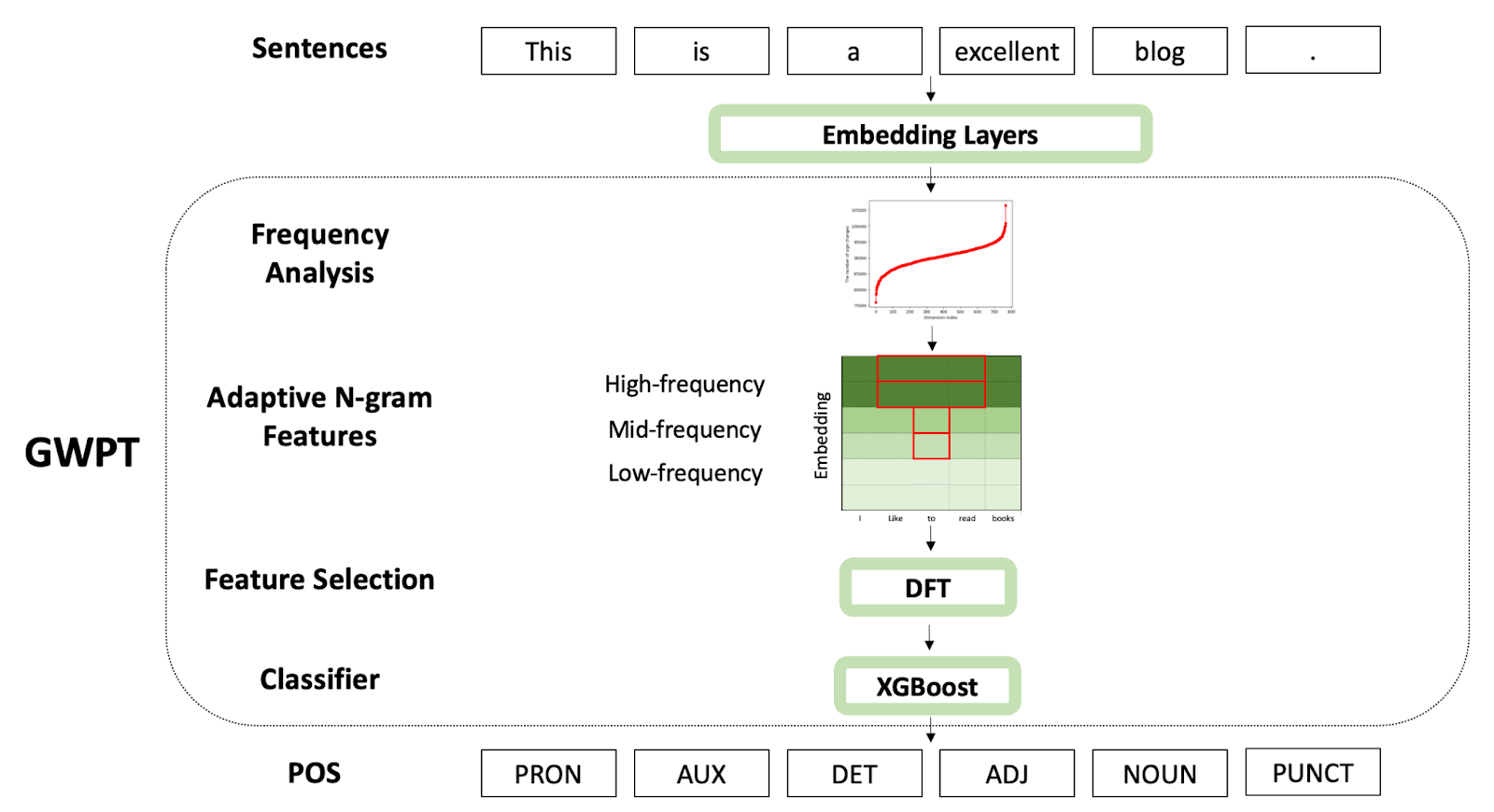
MCL Research on Green Point Cloud Surface Reconstruction
Surface reconstruction from point cloud scans plays a pivotal role in 3D vision and graphics, finding diverse applications in areas such as AR/VR games, cultural heritage preservation, and building information modeling (BIM). This task is inherently challenging due to the ill-posed nature of reconstructing continuous surfaces from discrete points. Moreover, real-world point cloud scans introduce quite a few obstacles such as varying densities and sensor noise. These properties make the problem a long standing one, which keeps driving researchers to look for more effective solutions.
Early research focused on combinatorial methods [1]–[2], which inferred the connectivity between points directly. The mainstream of surface reconstruction adopts an implicit surface approach [3]–[4]. That is, the surface is represented as an unknown continuous function which is solved by the associated partial differential equations (PDEs). Although these methods offer good quality, they often require oriented normals or additional constraints. Recently, people develop deep learning (DL) models [5]–[6] to solve this problem based on a supervised learning framework. DL methods exploits the training data to learn an implicit function representation.
Despite their high reconstruction quality, the generalizability and complexity remain to be challenges for DL models. In scenarios such as point cloud compression, quality assessment, and dynamic point cloud processing, there is a growing need for low-complexity, low-latency surface reconstruction methods. However, existing PDE and DL-based methods tend to sacrifice simplicity for high reconstruction quality, leaving a gap for low-complexity solutions.
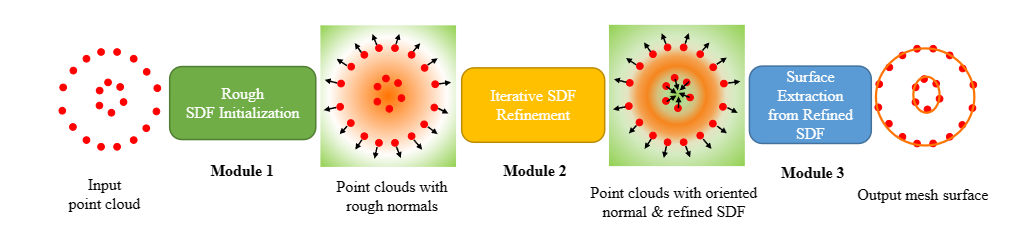
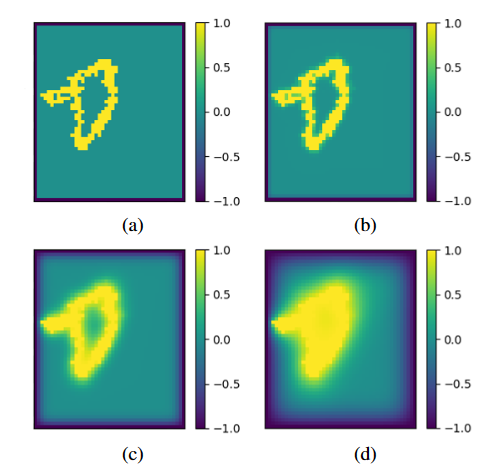
We adopt the unsupervised framework, propose a lightweight high-performance method, and name it green point-cloud surface reconstruction (GPSR). It can be categorized to the family of implicit surface reconstruction methods. The main idea lies in building a signed distance field (SDF) through approximated heat diffusion and fine tuning it iteratively. [...]