MCL Genealogical Ancestry Series – Abraham Gotthelf Kastner
Abraham Gotthelf Kastner (27 September 1719 – 20 June 1800) was a German mathematician and epigrammatist.
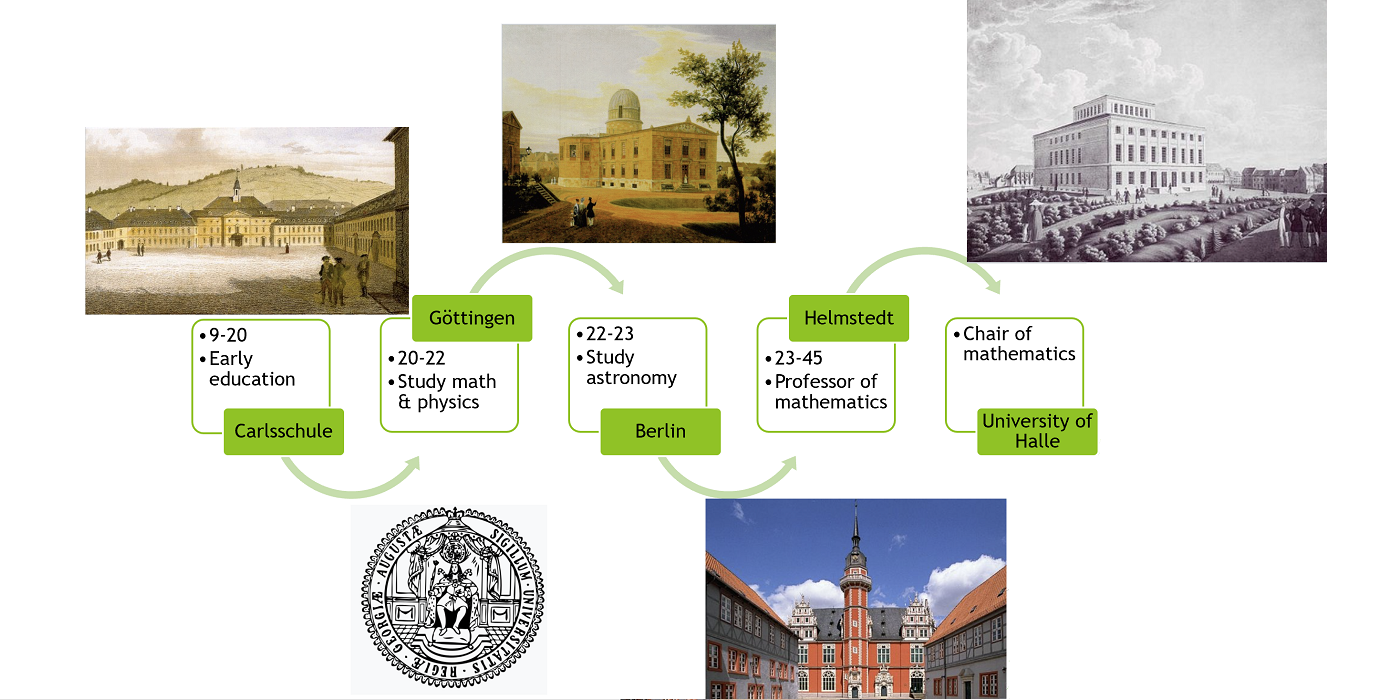
Kästner was the son of law professor Abraham Kästner. Starting from 1731 (aged 12), he studied law, philosophy, physics, mathematics and metaphysics in Leipzig. He was appointed a Notary in 1733, when he was 14. He gained his habilitation (PhD degree in Europe) from the University of Leipzig in 1739 at age 20. In his early careers, he lectured mathematics, philosophy, logic and law in University of Leipzig after his habilitation. He soon became an associate professor in 1746, at age 27. In 1751 he was elected a member of the Royal Swedish Academy of Sciences, which have famous fellows such as Isaac Newton, Charles Darwin, Alan Turing, Stephen Hawking, etc. In 1756, at his 37, he took up a position as full professor of natural philosophy and geometry at the University of Göttingen. His notable doctoral students include Johann Pfaff, who is the doctoral advisor of Carl Friedrich Gauss). Kästner died in 1800 in Göttingen, at age 81.
Kästner has numerous mathematical writings, including Anfangsgründe der Mathematik (“Foundations of Mathematics”) (Göttingen 1758-69, 4 volumes; 6th edition 1800) and Geschichte der Mathematik (“History of Mathematics”) (Göttingen 1796-1800, 4 volumes). Geschichte der Mathematik is considered an astute work, but lacks a comprehensive overview of all subsections of mathematics. Besides his contribution in math, he is more well-known for his poems, which were notable for their biting humour and sharp irony on different contemporary personalities.
As his descendants, we know Kästner as a talented scholar and devoted researcher in mathematics, philosophy, logic and law. His rich contributions shall be remembered the same as himself.