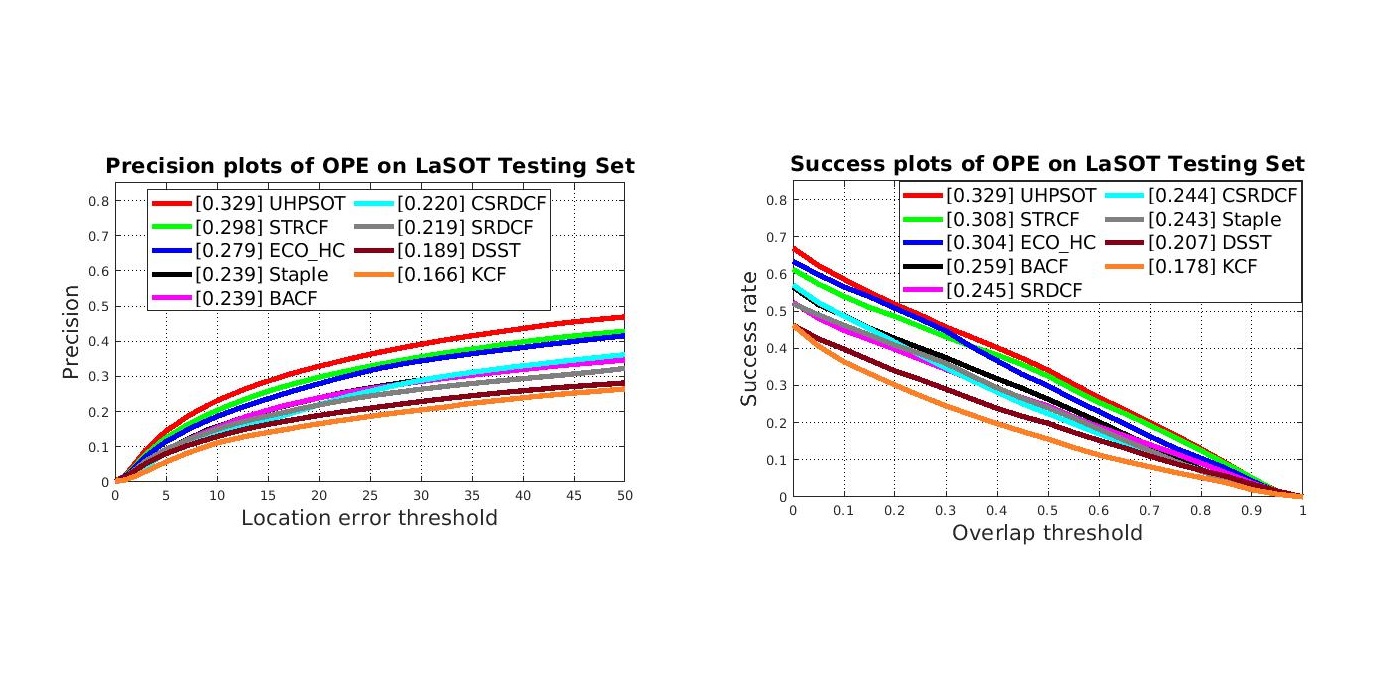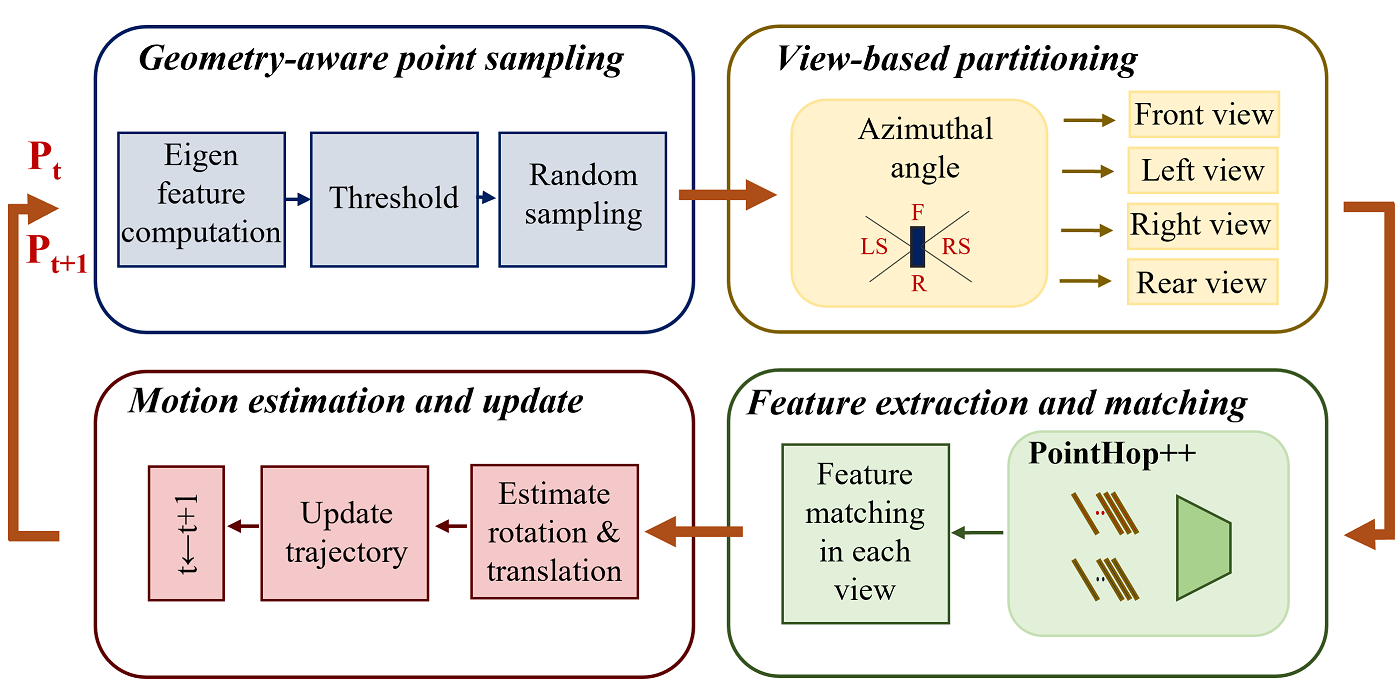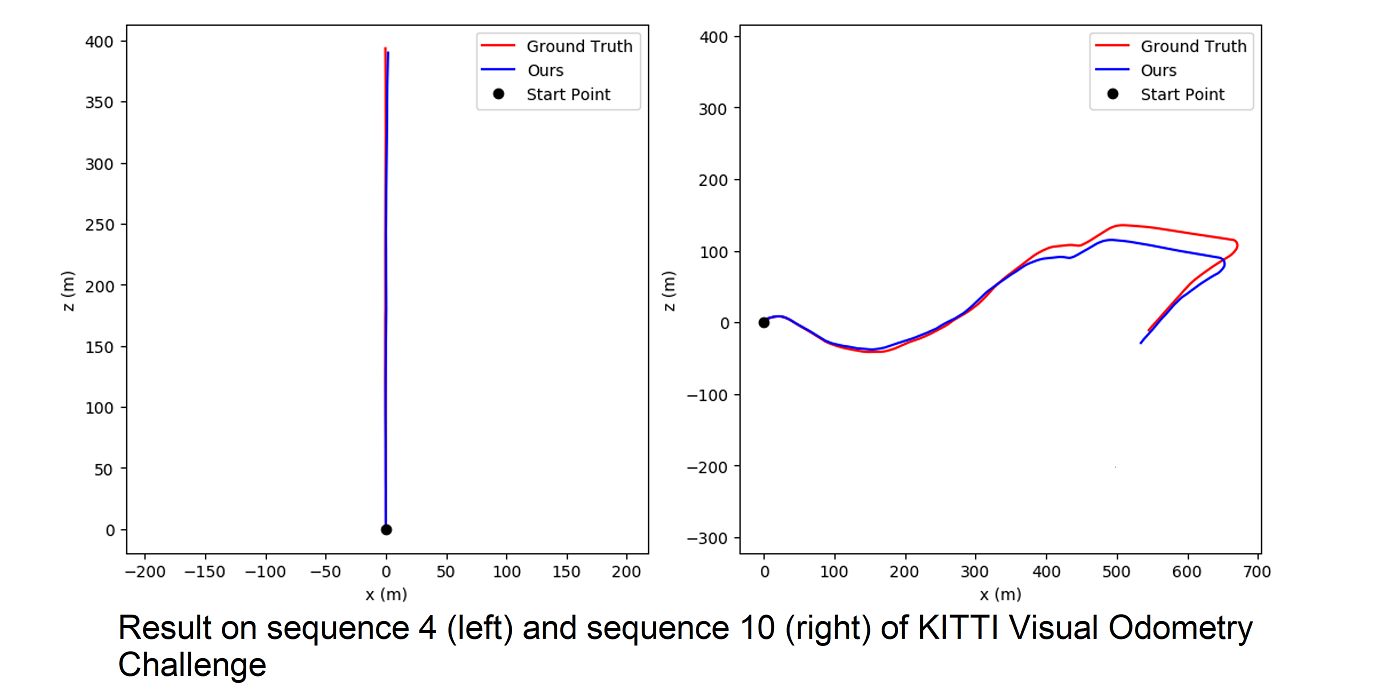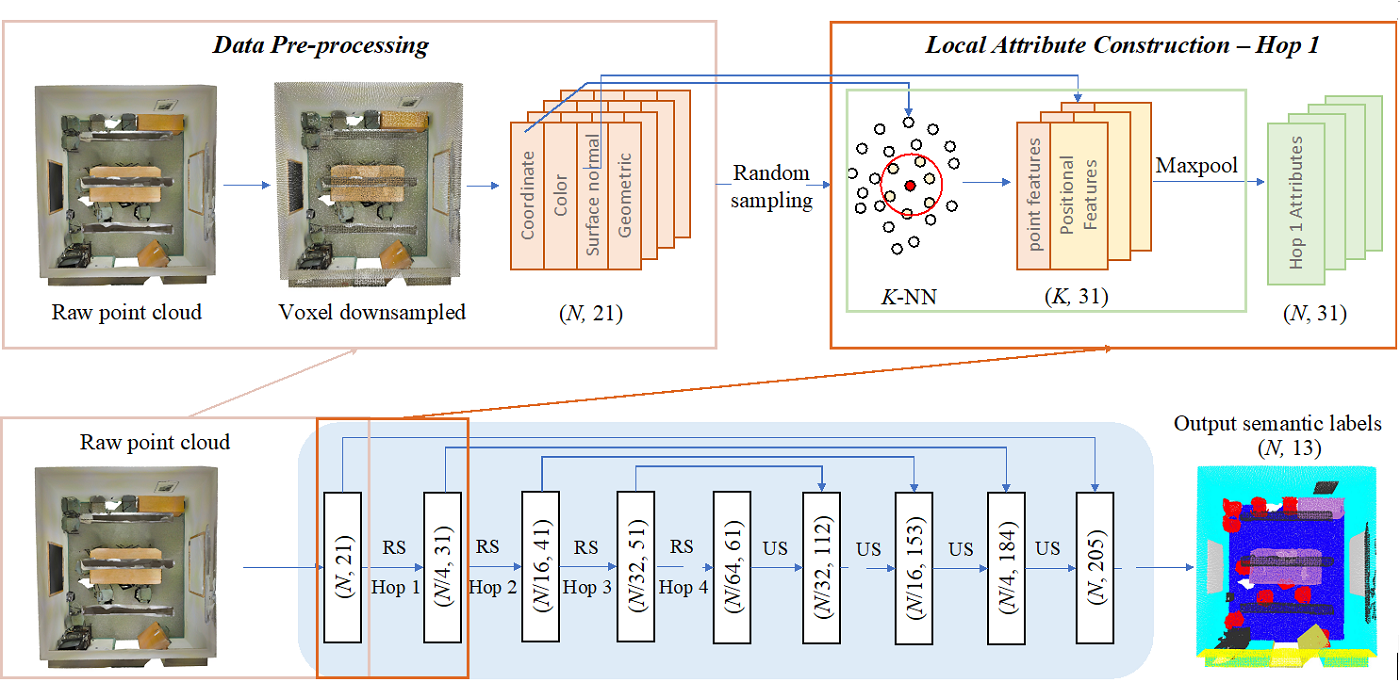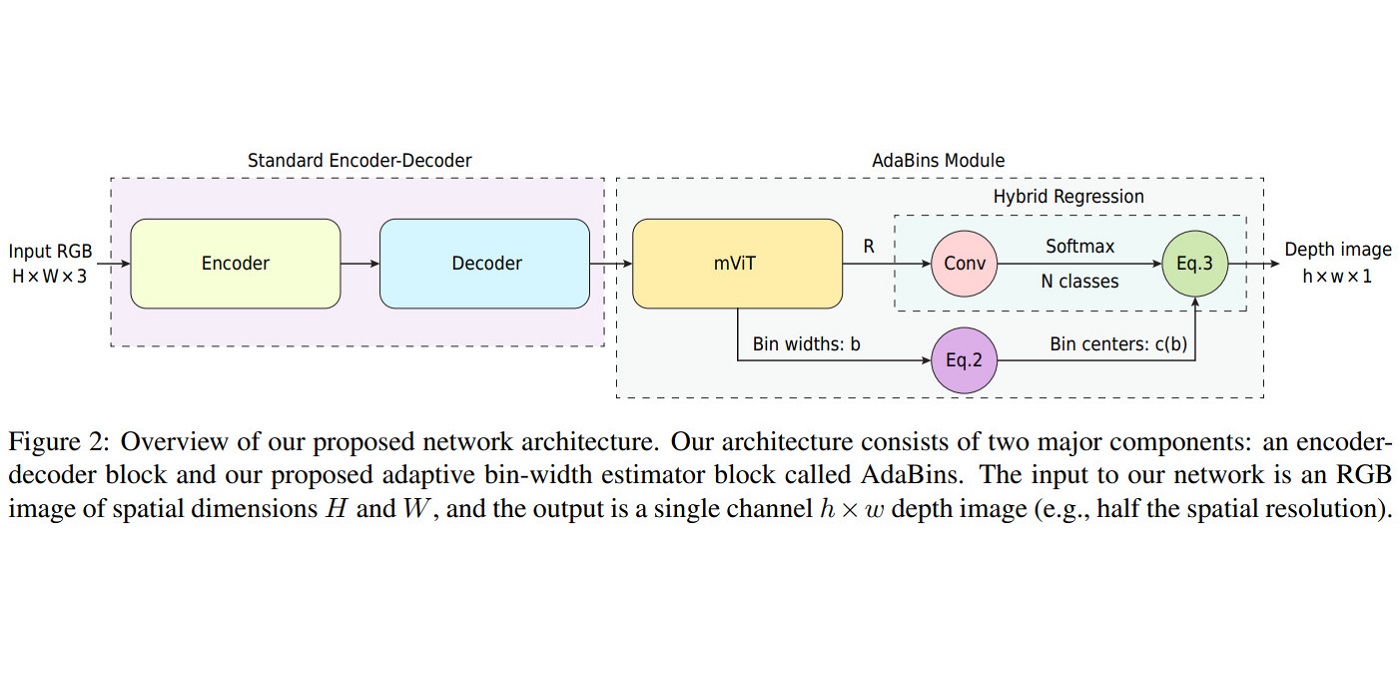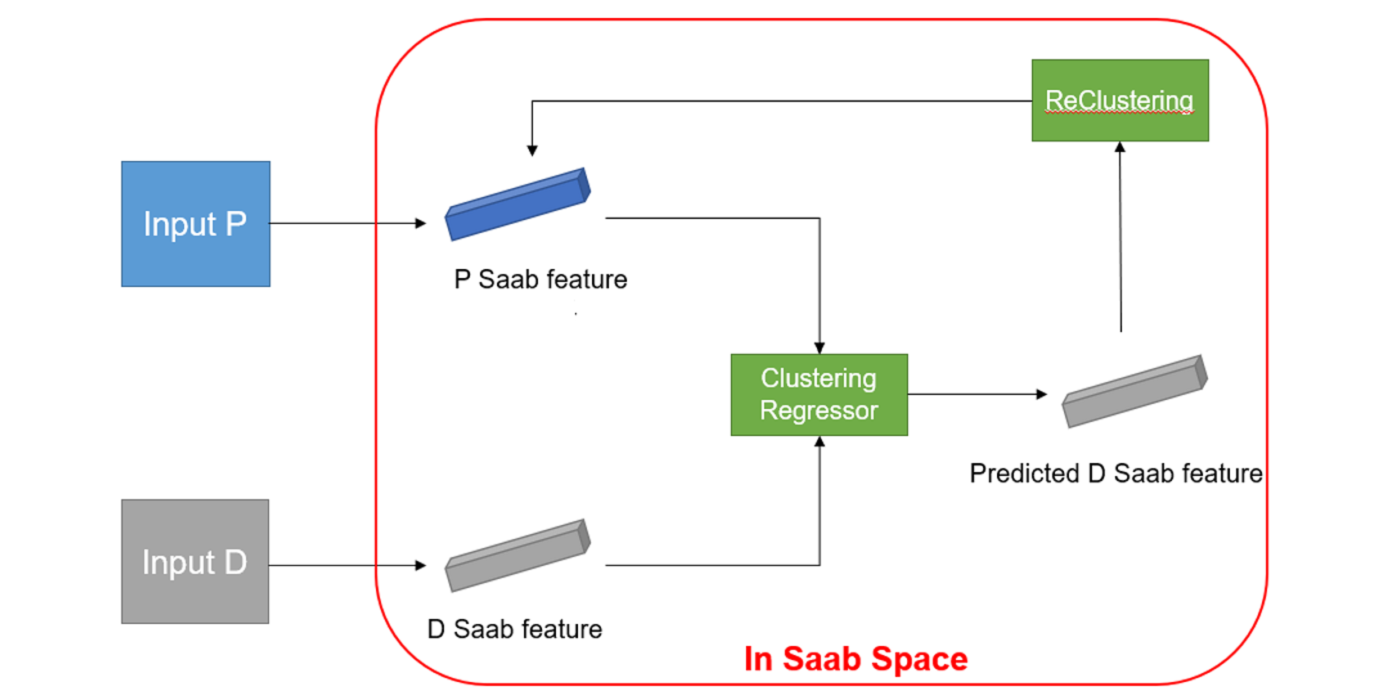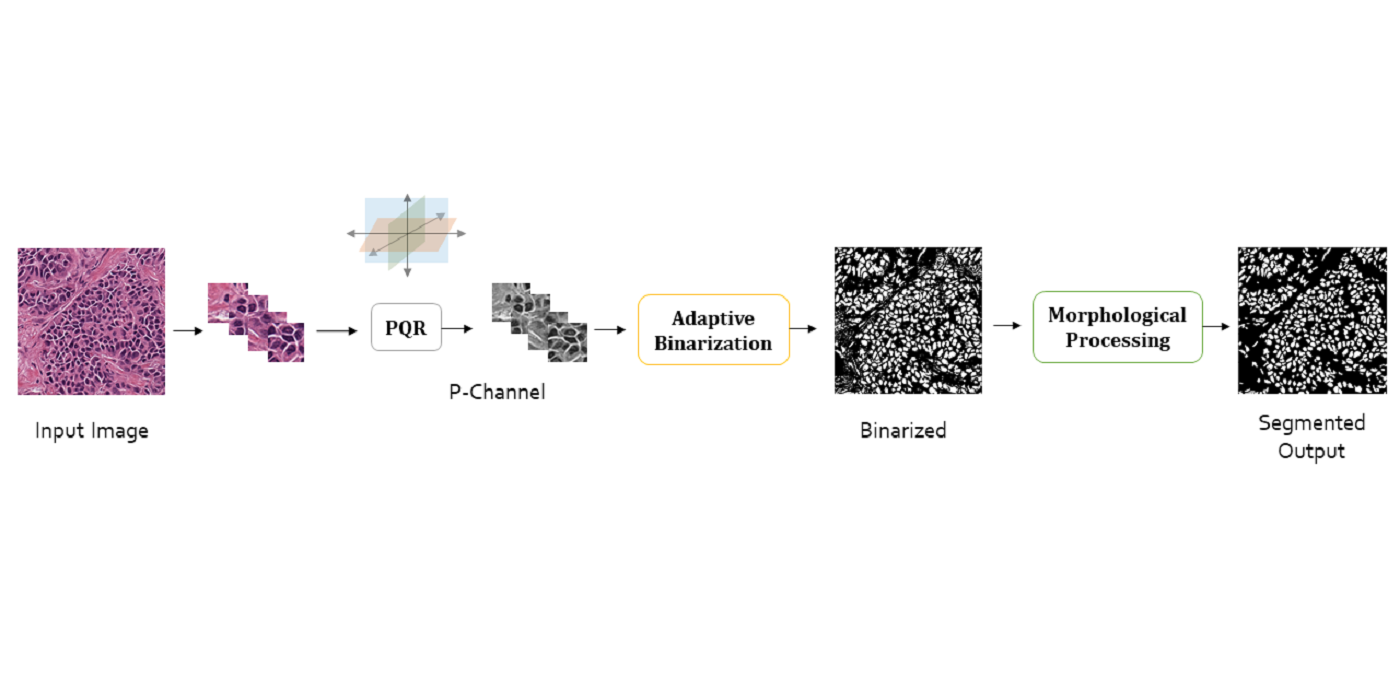
MCL Research on MRI Imaging (MRI Lung Ventilation)
Functional lung imaging is of great importance for the diagnosis and evaluation of lung diseases such as chronic obstructive pulmonary disease (COPD), asthma, and cystic fibrosis. Conventional methods often include inhaled hypopolarized gas or 100% oxygen as contrast agents. In recent years, high performance low field systems have shown great advantages for 1H lung MRI due to reduced susceptibility effects and improved vessel conspicuity. These allow possibilities to detect regional volume changes throughout the respiratory cycle.
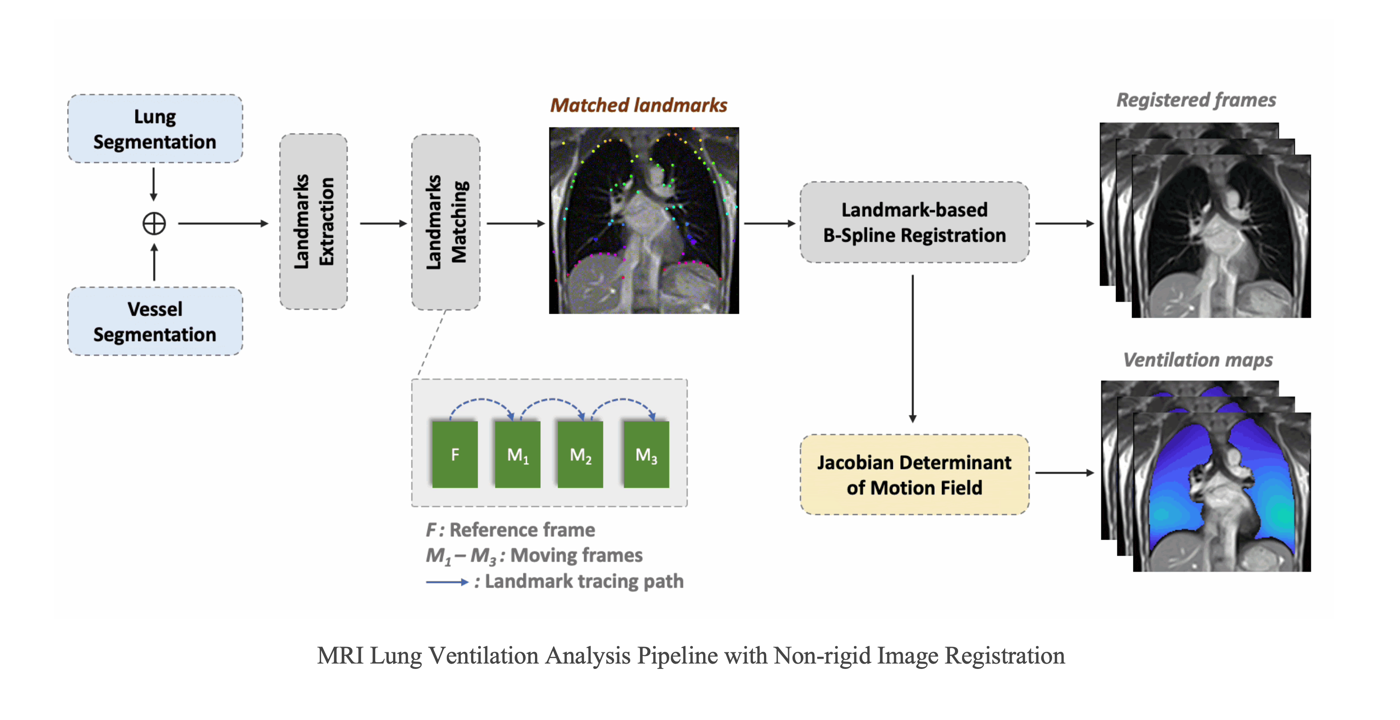
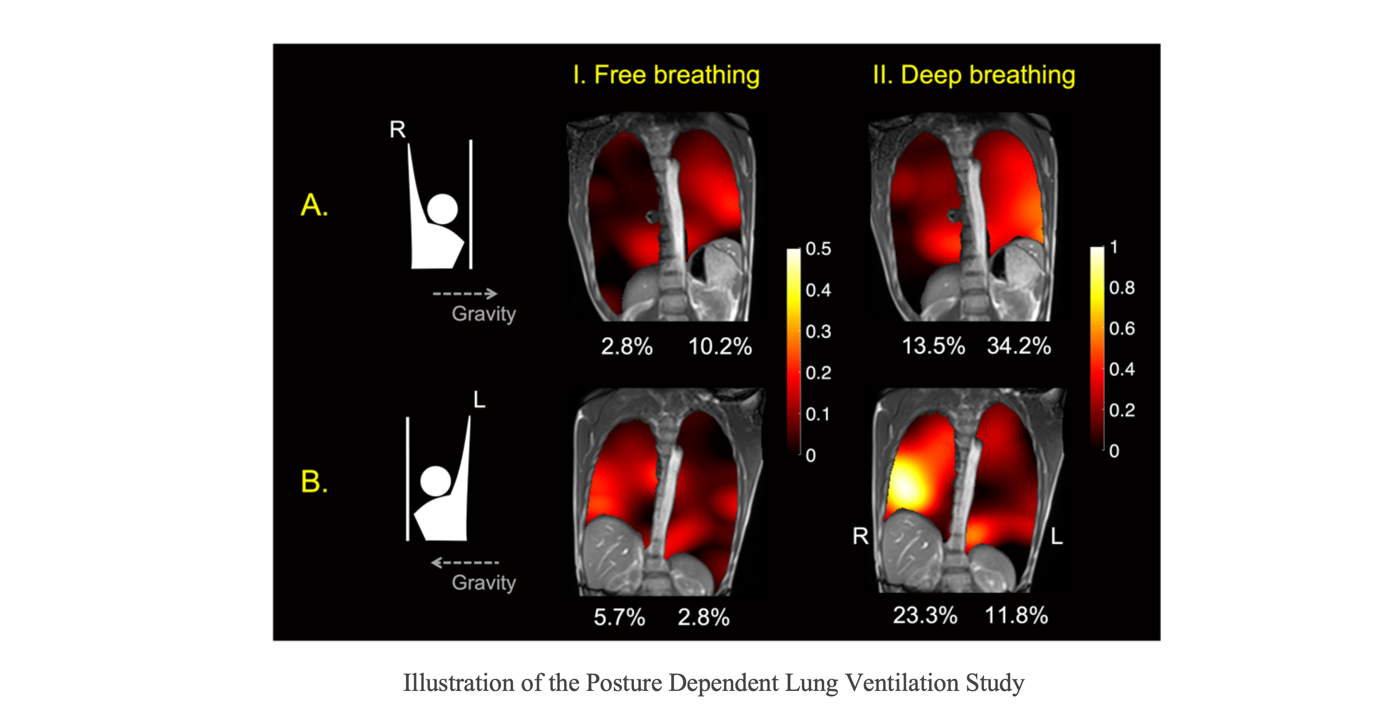
Recently, under the collabration between MCL and Dynamic Imaging Science Center (DISC), the feasibility of image-based regional lung ventilation assessment from real-time low field MRI at 0.55T is studied, without requiring contrast agents, repetition, or breath holds. A sequence of MRI in the time series with 355ms/frame temporal resolution, 1.64 x 1.64 mm2 spatial resolution, and 15mm slice thickness, captures several consecutive respiratory cycles which consist of different respiratory states from exhalation to inhalation. To resolve the regional lung ventilation based on these acquired images, an unsupervised non-rigid image registration is applied to register the lungs from different respiratory states to the end-of-exhalation. Deformation field is extracted to study the regional ventilation. Specifically, a data-driven binarization algorithm for segmentation is firstly applied to the lung parenchyma area and vessels, separately. A frame-by-frame salient point extraction and matching are performed between the two adjacent frames to form pairs of landmarks. Finally, Jacobian determinant (JD) maps are generated using the calculated deformation fields after a landmark-based B-spline registration.
In the study, the regional lung ventilation is analyzed on three breathing patterns, including free breathing, deep breathing and force exhalation. The motion and volume change for deep breathing and forced exhalation are found to be larger than the free breathing case. [...]