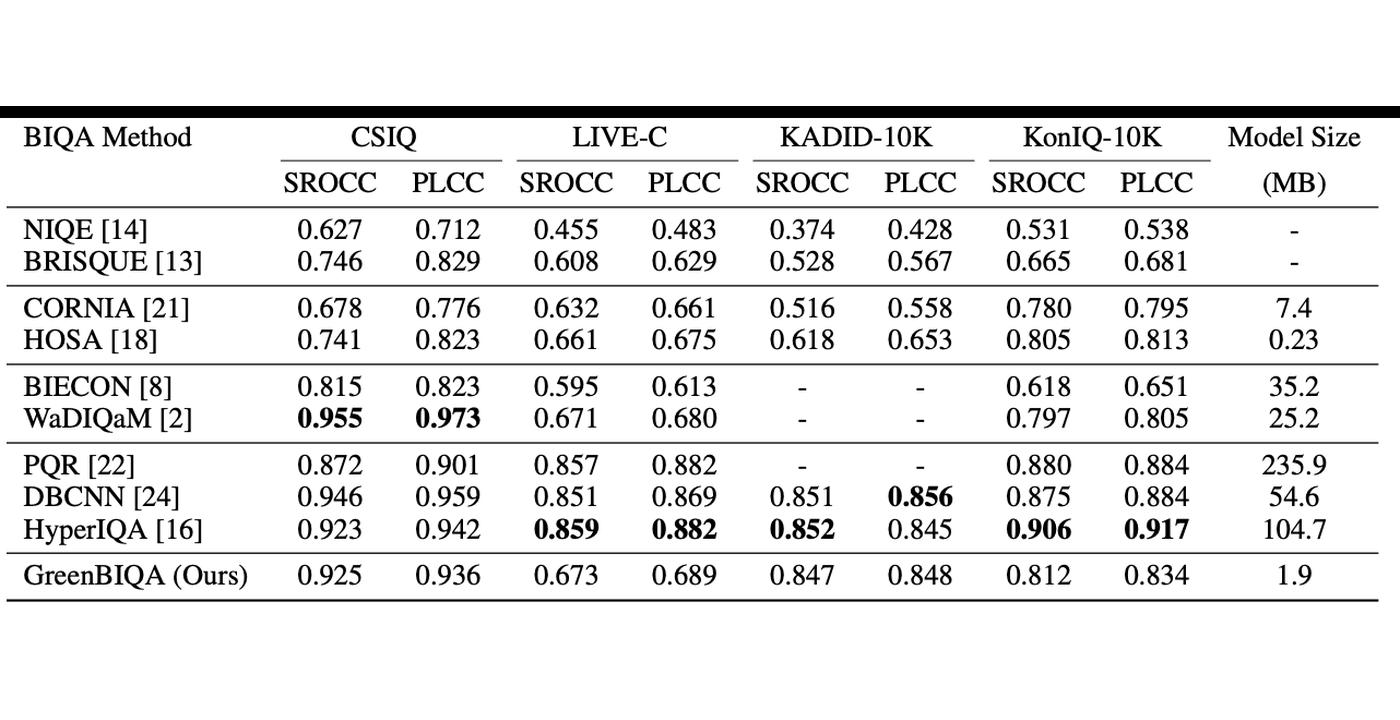
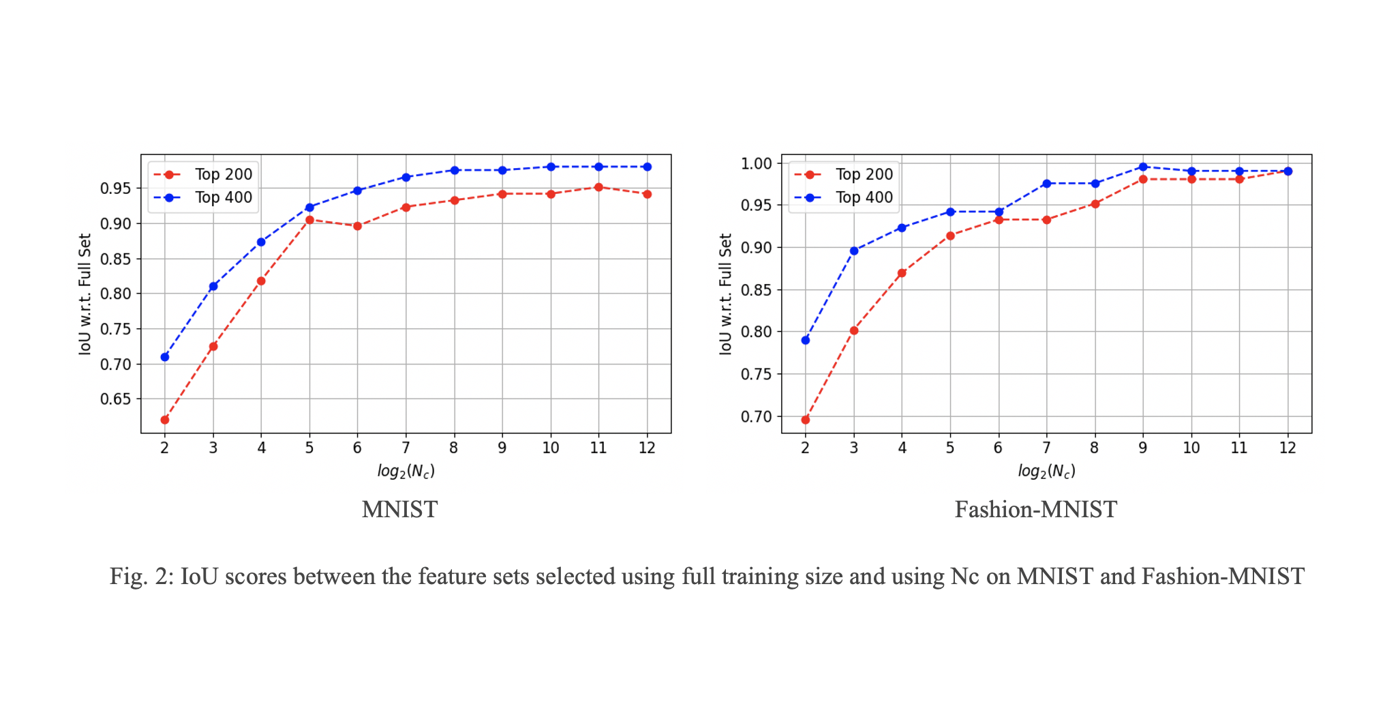
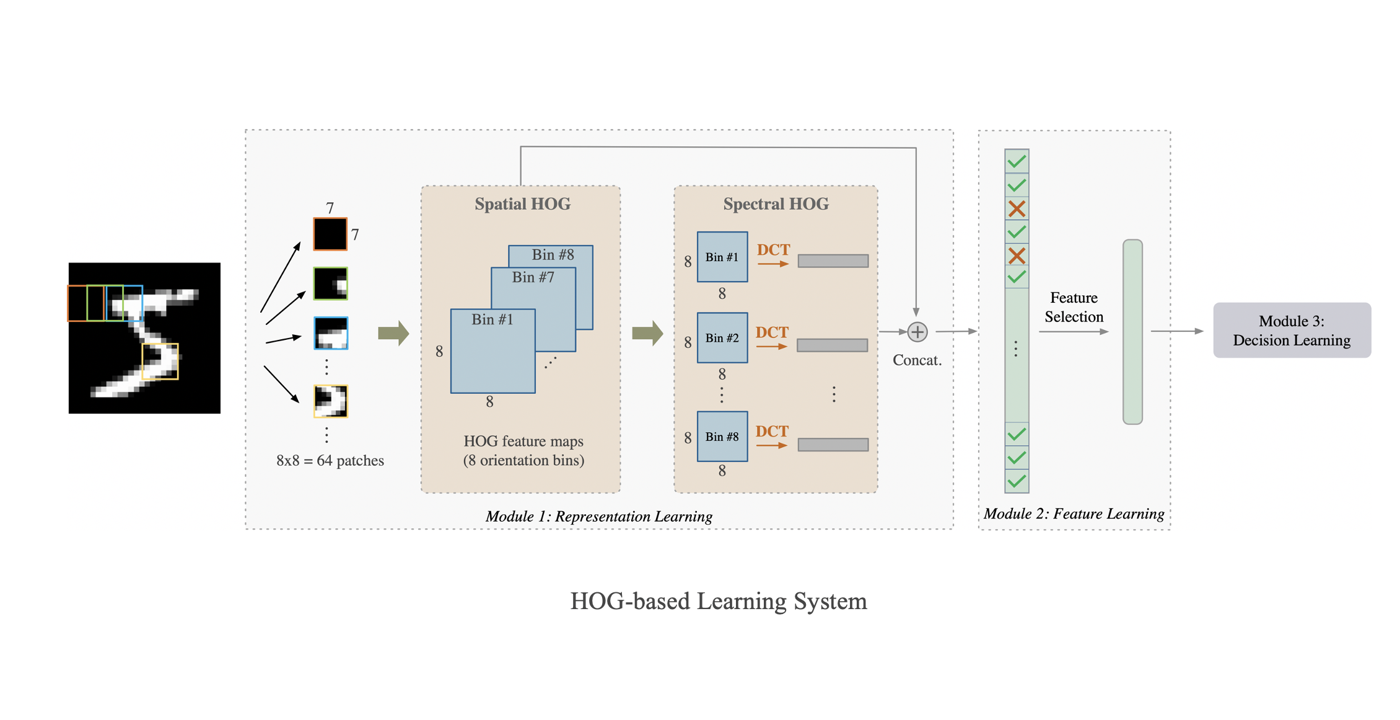
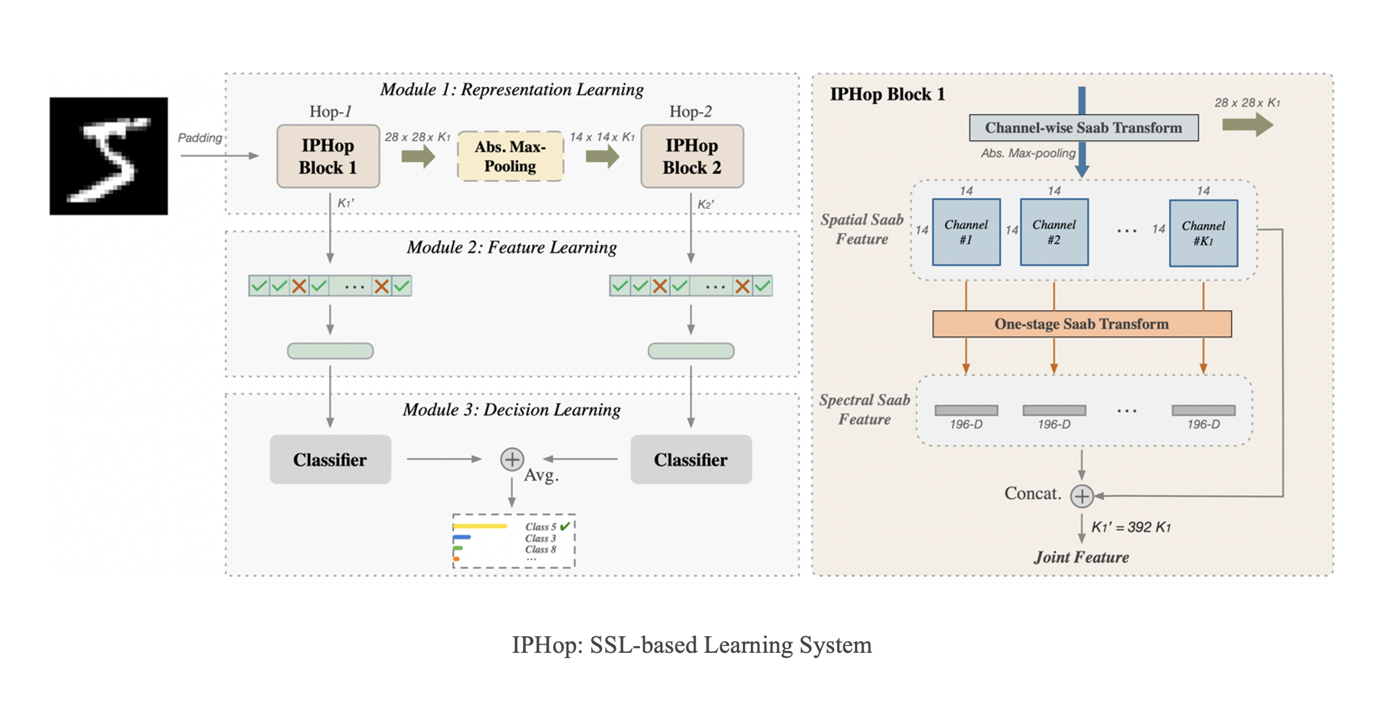
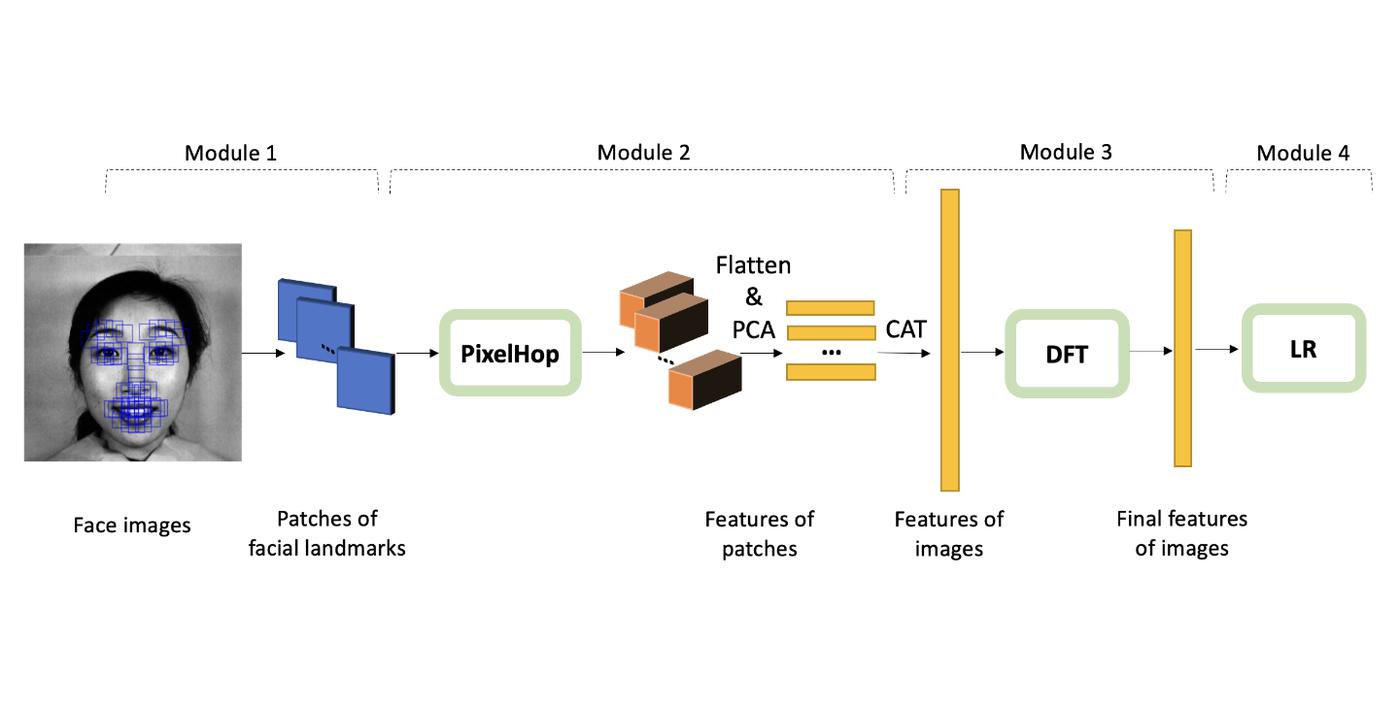
Welcome Aolin Feng to Join MCL as a new PhD student
We are so happy to welcome a new graduate member of MCL, Aolin Feng. Here is an interview with Aolin:
Could you briefly introduce yourself and your research interests?
My name is Aolin Feng. I received my bachelor’s and master’s degrees from University of Science and Technology of China (USTC). I developed my research interest in video compression when pursuing master’s degree. I join USC MCL lab to do further research in image/video processing-related area.
What is your impression about MCL and USC?
My impression about MCL lab is that it is such a big family. The atmosphere here is kind of serious but lively – people here are serious about academics but lively in life. Professor Kuo leads a lab full of creativity and passion. For USC, I like the campus, which is beautiful and has its own style. The culture here is diverse and the people I met are all friendly. I look forward to the study and life at USC.
What is your future expectation and plan in MCL?
I expect to broaden my research horizons and explore more interesting and cutting-edge directions. I wish I could learn a lot from Professor Kuo and the students in the lab. Besides, I wish to strengthen my mathematical foundation from course study and research.