MCL Research on Eosinophilic esophagitis (EoE) Diagnosis
Eosinophils are a type of white blood cell that can both protect the body and cause disease. While they are essential for fighting certain parasitic infections, they are also a primary cause of many allergic conditions when they don’t function correctly. It’s important to understand these cells because their buildup and activation are the main reasons for tissue damage in diseases like asthma and Eosinophilic Esophagitis (EoE).
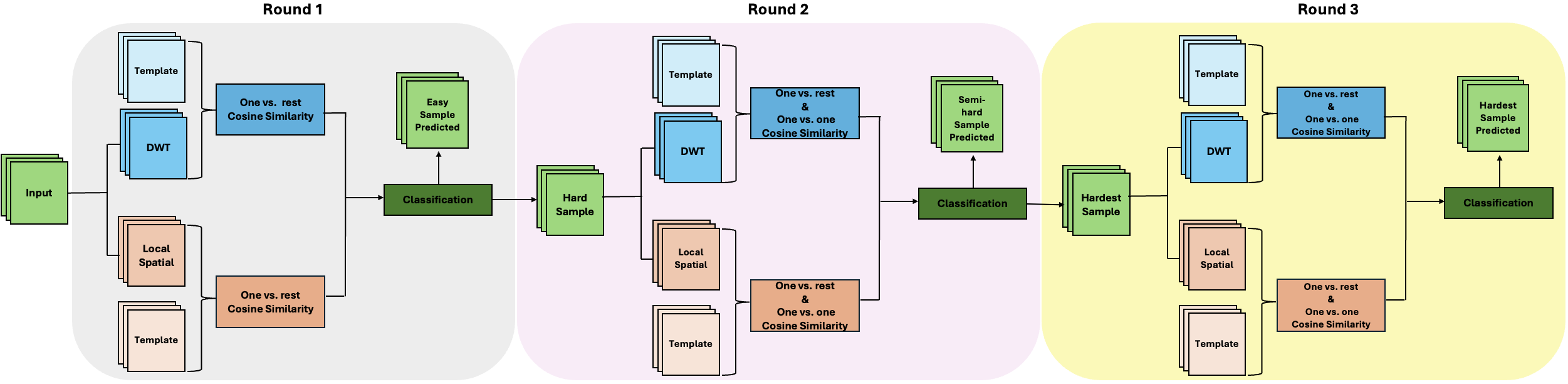
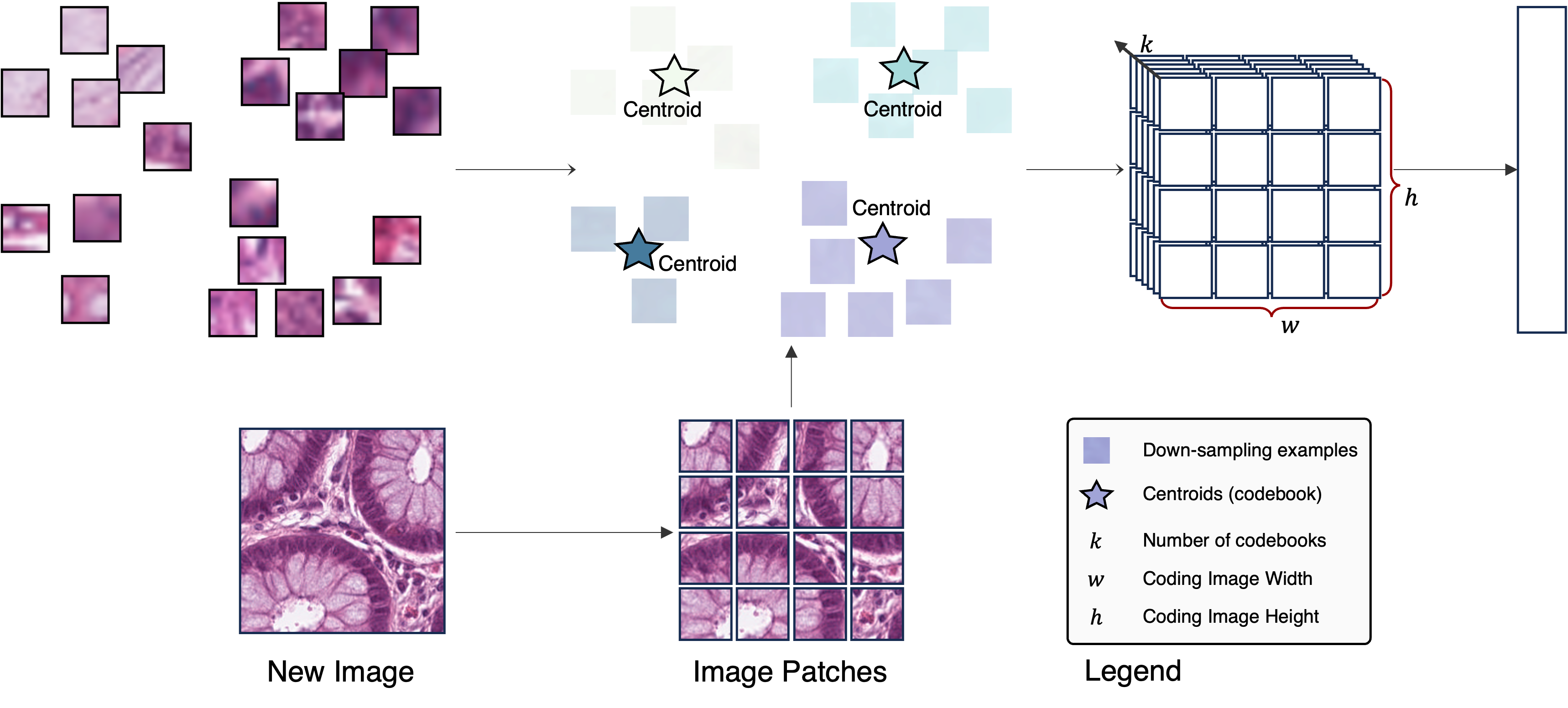
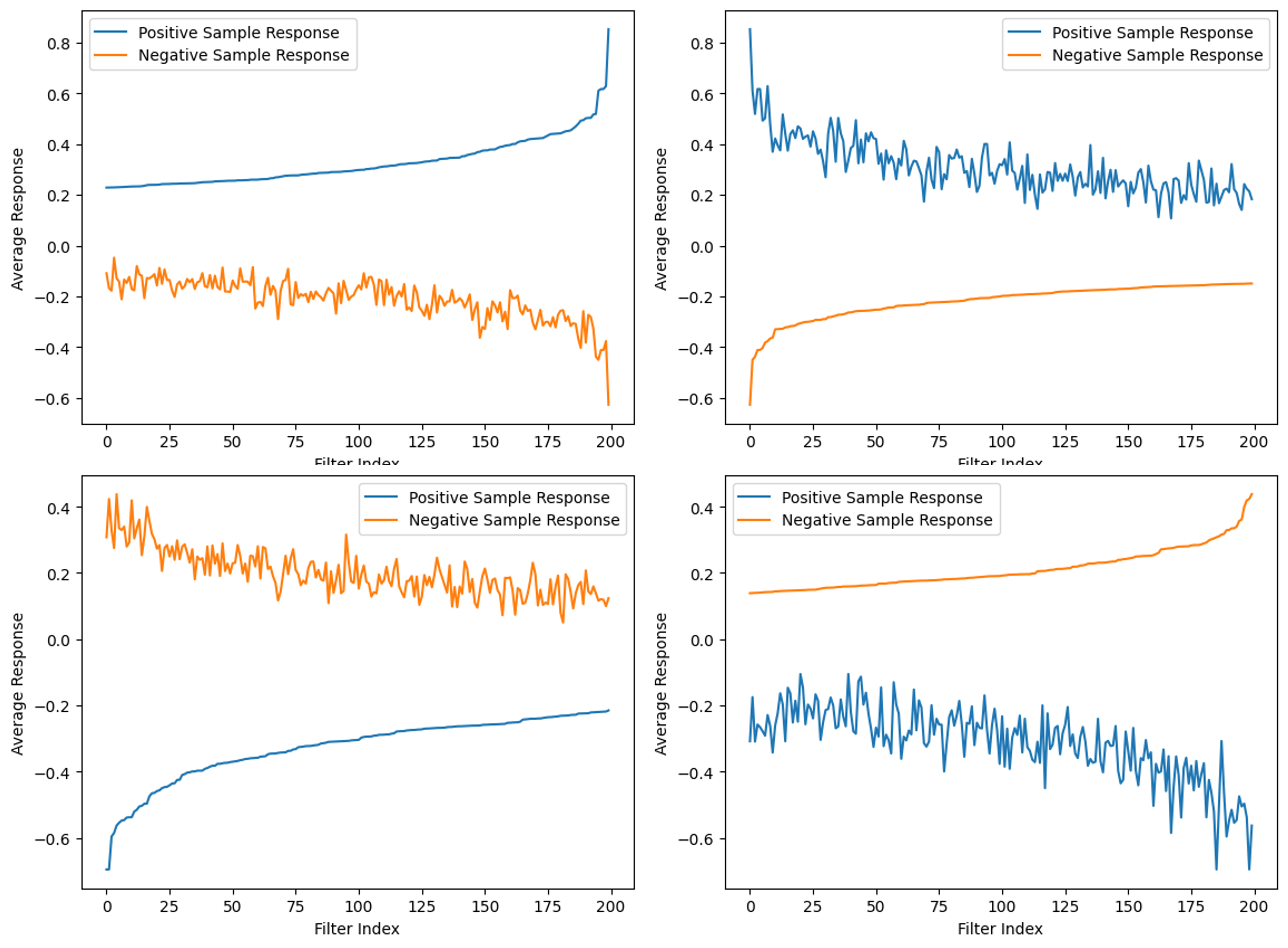
Our current work explores the use of a dictionary learning pipeline to get unsupervised representations of whole-slide images of EoE. Unlike deep learning methods that require back-propagation to optimize millions of parameters to get data representations, our method represents the data in a self-organized way, with no back-propagation at all.
Compared to many other machine learning methods, our new pipeline provides a more transparent and explainable approach, especially for medical image analysis with smaller, specialized datasets.