Congratulations to Xinyu Wang for Passing her Defense
Congratulations to Xinyu Wang for passing her defense! Xinyu’s thesis is titled “ Towards Efficient Visual Perception: From Feature Learning to Visual Reasoning.” Here is a brief summary of her thesis:
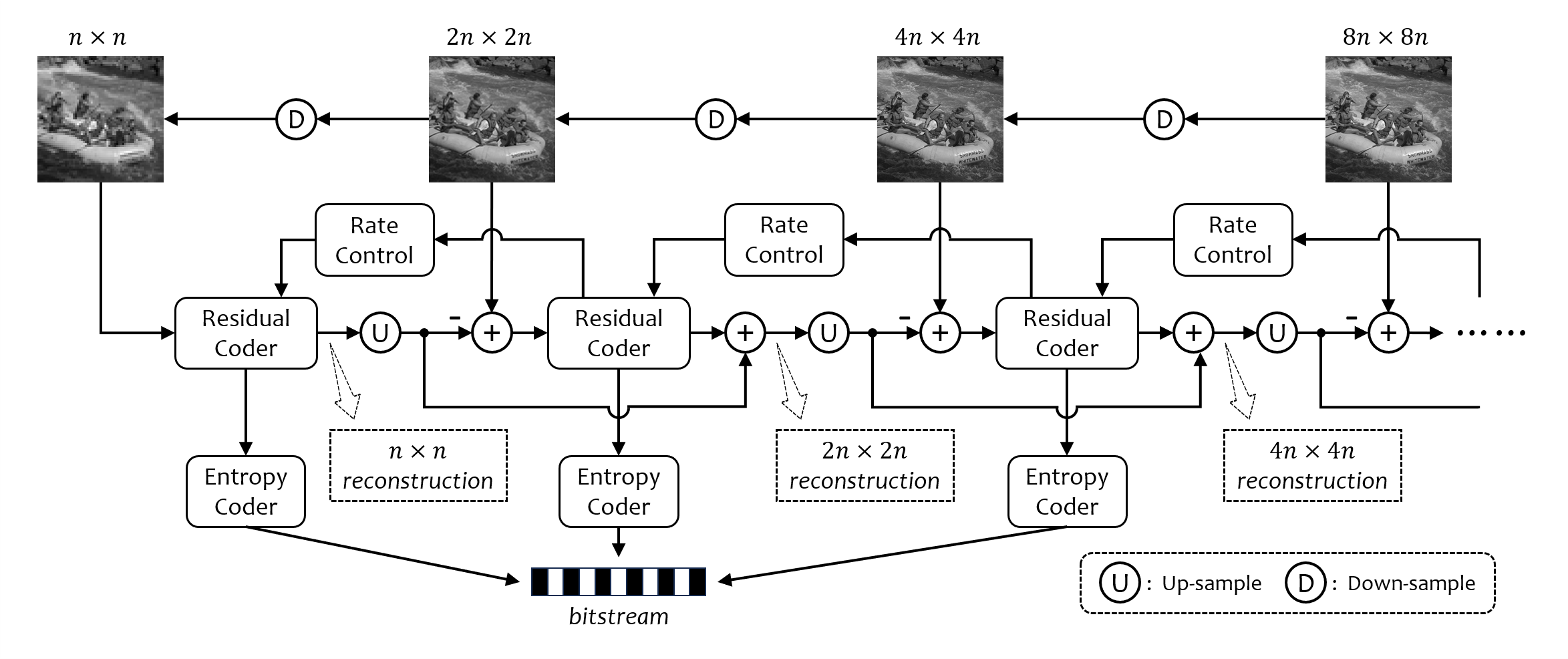
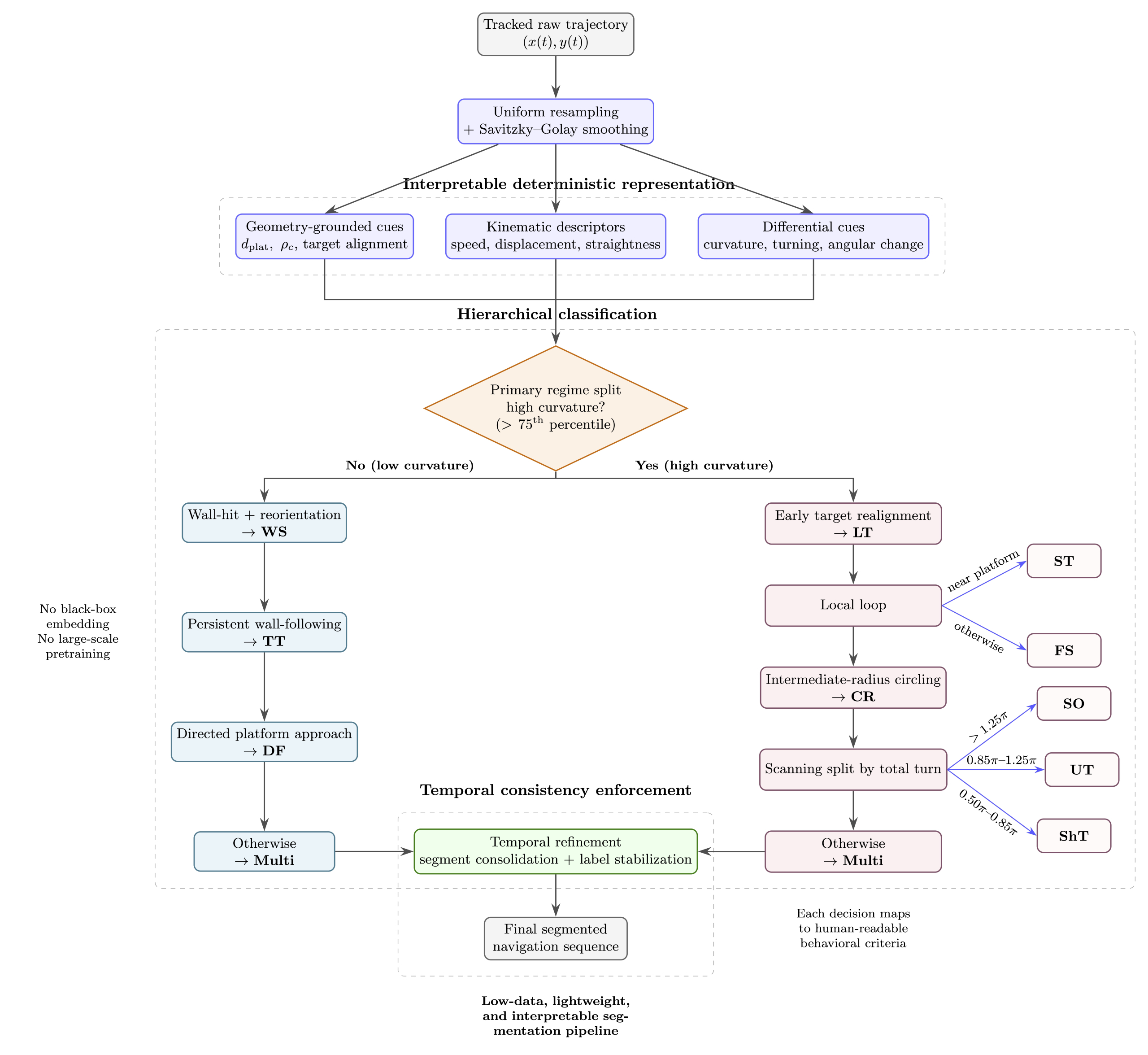
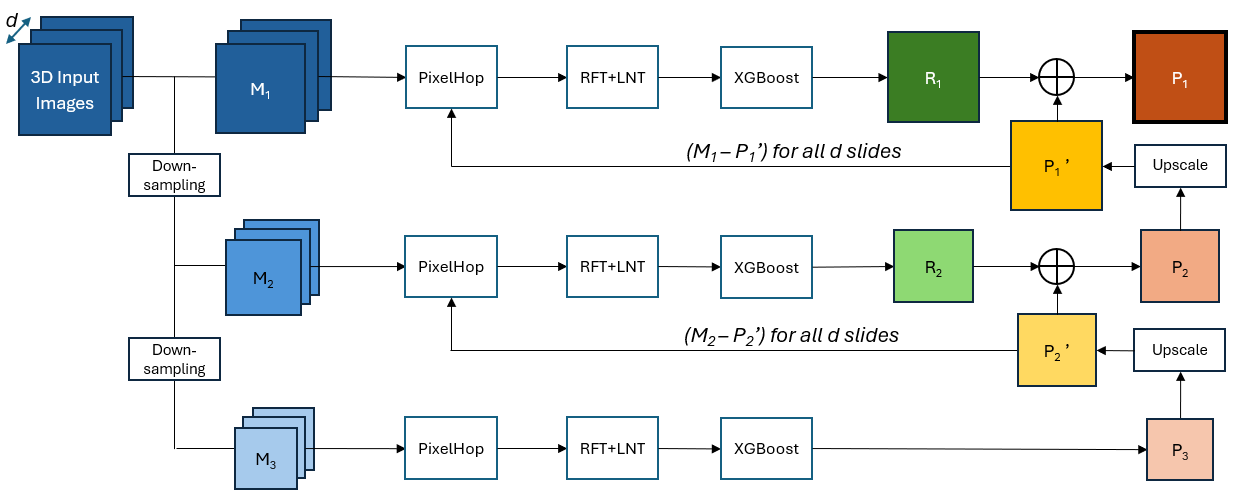
Visual perception serves as a fundamental component of modern computer vision, enabling the interpretation of large-scale image and video data. As visual data continues to grow in complexity, there is an increasing demand for efficient and scalable frameworks that bridge low-level representations and high-level understanding. This dissertation addresses this challenge by exploring a unified trajectory of efficient visual perception, evolving from feature learning to spatio-temporal modeling and ultimately to scene-conditioned visual reasoning. This dissertation first introduces a statistics-based feature generation framework for image classification, built upon the Least-squares Normal Transform, which reformulates classification as a regression problem for efficient feature learning. It generates discriminative and complementary features, boosting decision learning and training convergence with low computational overhead. It then investigates a particularly challenging visual task, video camouflaged object detection. The proposed GreenVCOD is a lightweight framework that captures temporal context through a Temporal Neighborhood prediction cube, enabling implicit motion modeling without additional computational cost. Building upon this, IDM-VCOD introduces a dual-motion design that combines implicit semantic refinement with explicit motion alignment, along with a selective activation mechanism to balance accuracy and efficiency. Finally, this dissertation shifts toward a reasoning-based paradigm for visual perception. Camouflaged object detection is reformulated as a scene-conditioned pattern-deviation reasoning problem. By leveraging background-aware retrieval and prototype-based reasoning, it identifies subtle deviations without relying on pixel-level supervision. Overall, the proposed methods demonstrate that lightweight design, combined with structured statistical modeling and scene-conditioned reasoning, can effectively address challenging visual perception tasks without relying on heavy supervision or large-scale model training.