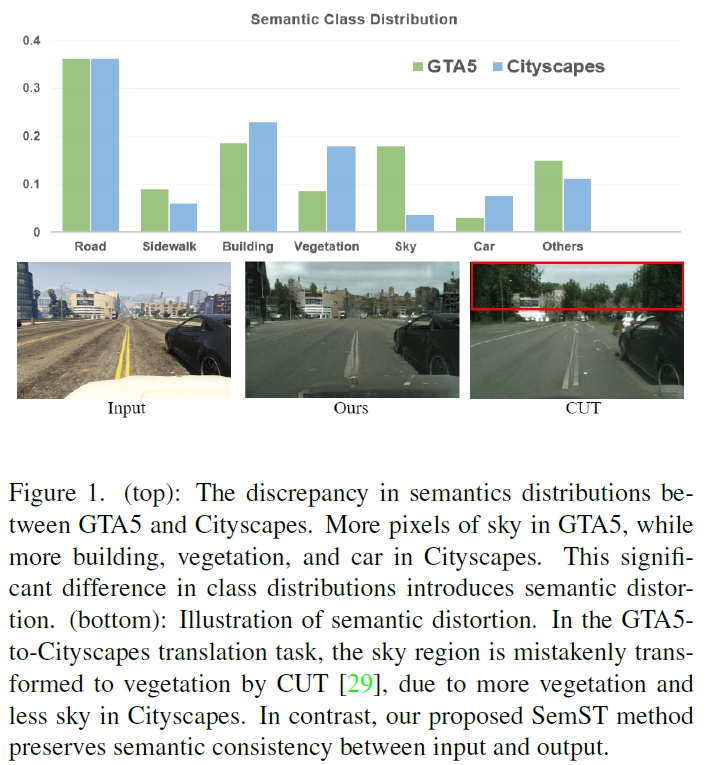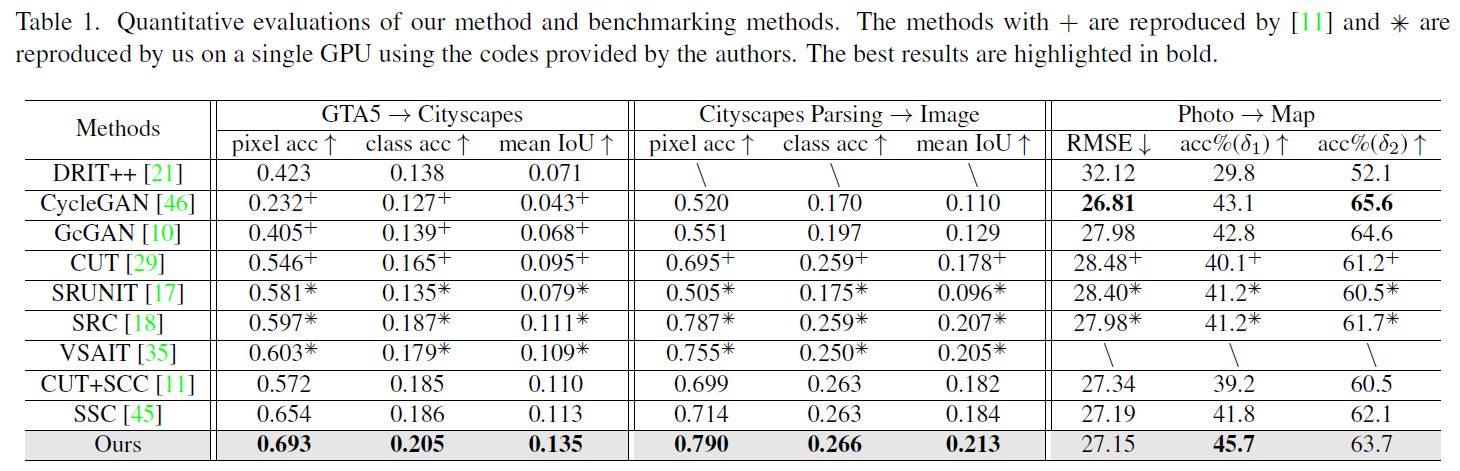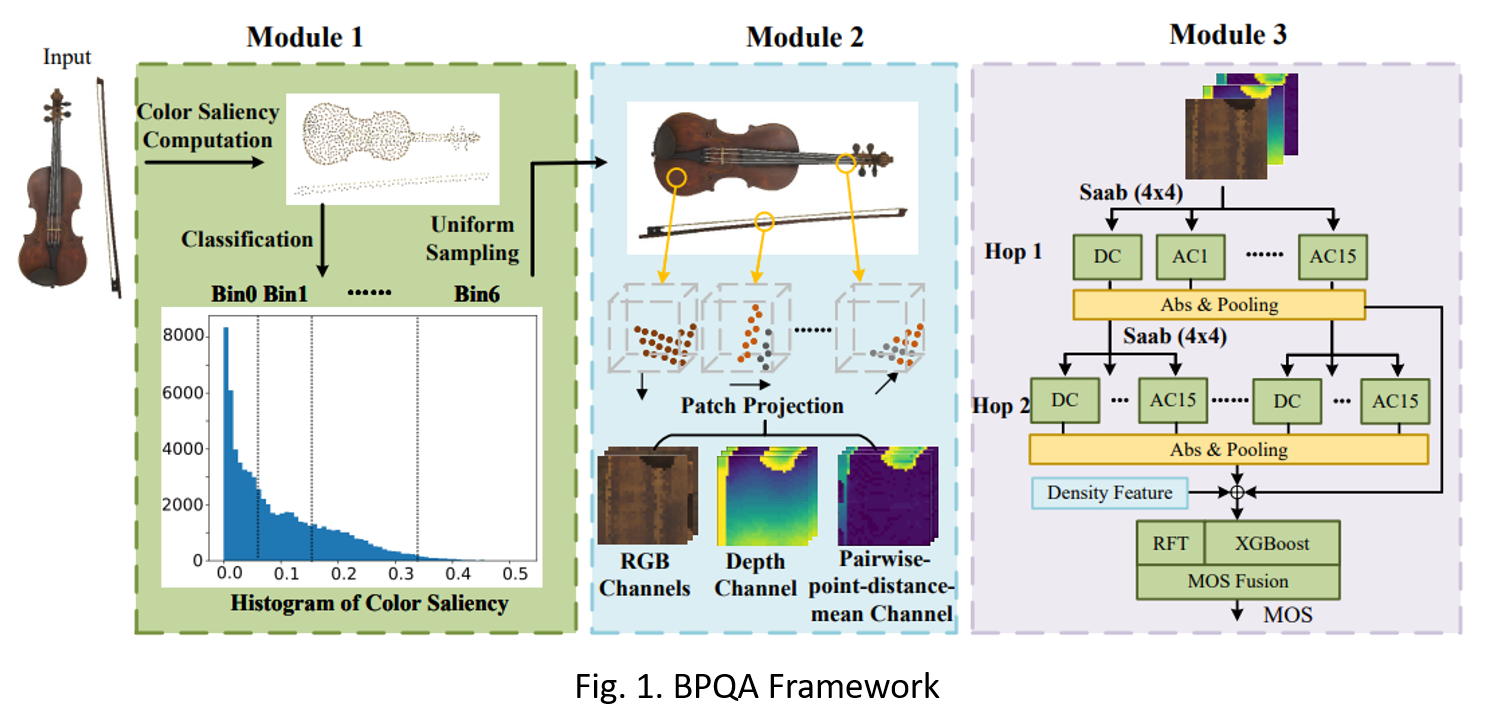
MCL Research on Subspace Learning Machine with Soft Partitioning (SLM/SP)
Feature extraction and decision-making are two modules in cascade in the classical pattern recognition (PR) or machine learning (ML) paradigm. We recently proposed a novel learning diagram named Subspace Learning Machine (SLM) which considers this learning paradigm and focus on specific modules for classification-oriented decision making. SLM can be viewed as a generalized version of Decision Tree (DT). The linear combination of multiple features can be written as the inner product of a projection
vector and a feature vector. The effectiveness of SLM depends on the selection of good projection vectors, e.g. when the projection vector is a one-hot
vector, SLM is nothing but DT.
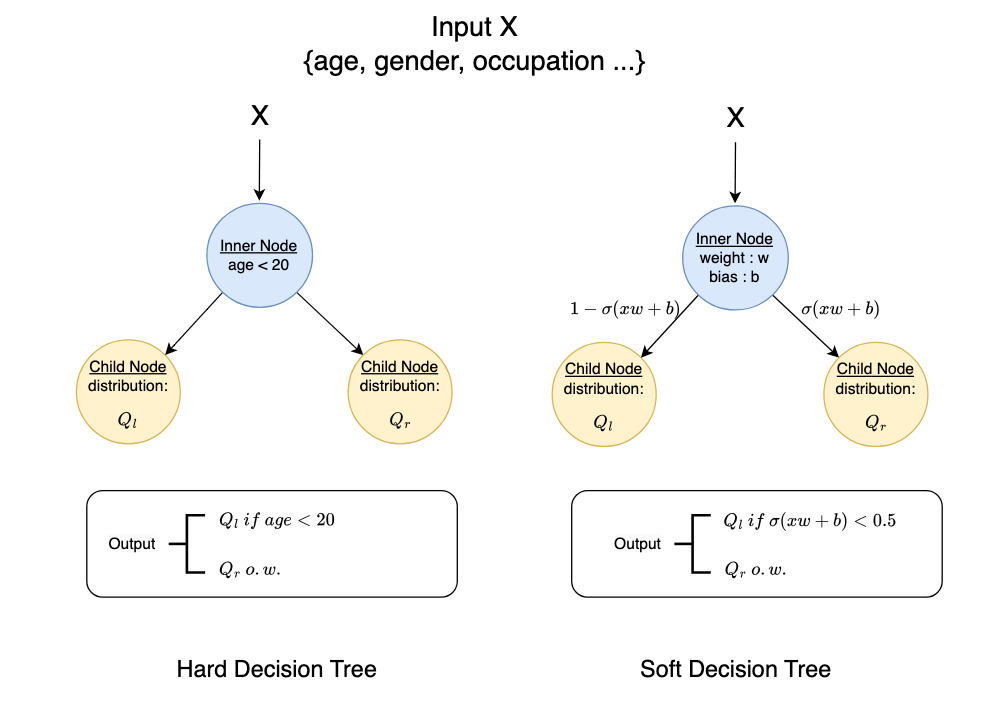
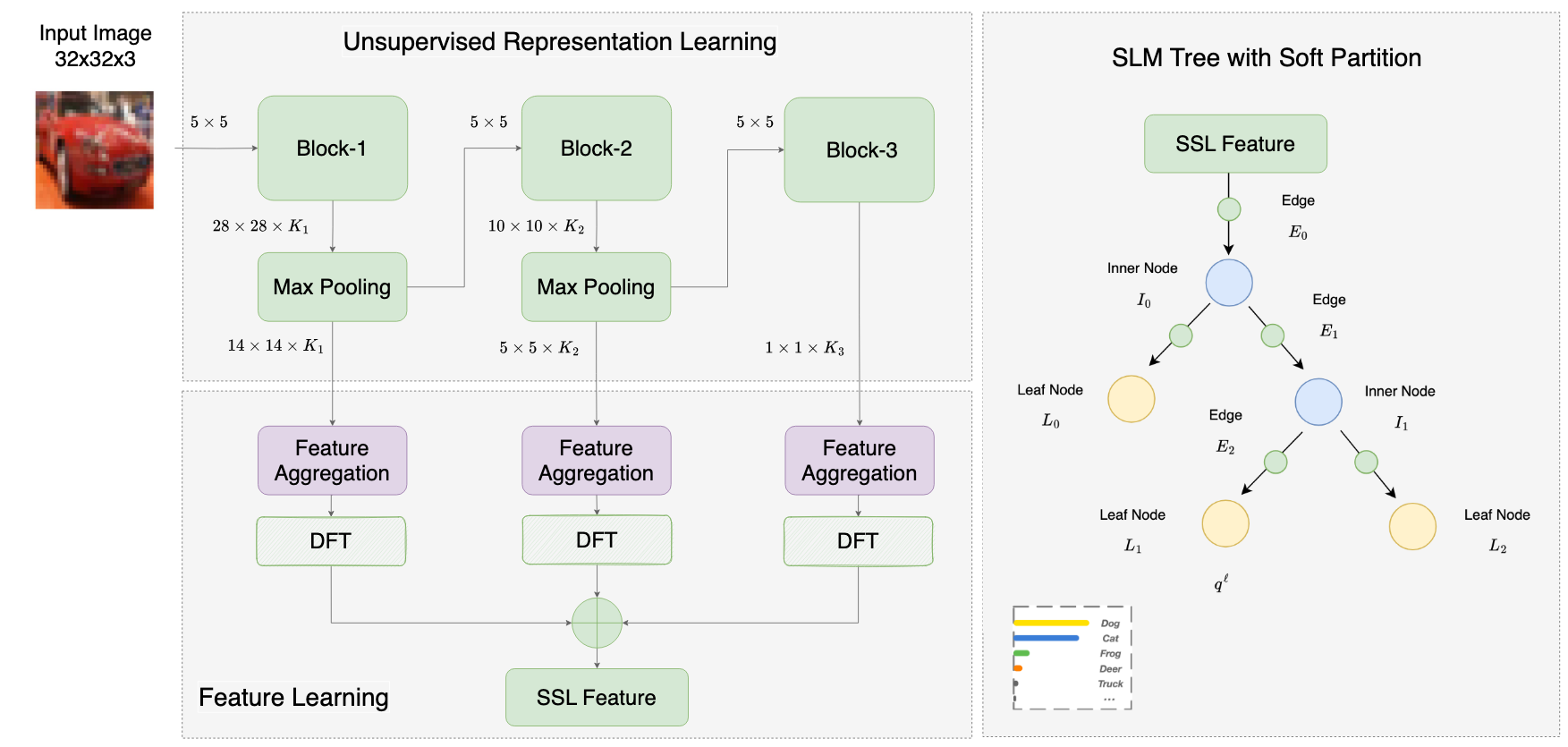
Both SLM and DT apply a hard split to a feature using a threshold at a decision node. To overcome the cons of hard feature space partitioning, we propose a new SLM method that adopts soft partitioning and denote it with SLM/SP in this proposed work. A comparison between hard decision and soft decision is illustrated in Fig 1. SLM/SP adopts the soft decision tree (SDT) data structure and a novel topology is proposed with inner nodes of SDT for data routing, leaf nodes of SDT for local decision making, and edge between parent and child nodes for representation learning. Specific modules are designed for the nodes and edges, respectively. The training of a SLM/SP tree starts by learning an adaptive tree structure via local greedy exploration between subspace partitioning and feature subspace learning. The tree structure is finalized once the stopping criteria are met for all
leaf nodes, and all module parameters are updated globally.
The overall frame working using Successive Subspace Learning and SLM/SP for image classification is as shown in Fig 2. The structure of the SLM/SP tree [...]