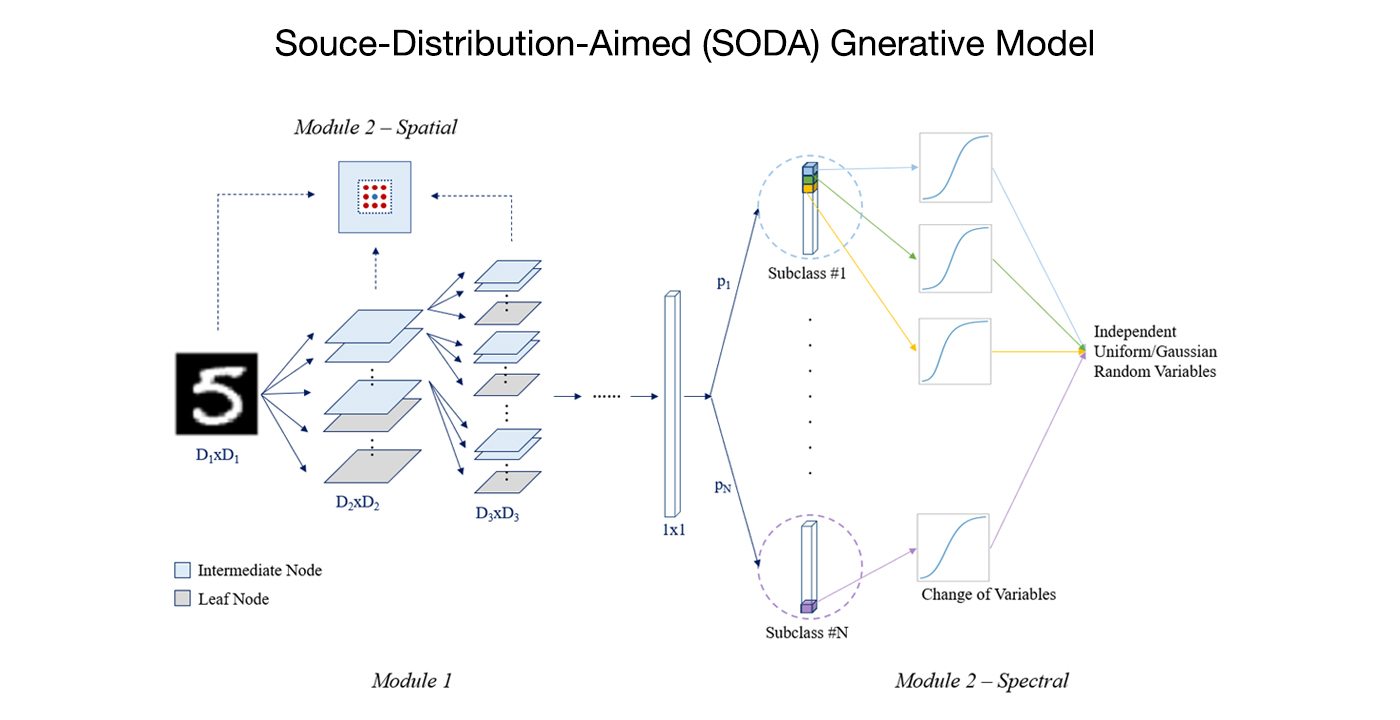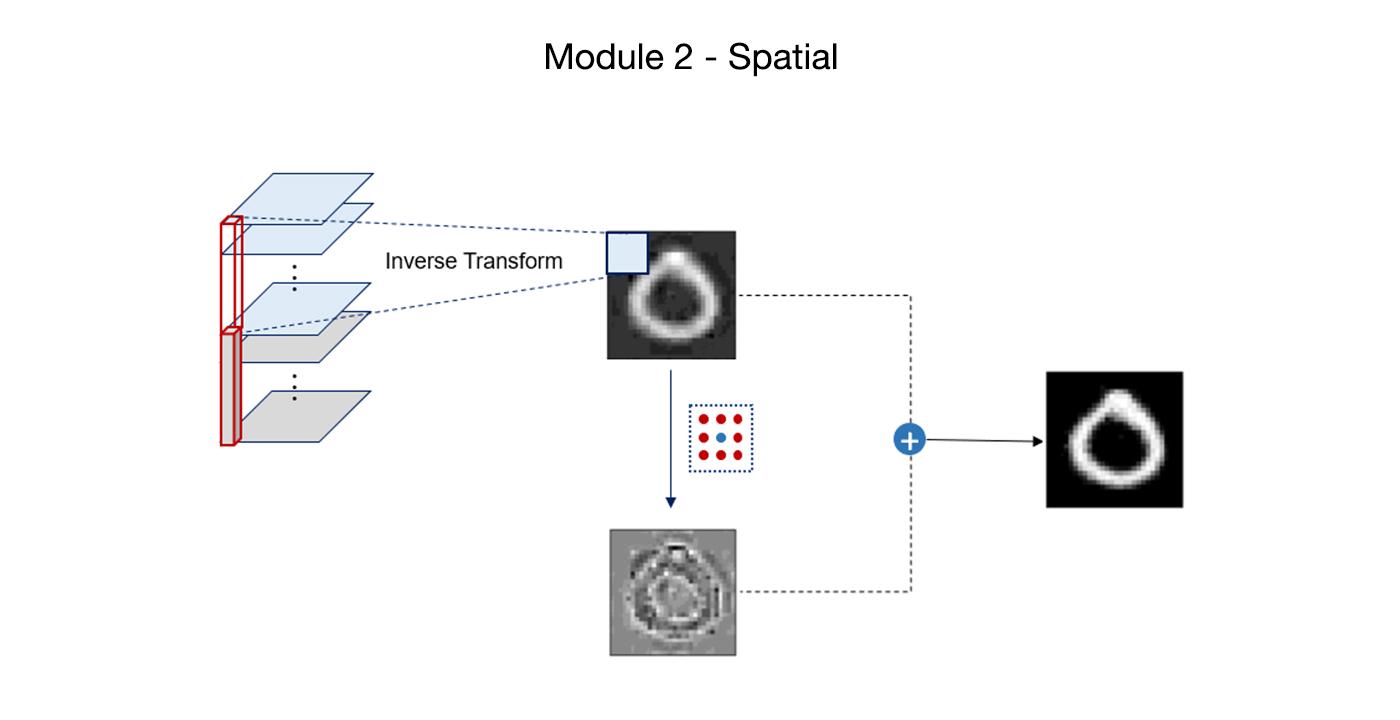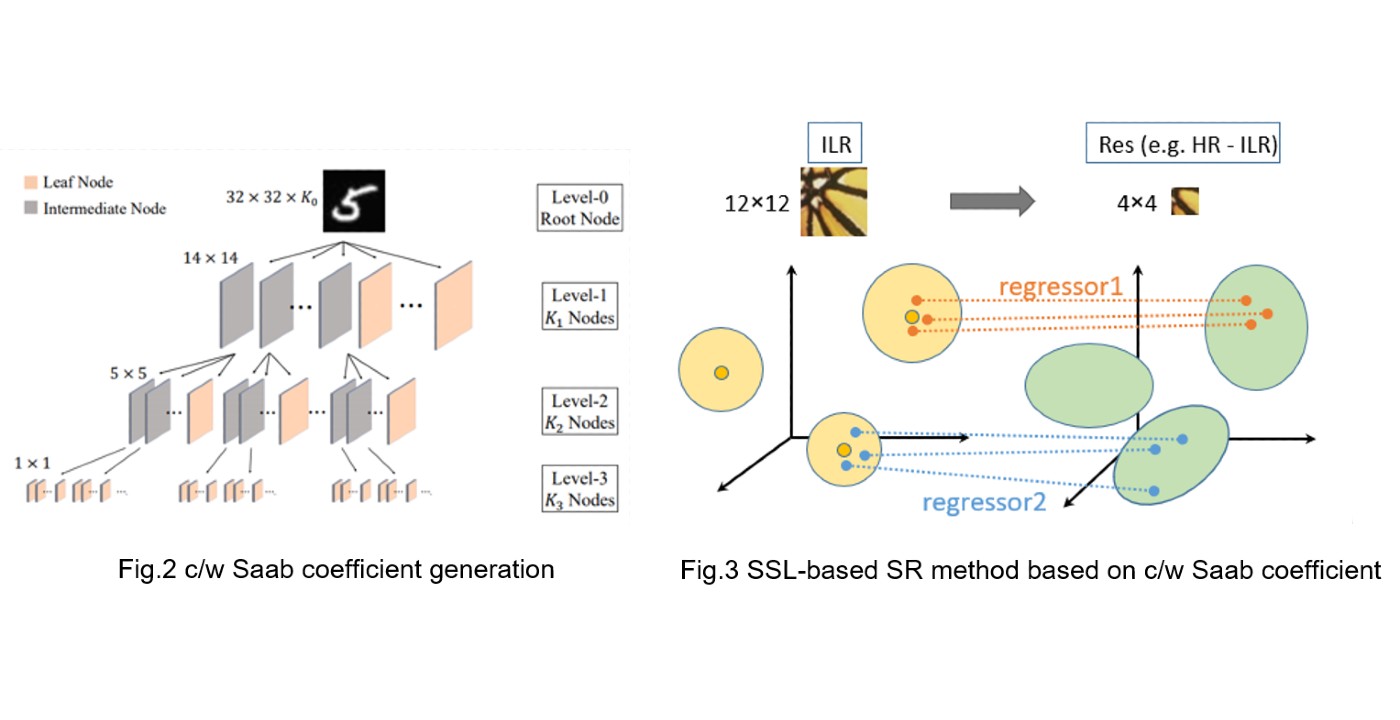
MCL Research on Small Neural Netwrok
Deep learning has shown great capabilities in many applications. Many works have proposed different architectures to improve the accuracy. However, such improvement may come at a cost of increased time and memory complexity. Time and memory complexity can be important to some applications such as mobile and embedded applications. For these applications, small neural network design can be helpful. Small neural networks aim to reduce the network size while maintaining good performance. Some examples of small neural networks include SqueezeNet [1], MobileNet [2], ShuffleNet [3].
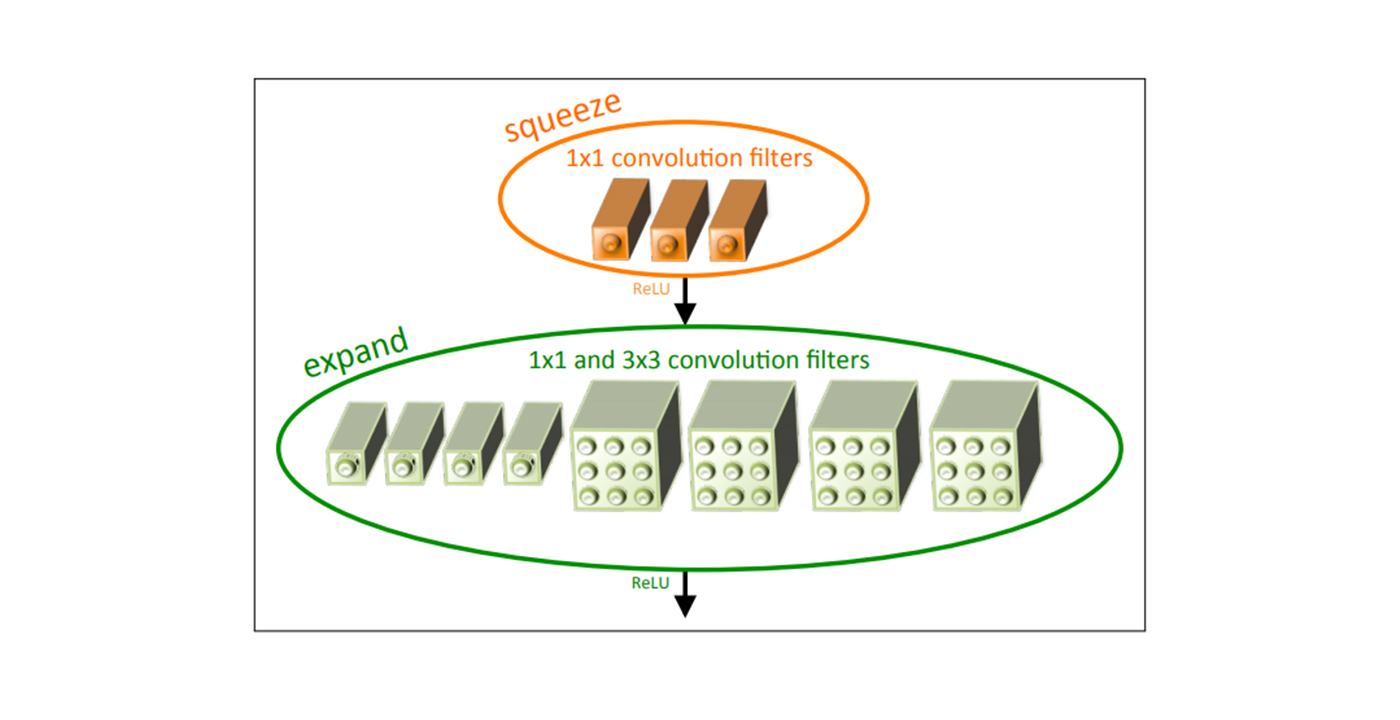
Despite the success of small neural networks, the reason why such networks can achieve good performance while significantly reducing the size has not been studied. In our research, we aim to quantitatively justify the design of small neural networks. In particular, we currently focus on the design of SqueezeNet [1]. SqueezeNet significantly reduces the number of network parameters while maintaining comparable performance by
Replacing some of the 3×3 filters with 1×1 filters. Since each 3×3 filter has 9 weights while a 1×1 filter has only 1 weight, we can greatly reduce the number of parameters by using 1×1 filters in place of 3×3 filters.
Reduce the number of input channels to 3×3 filters. This significantly reduces the number of parameters for the 3×3 filters.
Activation maps are downsampled late in the network. This is motivated by the intuition that larger activation maps may improve accuracy.
A key module of SqueezeNet is the Fire module. A Fire module consists of a squeeze layer and a subsequent expand layer. The squeeze layer reduces the number of input channels to the 3×3 filters in the expand layer. In our work, we use some metrics and visualization techniques to analyze the role of [...]