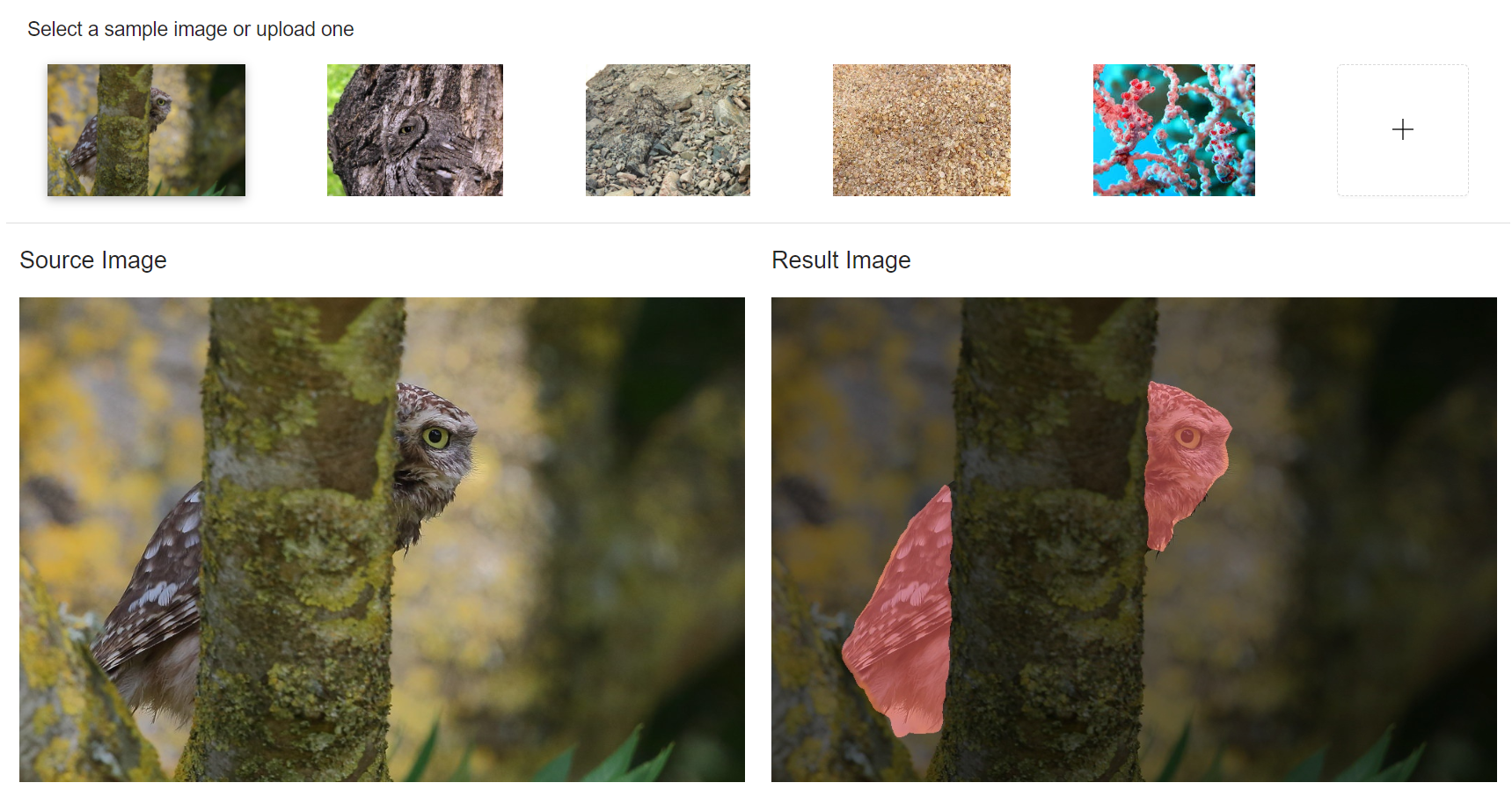
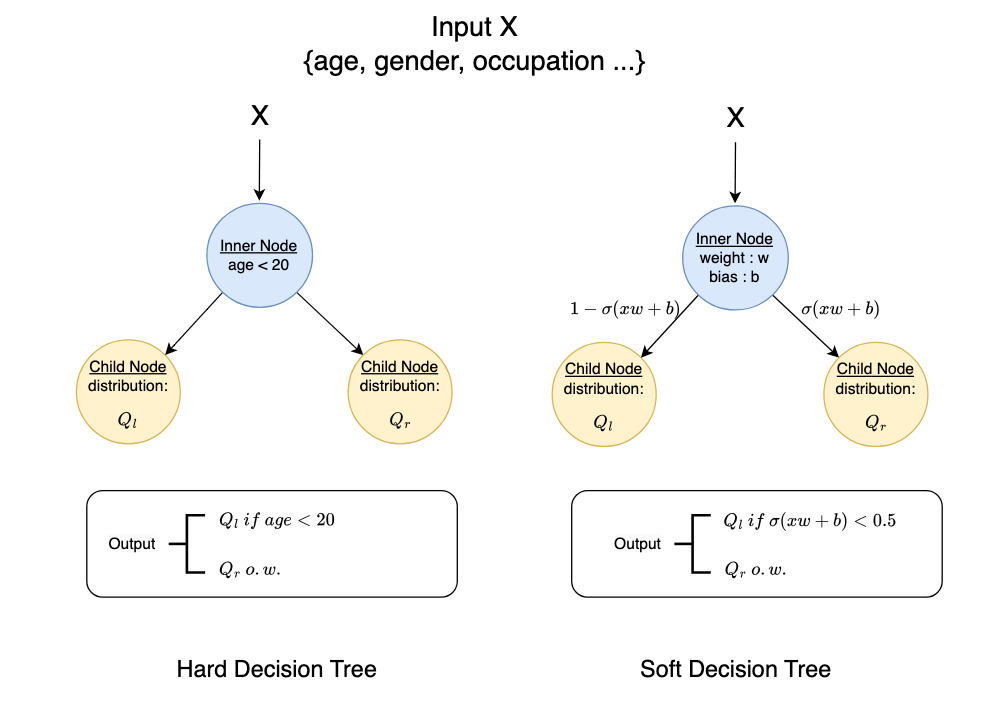
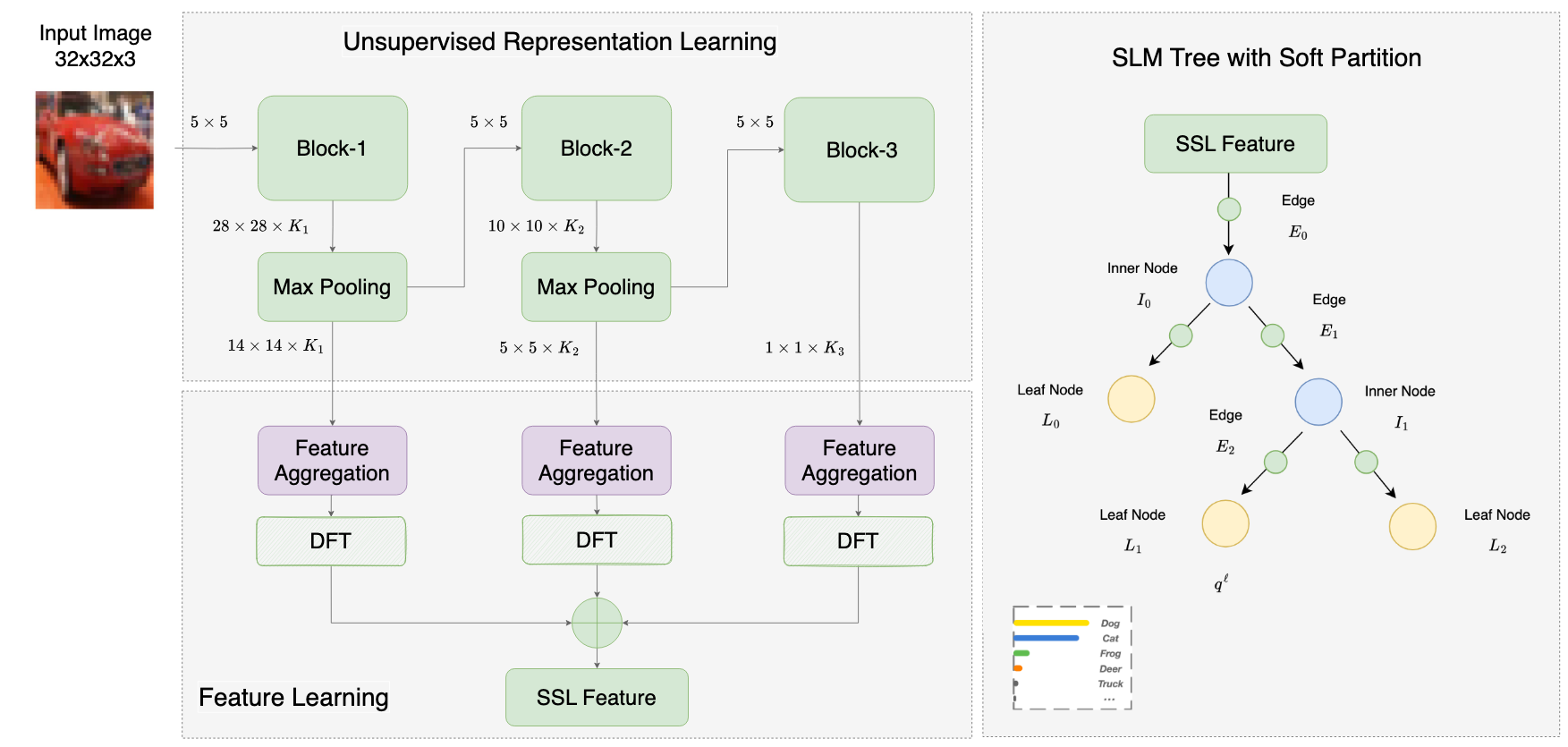
Camouflage detection is a pivotal area that relies on sophisticated algorithms and advanced models capable of discerning objects or individuals concealed within their environment by employing various camouflage techniques like pattern matching. These models play a crucial role in diverse domains such as security, wildlife monitoring, and even military applications, where their ability to distinguish foreground hidden objects from the background image pixels is paramount for effective detection and identification.
In our pursuit of enhancing camouflage detection capabilities, we have trained our model primarily on hidden animals. We have chosen to use the COD10K dataset [1]. This consists of 10,000 images, of which 5,066 are camouflaged, 3000 are background, and 1934 are non-camouflaged, which makes it a robust dataset very suitable for camouflage detection.
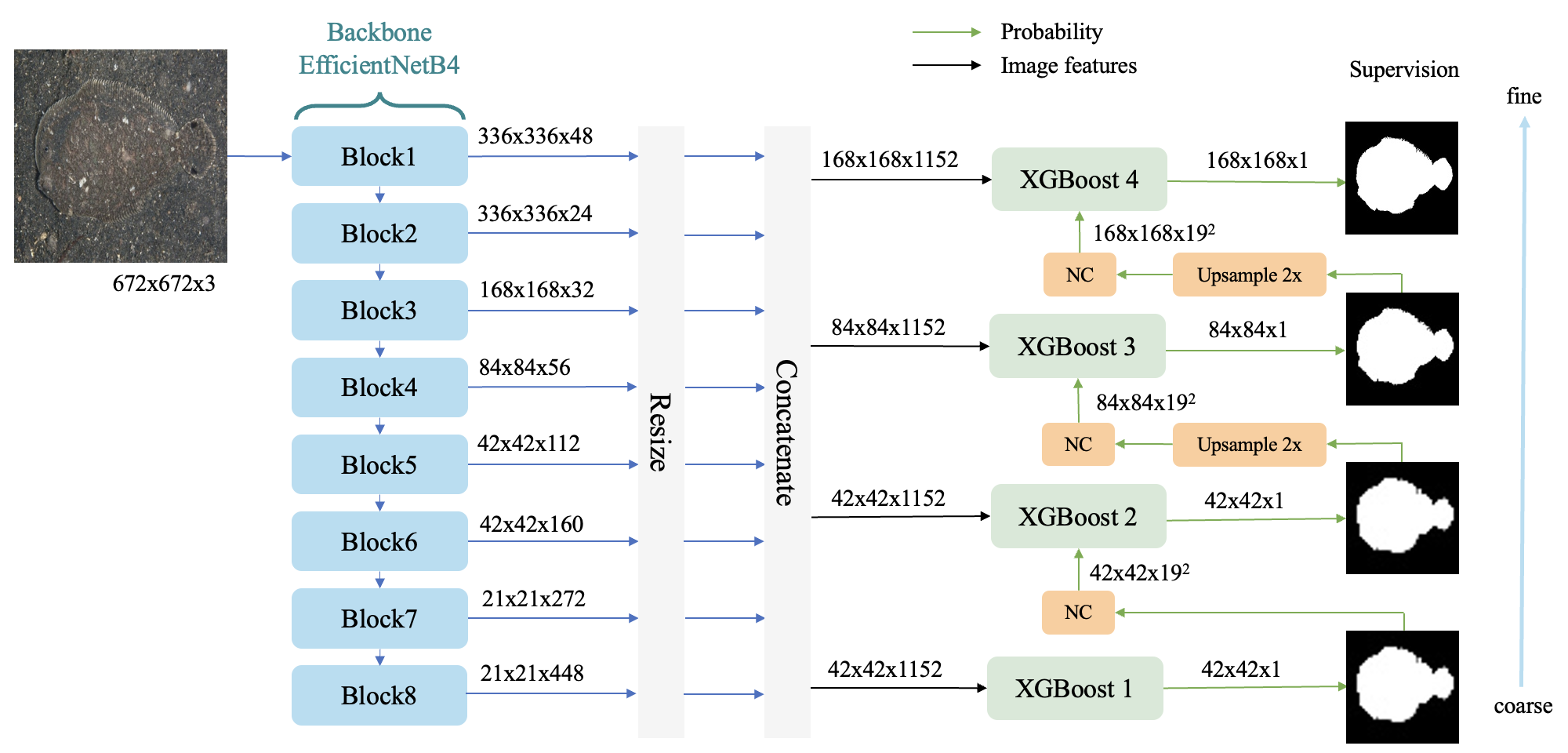
Currently, we have a GreenCOD[2] model designed with EfficientNet feature extraction and an upsampling structure of XGBoost to gradually predict the detection results. Our goal is to further reduce the model size and runtime, while potentially increasing the performance. In the future, we plan to use this improved model to analyze videos with hidden objects, like the MoCA-Mask dataset. This will help the model work well in real-time situations, like surveillance and protecting wildlife. Ultimately, we aim to enhance camouflage detection systems used in different fields.
[1] D. Fan, G. Ji, G. Sun, Ming-Ming Cheng, Jianbing Shen, Ling Shao. “Camouflaged Object Detection”. CVPR, 2020.
[2] H. Chen, Y. Zhu, S. You, C.-C. J. Kuo, “GreenCOD: Green Camouflaged Object Detection”. APSIPA Transactions on Signal and Information Processing 2023. Available: https://hongshuochen.com/GreenCOD/
Image credits:
Image showing image/mask pair of animal image is from [1].
Image showing the architecture of GreenCOD is from [2].