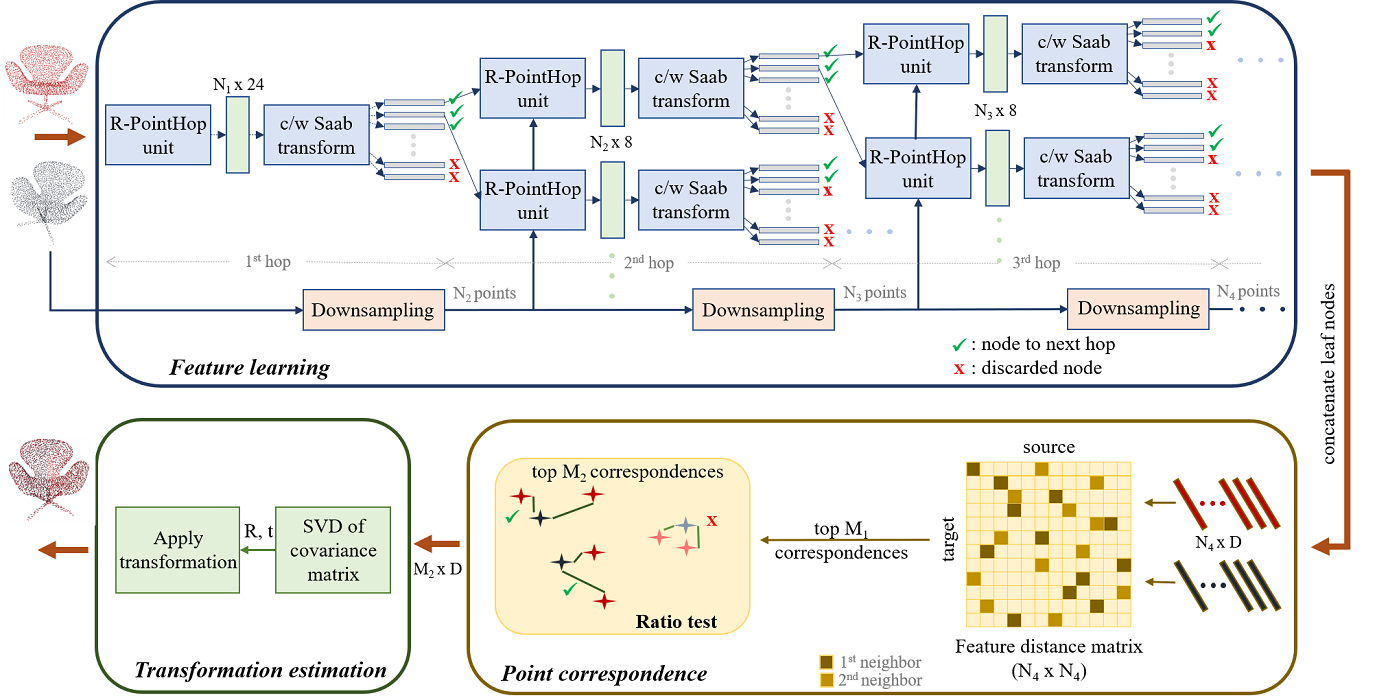
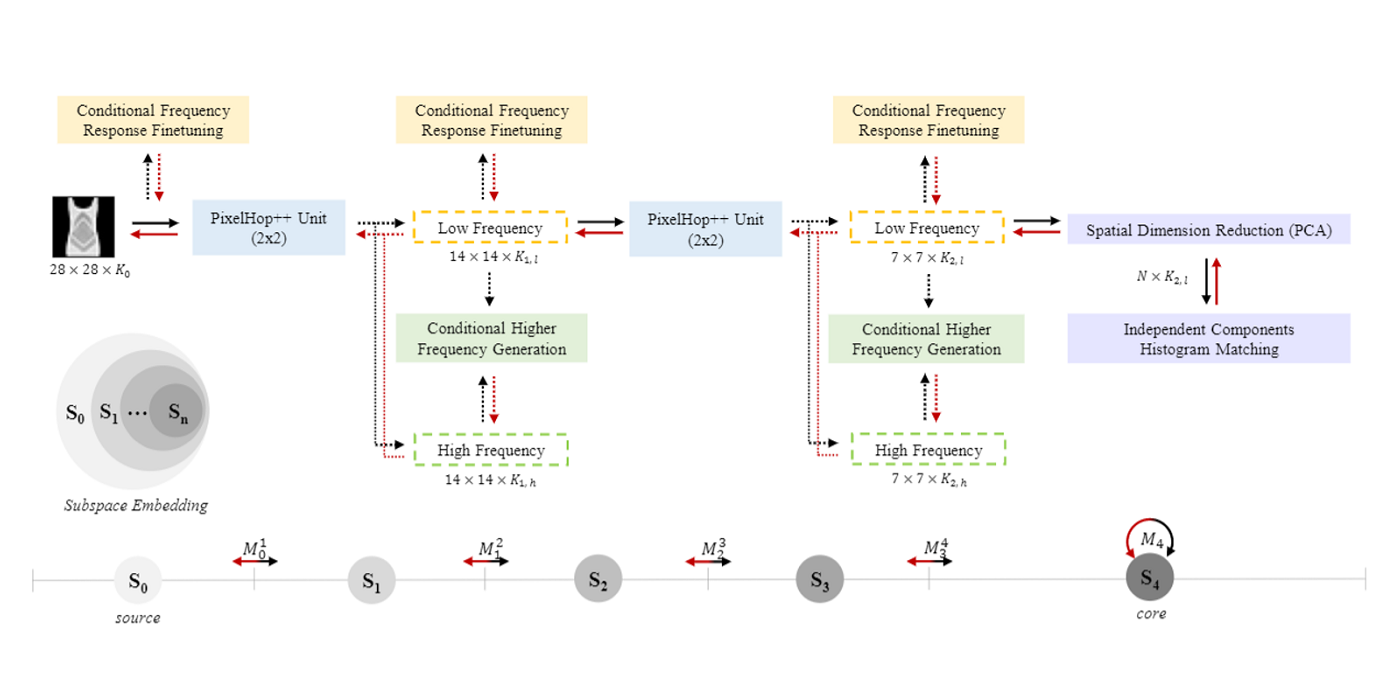
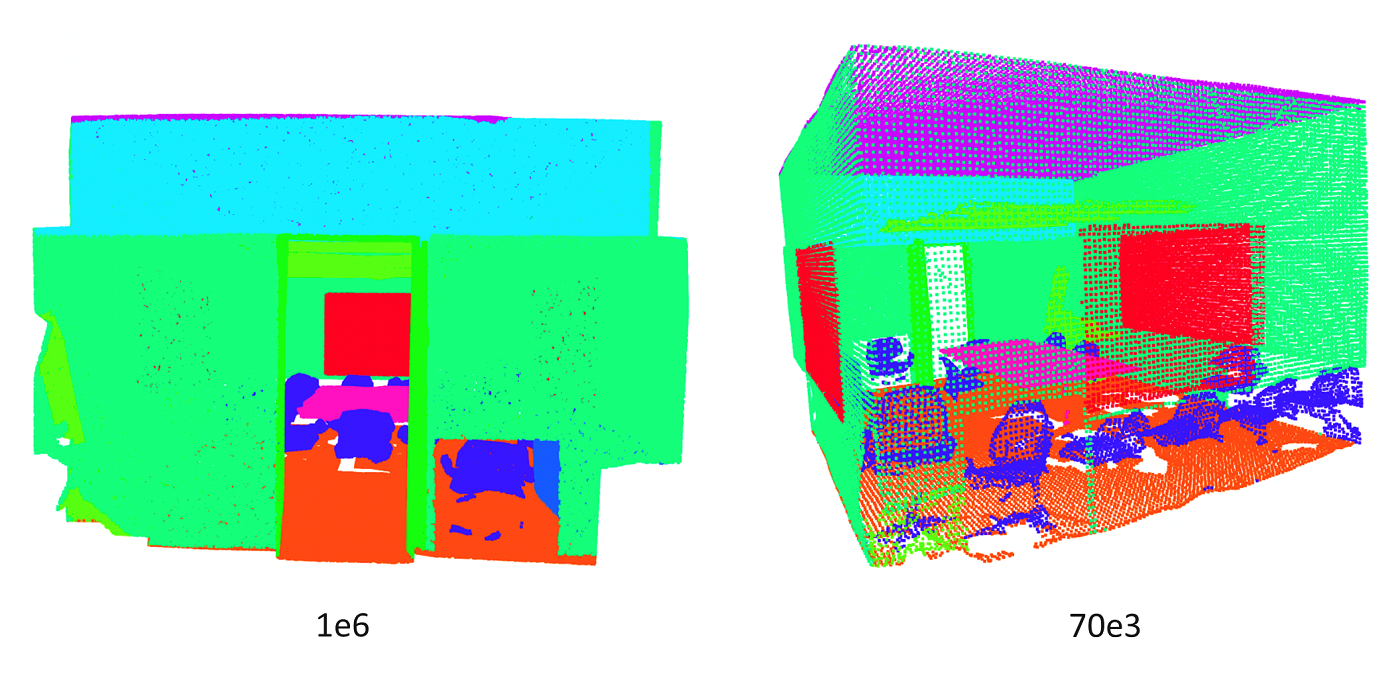
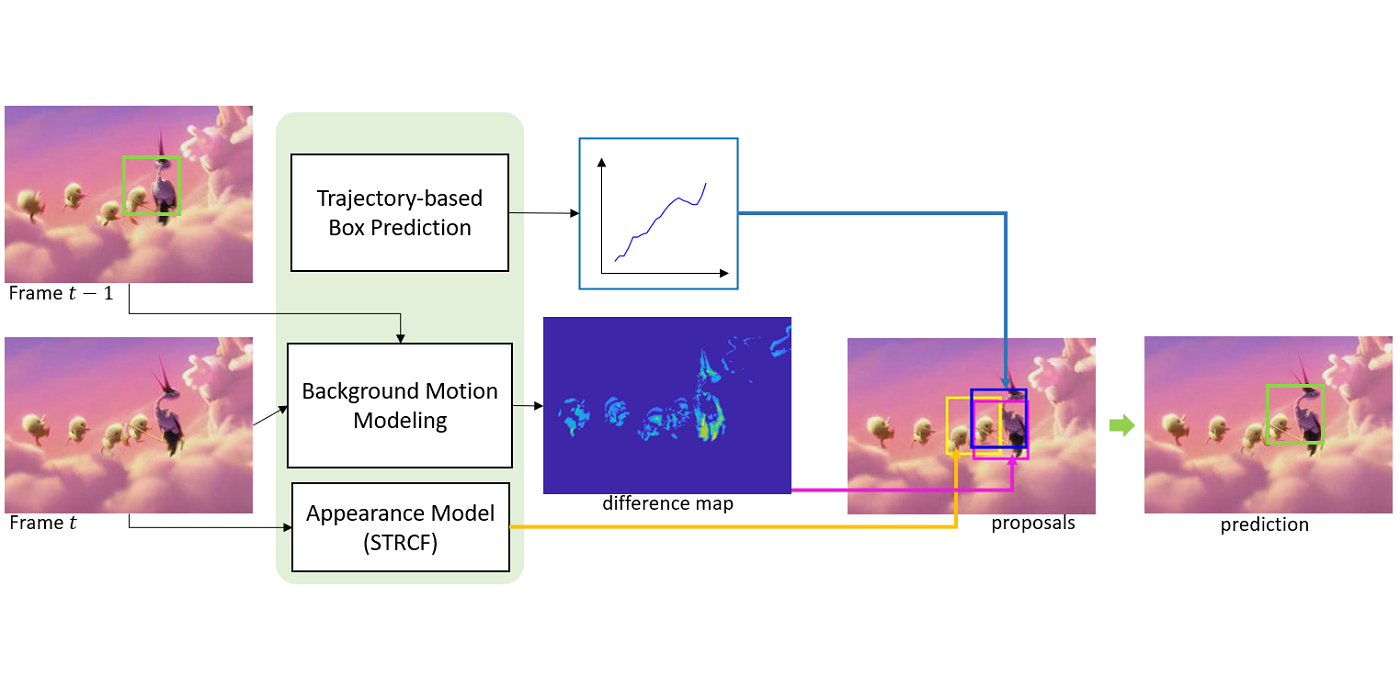
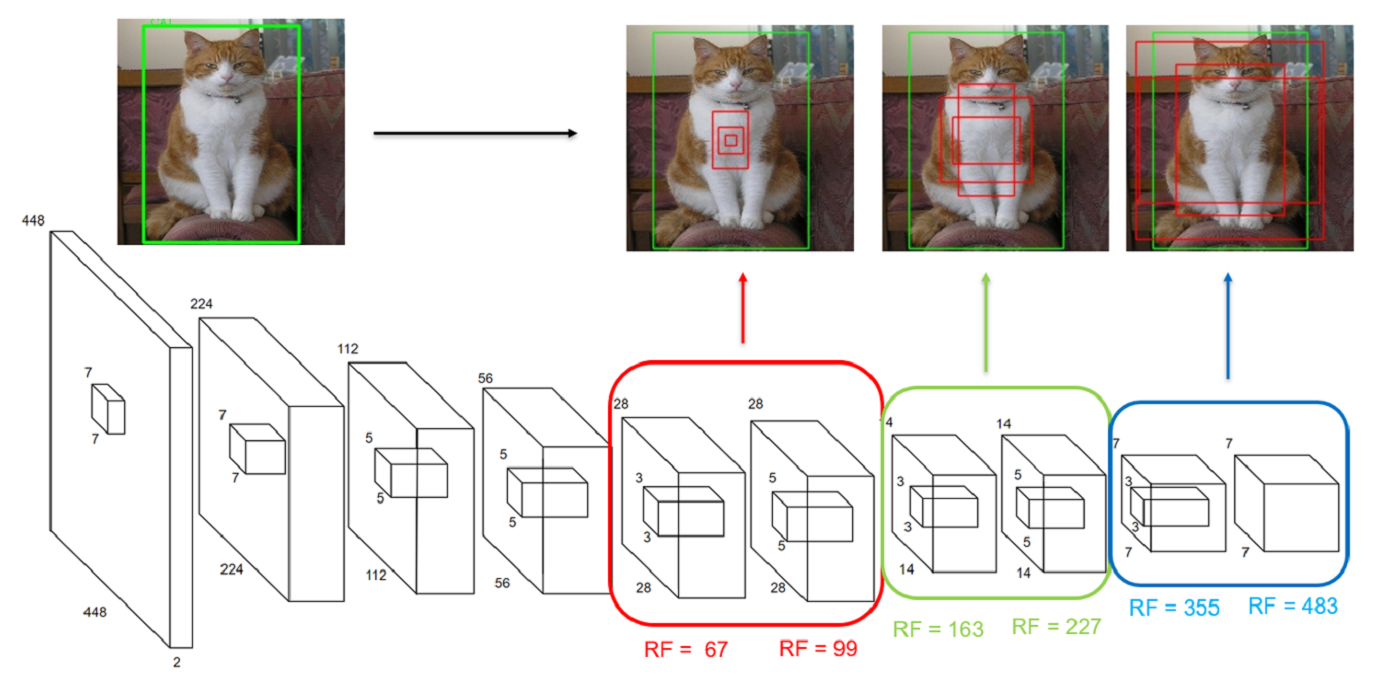
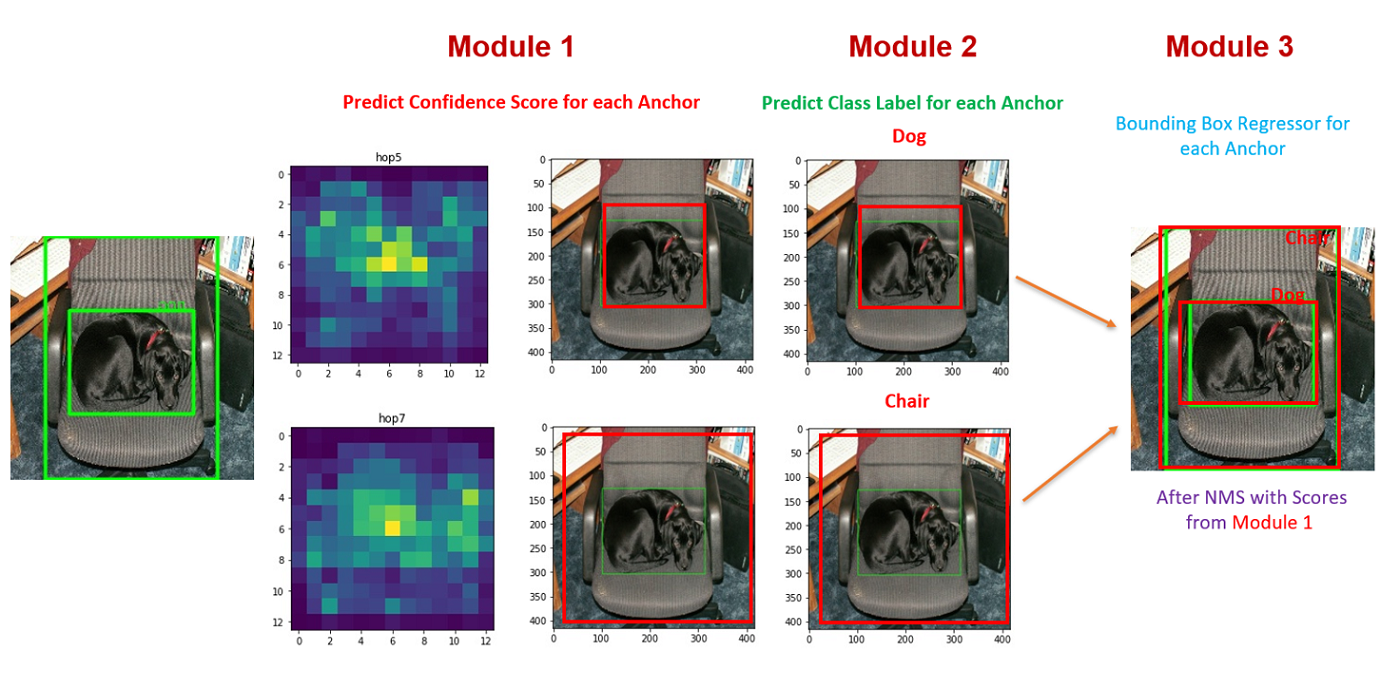
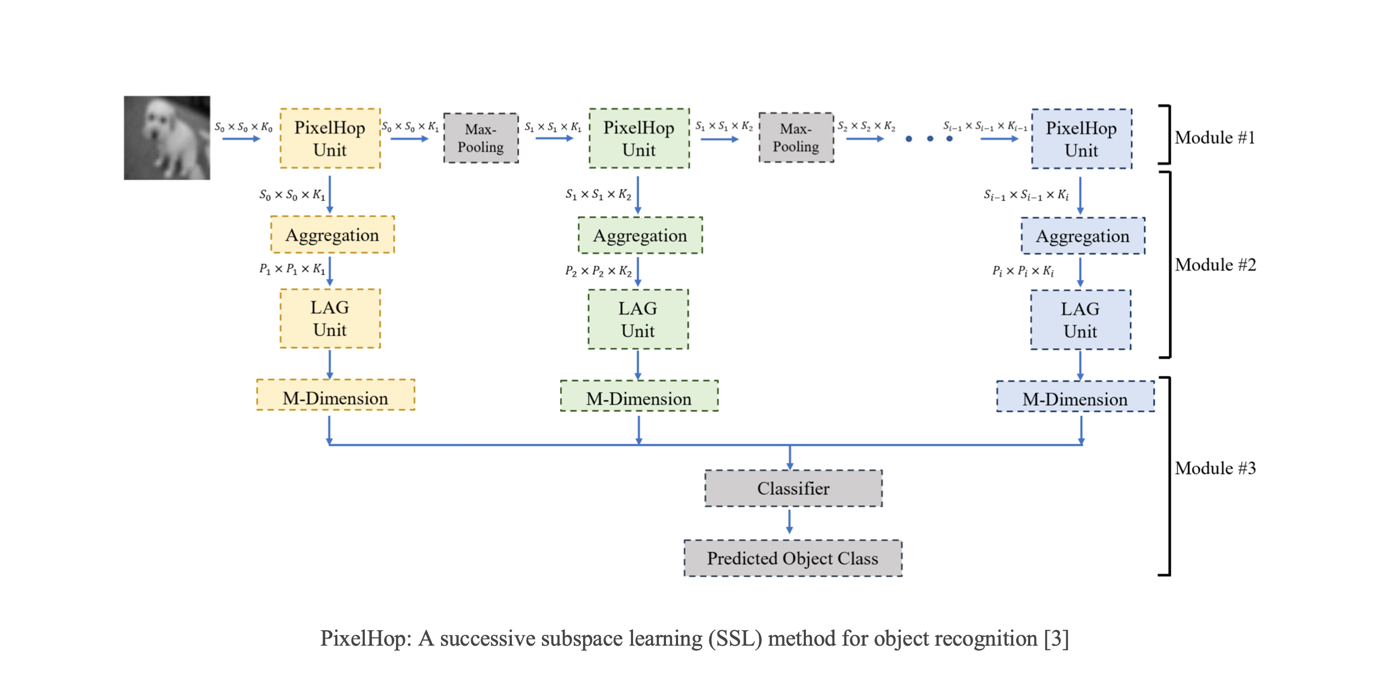
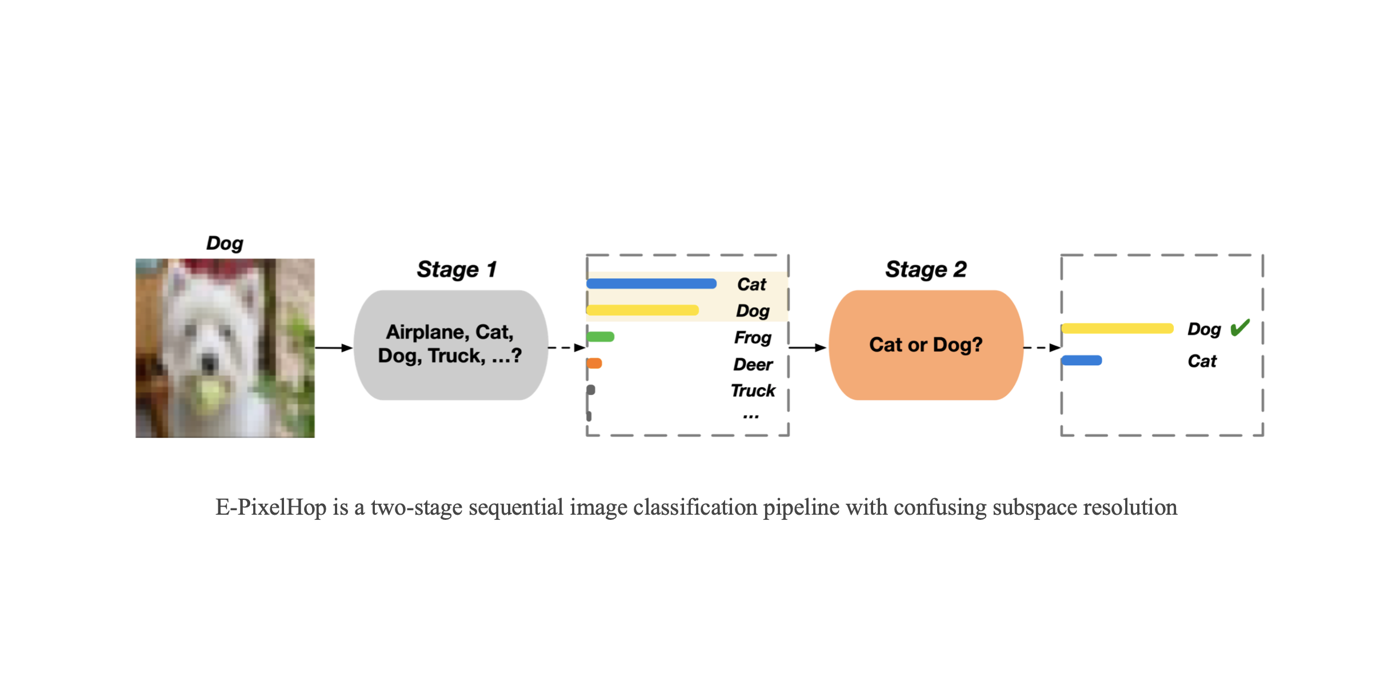
Welcome MCL New Member – Armin Bazarjani
In Fall 2021, we have a new MCL member, Armin Bazarjani, joining our big family. Here is a short interview with Armin with our great welcome.
1. Could you briefly introduce yourself and your research interests?
I received both my BS and MS degrees in electrical engineering from USC. I am now working as a researcher in MCL as I also prepare to apply for PhD programs for the Fall 2022 cycle. My overarching interests are in machine learning and statistical pattern recognition, and I hope to one day be able to meaningfully apply these interests to the fields of computational sustainability and computational neuroscience. Other than my academic interests, I really enjoy hiking/backpacking, cooking, and generally being outdoors and away from the computer whenever I can manage the time.
2. Could you briefly introduce yourself and your research interests?
It should come as no surprise that I am a big fan of the culture at USC as I have received two degrees here now! From my experience, everybody at USC has been kind and supportive in all areas of scholastic pursuit. Additionally, many of the students here are more well-rounded as they don’t purely focus their identity on academic achievement only. I have only been with MCL for a few weeks now so it is difficult to say anything with relative assurity, especially because I started here during the COVID pandemic and haven’t been able to enjoy my lab members’ company in person. I will say, with the few interactions I have had, the lab seems very well driven and organized. I also really like the advising style of Professor Kuo as he seems to strike a good balance between how hands on he is and how [...]