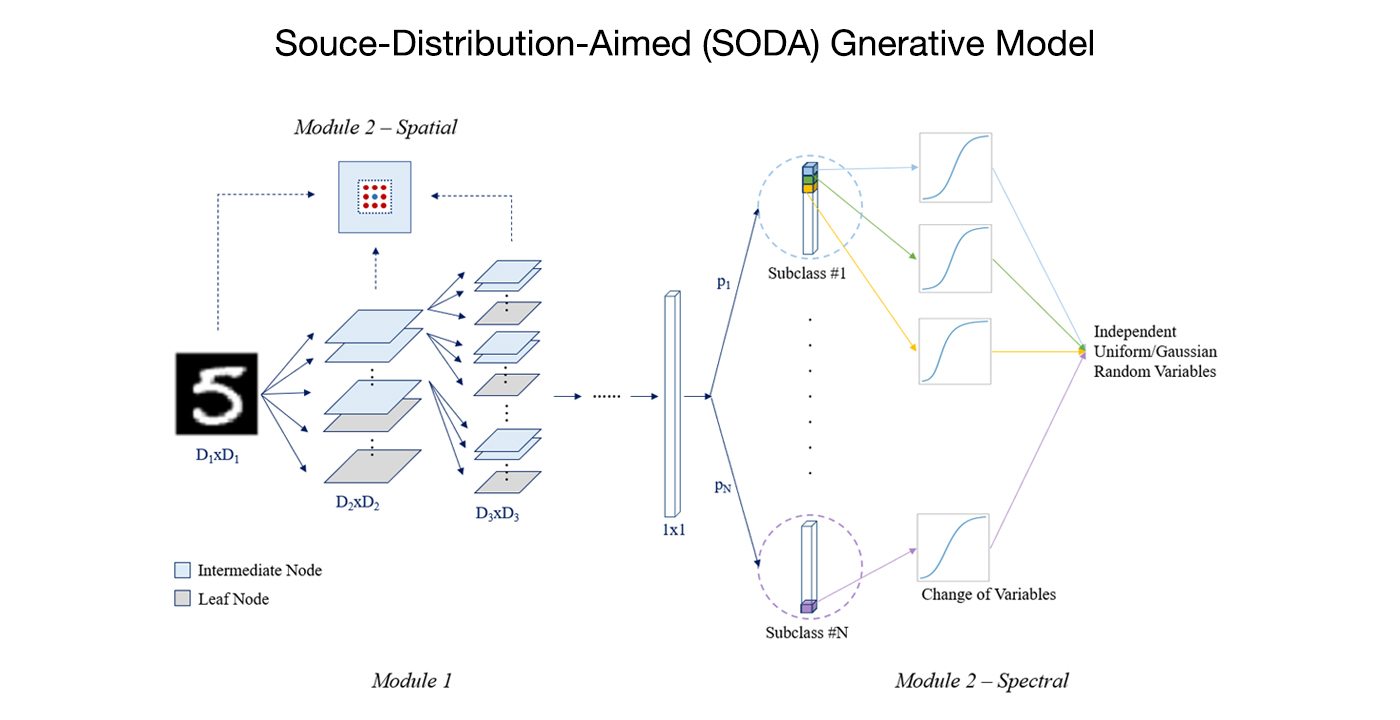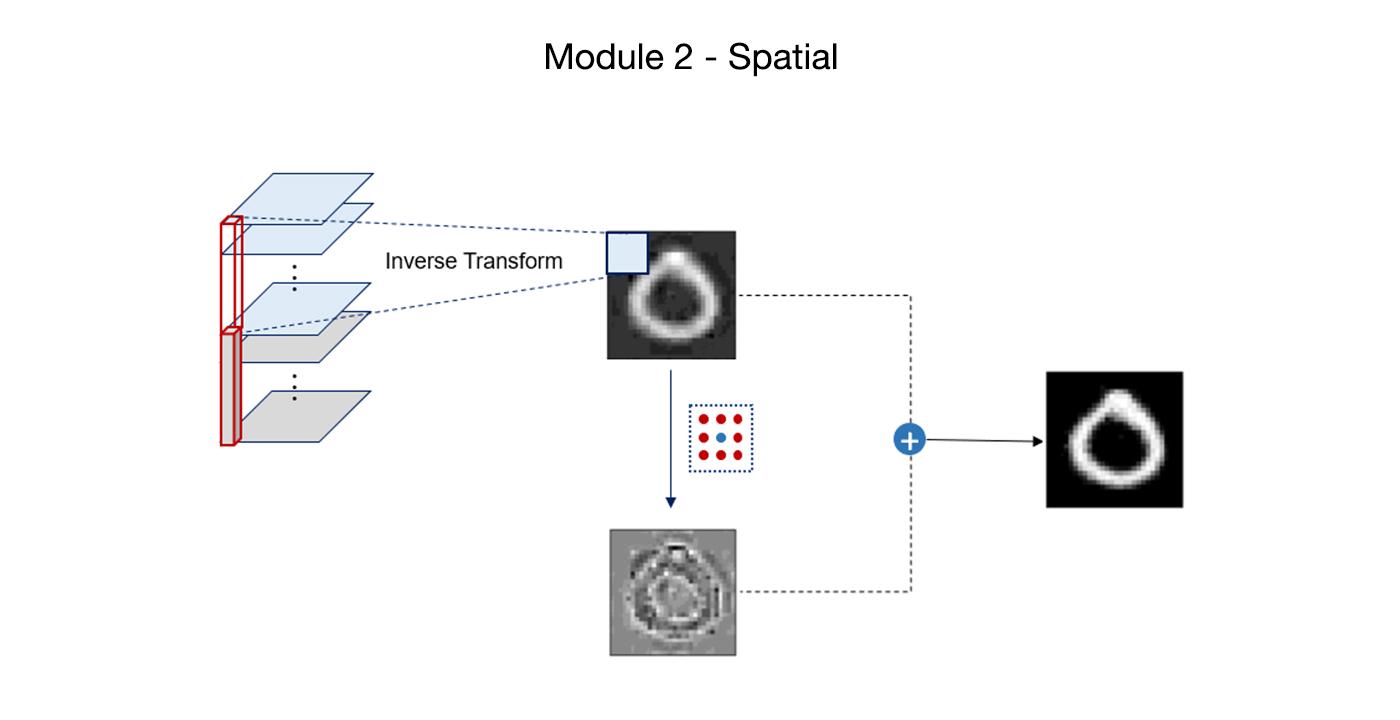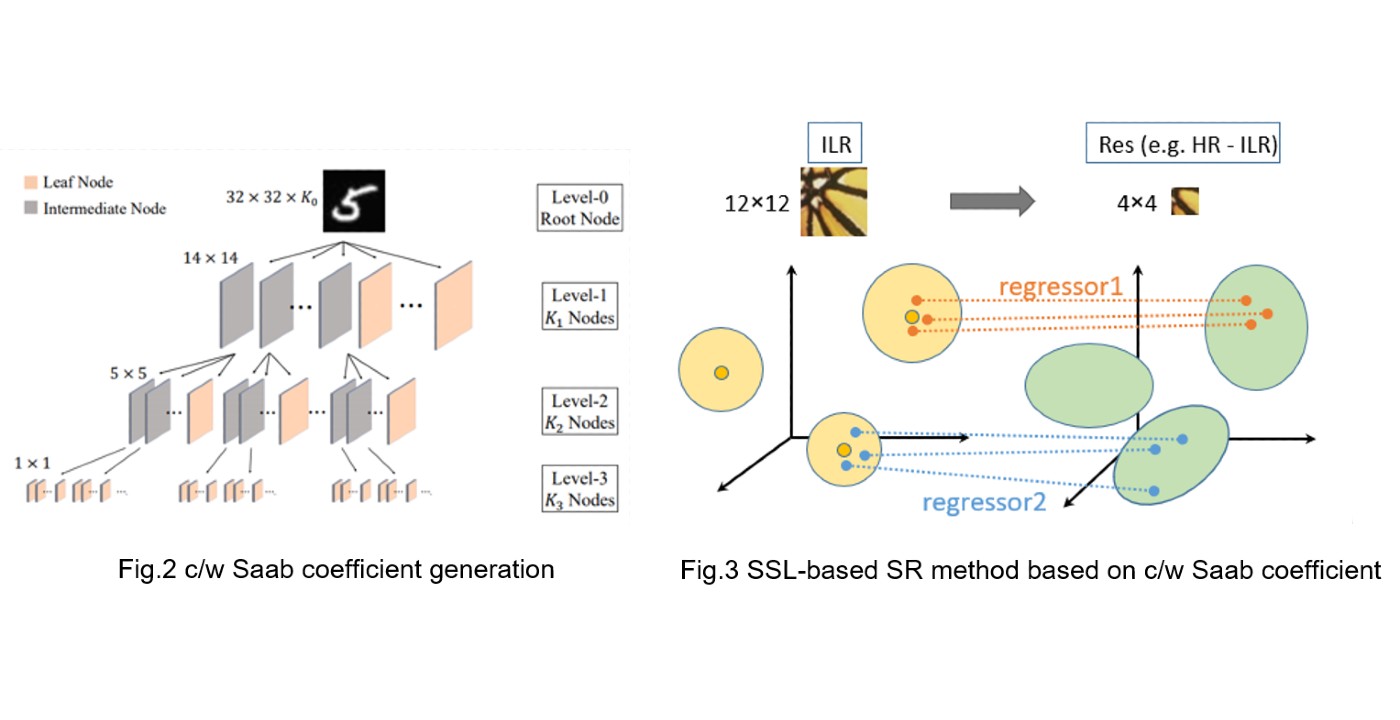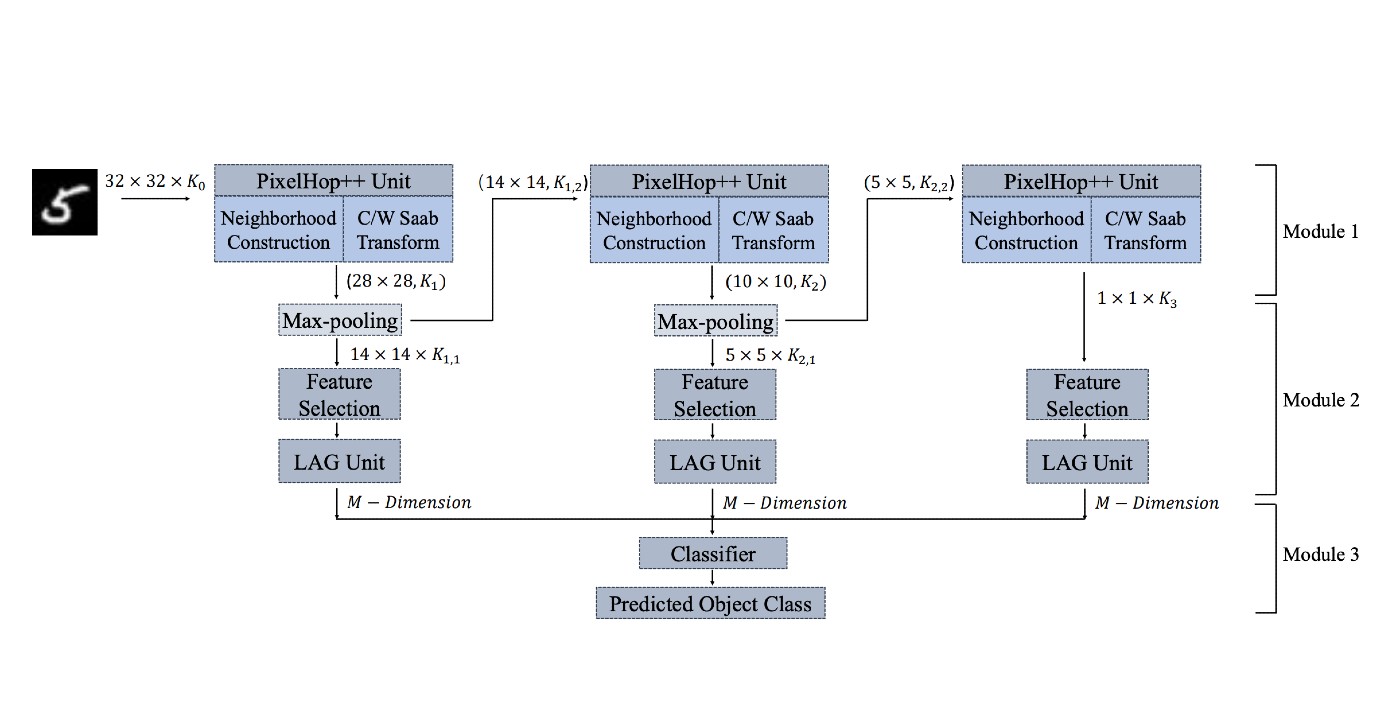

MCL Research on Point-Cloud-based 3D Scene Flow Estimation
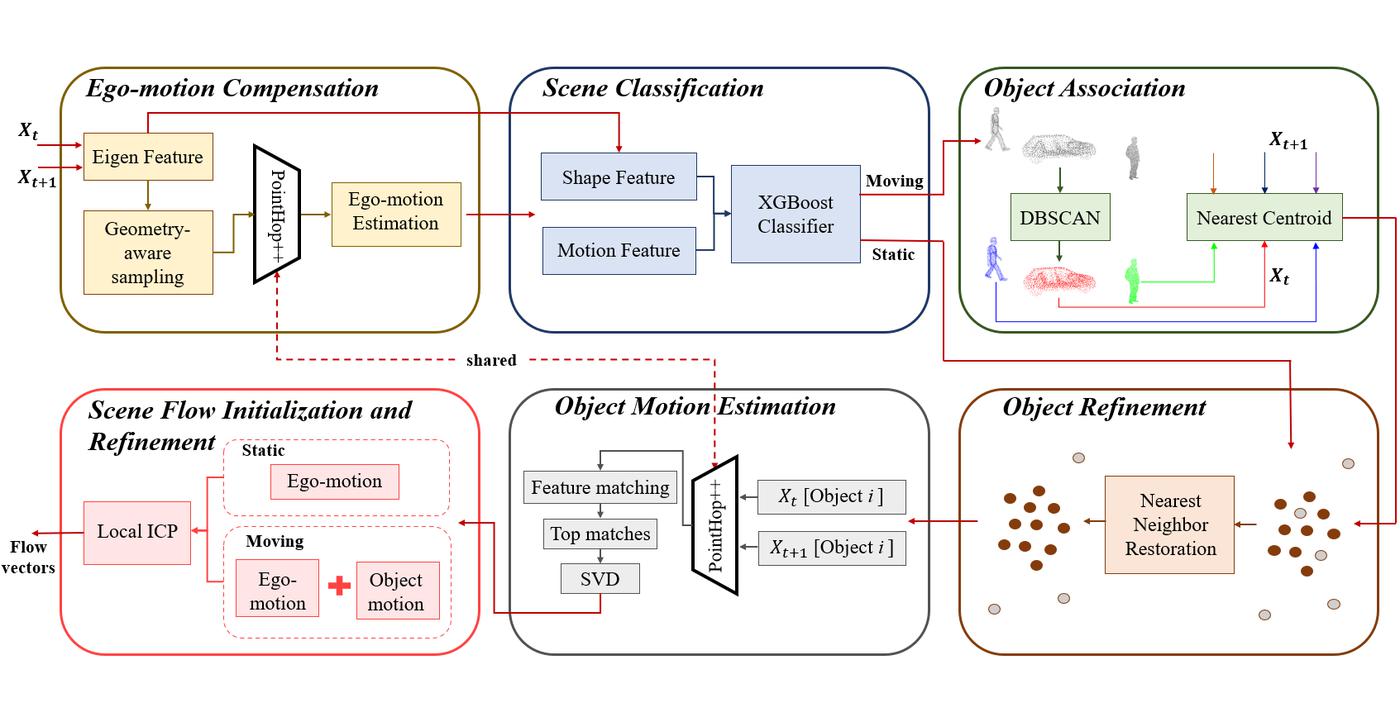
3D scene flow aims at finding the point-wise 3D displacement between consecutive point cloud scans. It finds applications in areas such as dynamic scene segmentation and may also guide inter-prediction in compression of dynamically acquired point clouds. We propose a green and interpretable 3D scene flow estimation method for the autonomous driving scenario and name it “PointFlowHop” [1]. We decompose our solution into vehicle ego-motion and object motion components.
The vehicle ego-motion is first compensated using the GreenPCO method which was recently proposed for the task of point cloud odometry estimation. Then, we divide the scene points into two classes – static and moving. The static points do not have any motion and can be assigned only the ego-motion component. The motion of the moving points is analyzed later. For classification, we use a lightweight XGBoost classifier with a 5-dimensional shape and motion feature as the input. Later, moving points are grouped into moving objects using DBSCAN clustering algorithm. Furthermore, the moving objects from the two point clouds are associated using the nearest centroids algorithm. An additional refinement step ensures reclassification of previously misclassified moving points. A rigid flow model is established for each object. Finally, the flow in local regions is refined assuming local scene rigidity.
PointFlowHop method adopts the green learning (GL) paradigm. The task-agnostic nature of the feature learning process in GL enables scene flow estimation through seamless modification and extension of prior related GL methods like R-PointHop and GreenPCO. Furthermore, a large number of operations in PointFlowHop are not performed during training. The ego-motion and object-level motion is optimized in inference only. Similarly, the moving points are grouped into objects only during inference. This makes the training process much faster [...]