MCL Research on EDA
The IR-drop (voltage drop) analysis in integrated circuits is essential as the circuit designs become more complex and compact. Due to the complicated and tiny designs, the power delivery network (PDN) cannot deliver a target voltage to each cell, causing reliability issues and performance drops. Therefore, IR-drop estimation is a crucial step to ensure the functionality of the circuits.
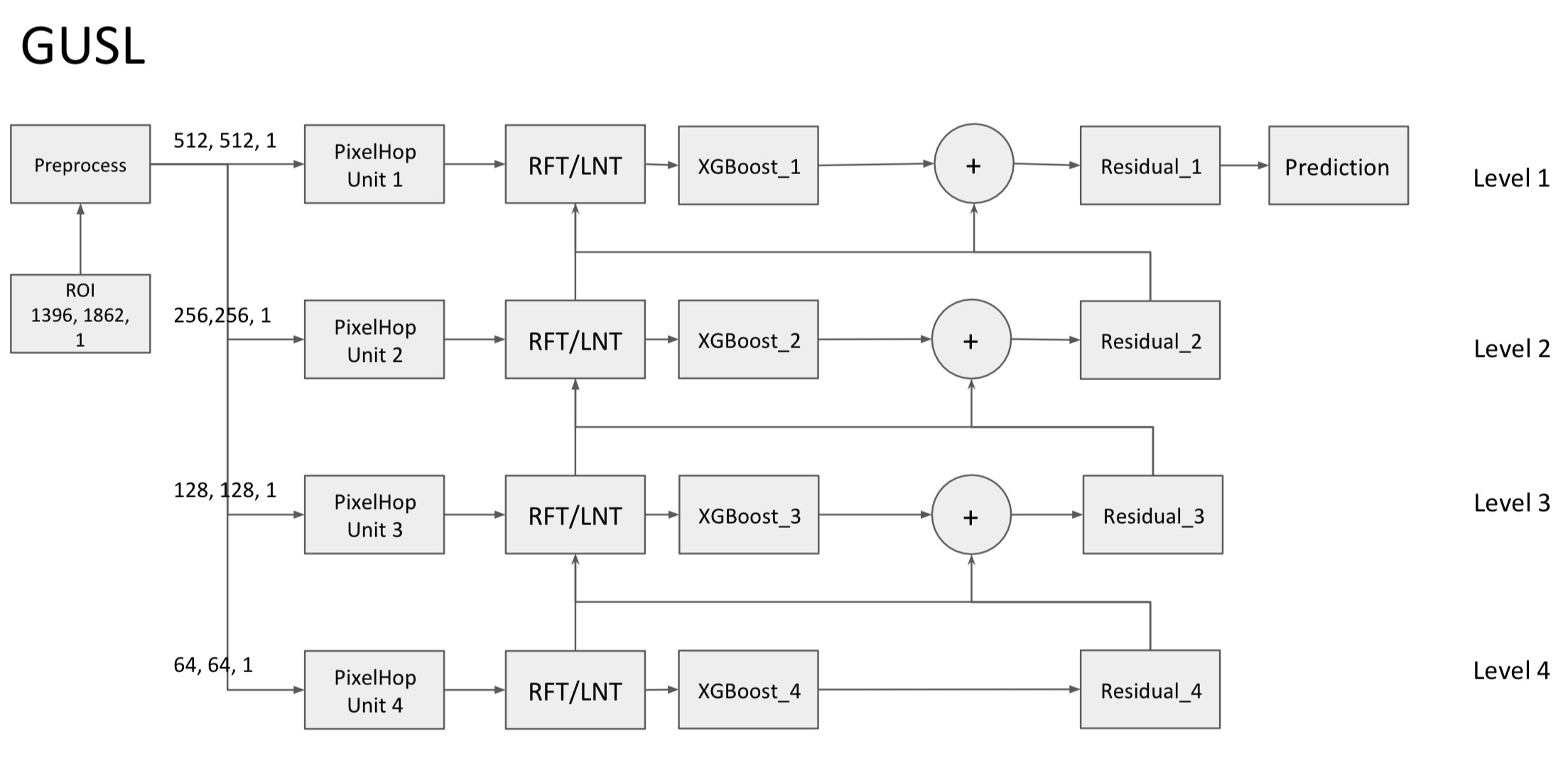
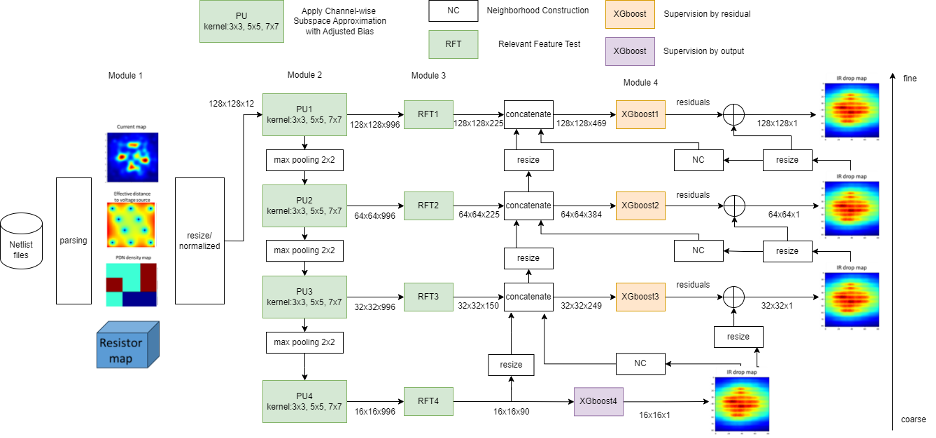
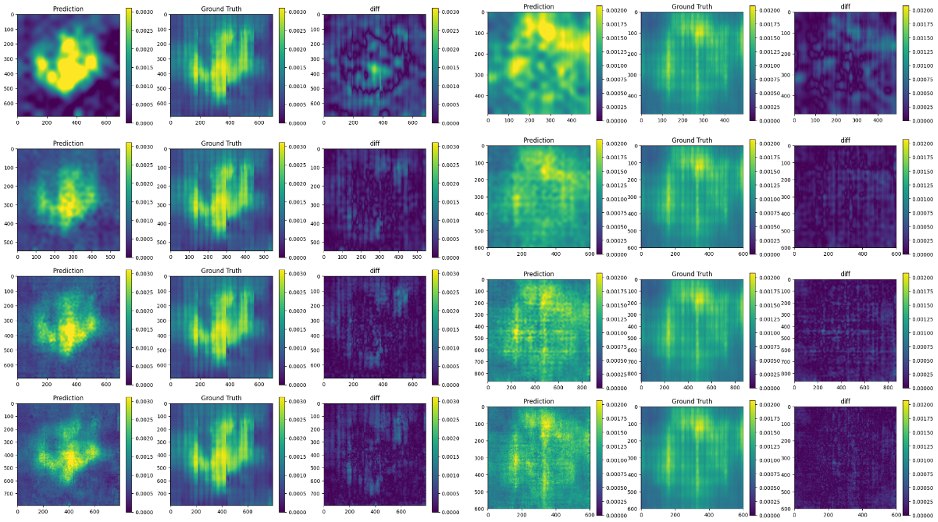
Traditionally, IR-drop estimation relies on solving linear equations based on Kirchhoff’s current and voltage laws. Nevertheless, as the designs become more complex, the computational cost and simulation time increase significantly. In this research, an energy-efficient and high-performance static IR-drop estimation called GIRD (Green IR-Drop) is proposed. GIRD processes the IC design input in three steps. First, the input netlist data are converted to multi-channel maps. Their joint spatial-spectral representations are determined with PixelHop. Next, discriminant features are selected using the relevant feature test (RFT). Finally, the selected features are fed to the XGBoost (eXtreme Gradient Boosting trees) regressor. Both PixelHop and RFT are green learning tools. GIRD yields a low carbon footprint due to its smaller model sizes and lower computational complexity. Besides, its performance scales well with small training datasets. Experiments on synthetic and real circuits are given to demonstrate the superior performance of GIRD. The model size and the complexity, measured by the Floating Point Operations (FLOPs) of GIRD, are only 1/1000 and 1/100 of deep-learning methods, respectively.